AI开发文档
产品简介
上海电气AI建模平台
上海电气AI建模平台采用拖拉拽、自由组合、无代码的建模方式覆盖从数据接入-数据标注-模型开发-模型训练-部署发布-模型反馈的模型全生命周期,帮助用户快速低成本构建模型应用,满足多种AI应用场景的快速应用。
产品界面
产品优势
兼容多种数据
支持KAFKA、hive、hbase和HDFS等数据库接入,支持流式数据、图像数据等数据格式。
图形化拖拽
无需写代码即可通过可视化的图形界面,将不同模块组件通过拖拽即可串联完成模型的开发。
多种场景的全自动模型训练
支持自动化建模筛选最优模型,一键发布服务,快速应用在实际业务中。
NoteBook
提供业界主流的Notebook的在线方案, 用户可自由编码在线进行模型开发。
多人协作共同开发
开发环境支持多人协作,可以邀请好友或同事共同进行项目研发。支持模型分享、模型复制等协作功能。
业务价值
1. 内置光伏、风电、石油石化、机床、产线等多种行业成熟模型模板快速应用。
2. 拖拽式建模、自动化建模、nootbook等建模方式满足不同层级用户使用,用户可根据自身数据,创建贴合自身业务的模型,实现模型多种场景应用。
3. 图像识别、文本分析等一站式开发环境,提升开发效率。
4. 开放API接口,与算法应用业务平台无缝对接,支持模型AB测试在线自动优化。
基本操作
整体界面功能
 整体设计为顶部导航栏、左侧导航栏、面包屑、内容板块。
整体设计为顶部导航栏、左侧导航栏、面包屑、内容板块。
顶部导航

1.左上角上海电气logo。
2.用户所属公司。
3.界面颜色切换。
4.消息入口。
5.个人资料入口。
左侧导航
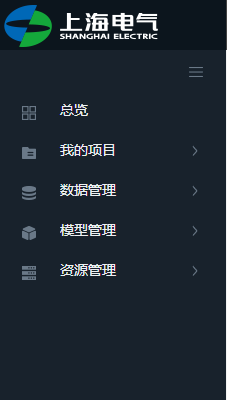
1.导航栏可展开折叠。
2.以任何角色登录系统,看到的侧边栏导航内容都一致,显示:总览、我的项目、数据管理、模型管理、资源管理、模型市场和Dashboard。
3.我的项目子菜单:查看所有项目和最新创建的3个项目,点击查看所有项目跳转至项目列表页。
4.数据管理子菜单:数据源同步、映射规则、故障数据,点击子菜单执行跳转动作,跳转到各自对应的页面。
5.模型管理子菜单:新建模型、模型发布及部署、已部署模型及预警、模型申请管理,点击子菜单执行跳转动作,跳转到各自对应的页面。
6.资源管理子菜单:资源配置管理,点击子菜单执行跳转动作,跳转到资源管理页面。
7.模型市场子菜单:模型市场、个人模型库,点击子菜单执行跳转动作,跳转到各自对应的页面。
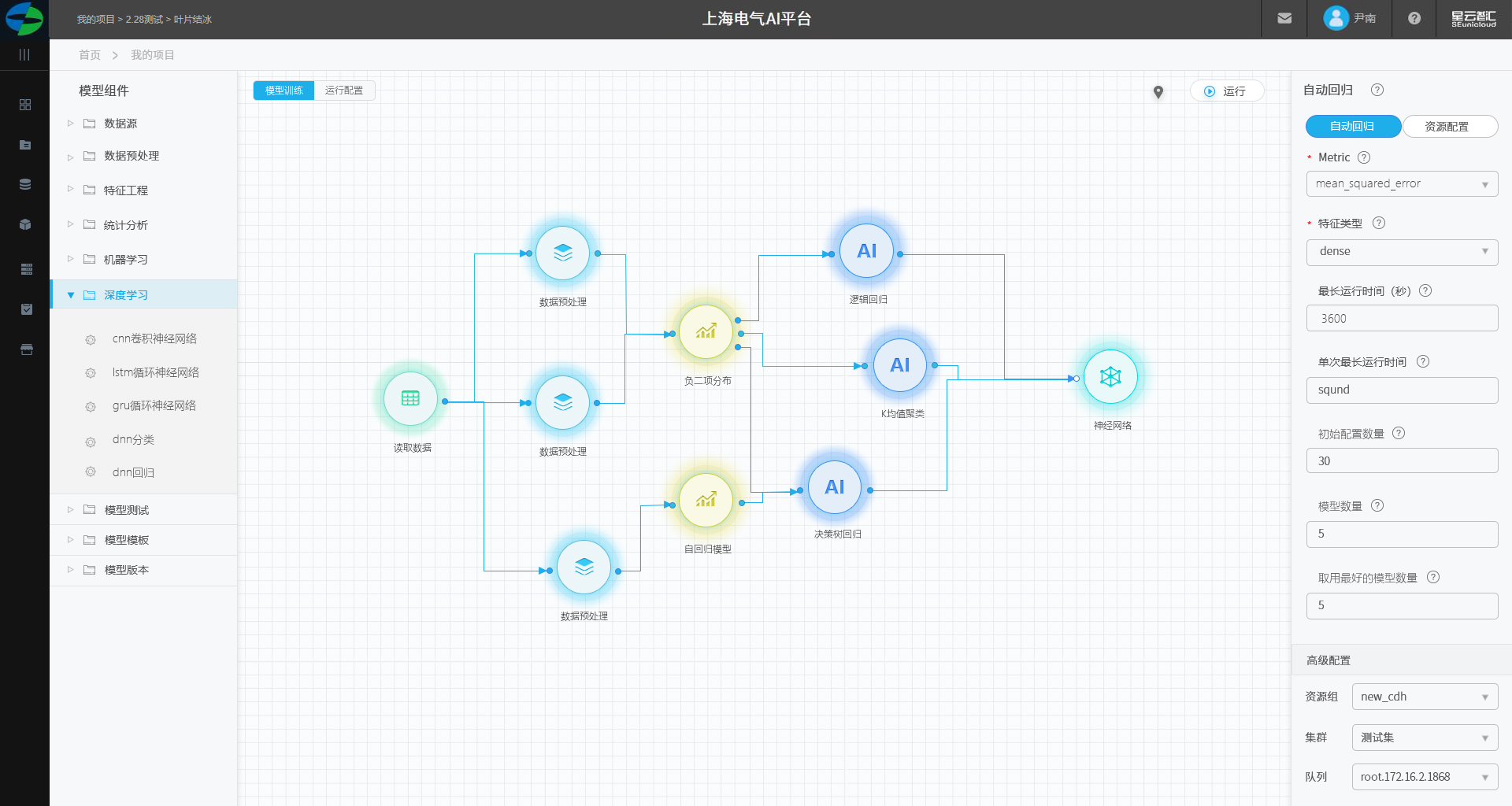
建模画板页面
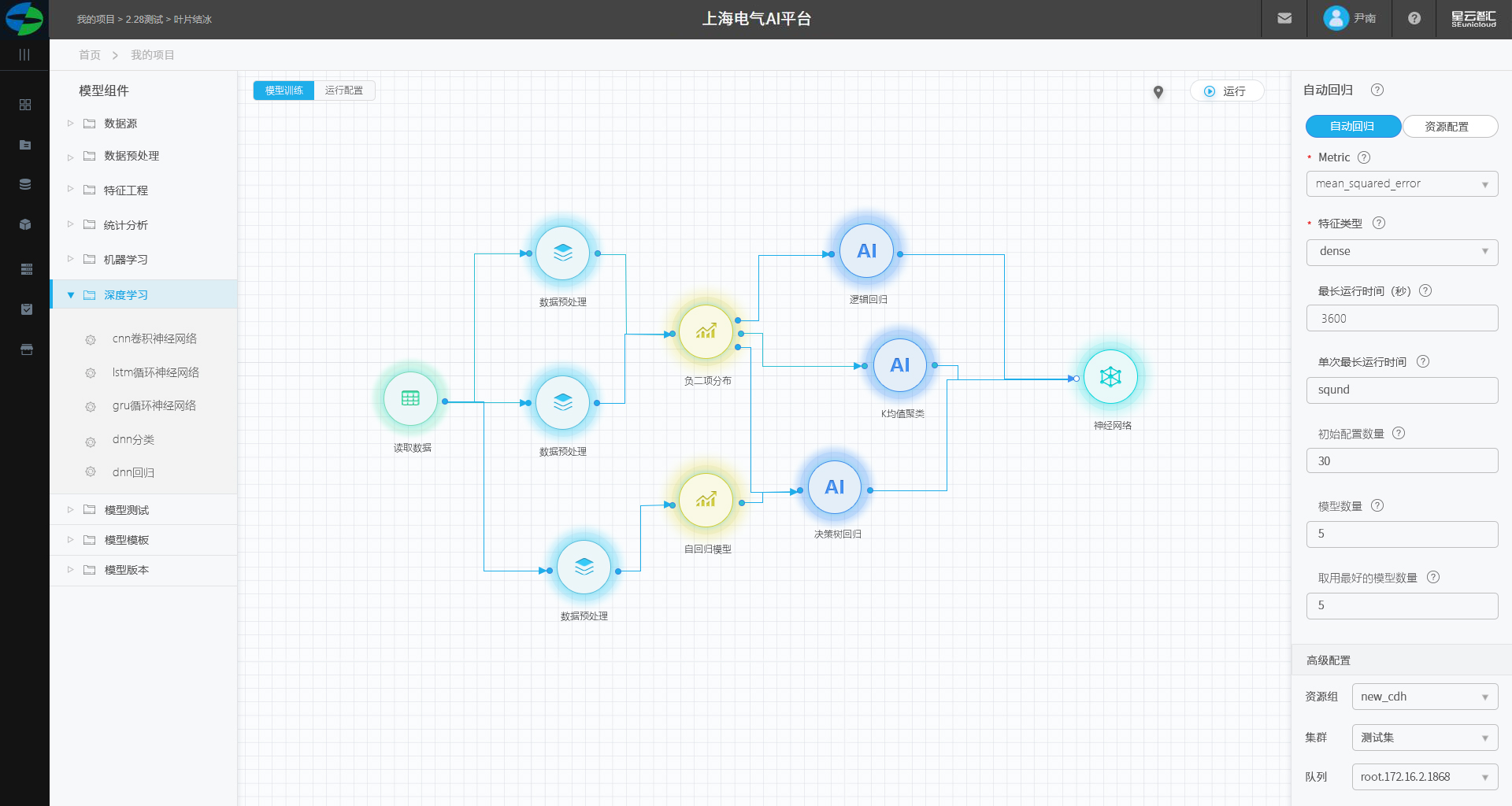
建模区分为组件区、画板区、配置区。
组件区
每个每一个执行逻辑都被封装成一个组件,组件按照功能属性进行分类。
画板区
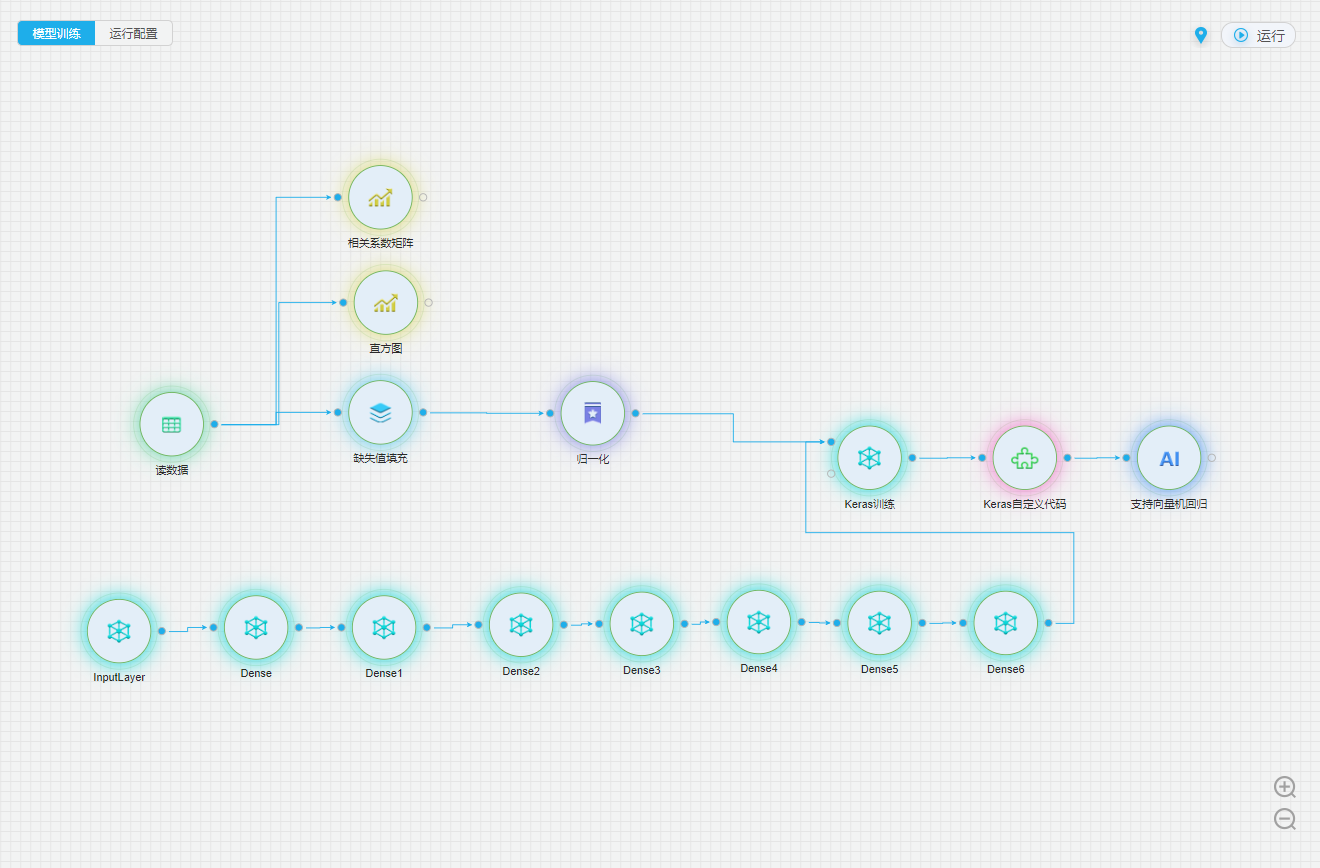
1.可将组件拖拽至中间画板区域,在页面上显示为一个圆形。
2.组件有输入和输出,通过在画布上连线来实现多个组件之间数联通与传输。
3.组件的四个概念:输入、输出、执行逻辑、参数。
4.输入:组件左侧的输入节点。
5.输出:组件右侧的输出节点。
6.可点击组件邮件进行运行组件。
参数配置区
参数:可以将执行逻辑中的参数展示出来,放在参数设置中,使用配置参数即可使用该组件。
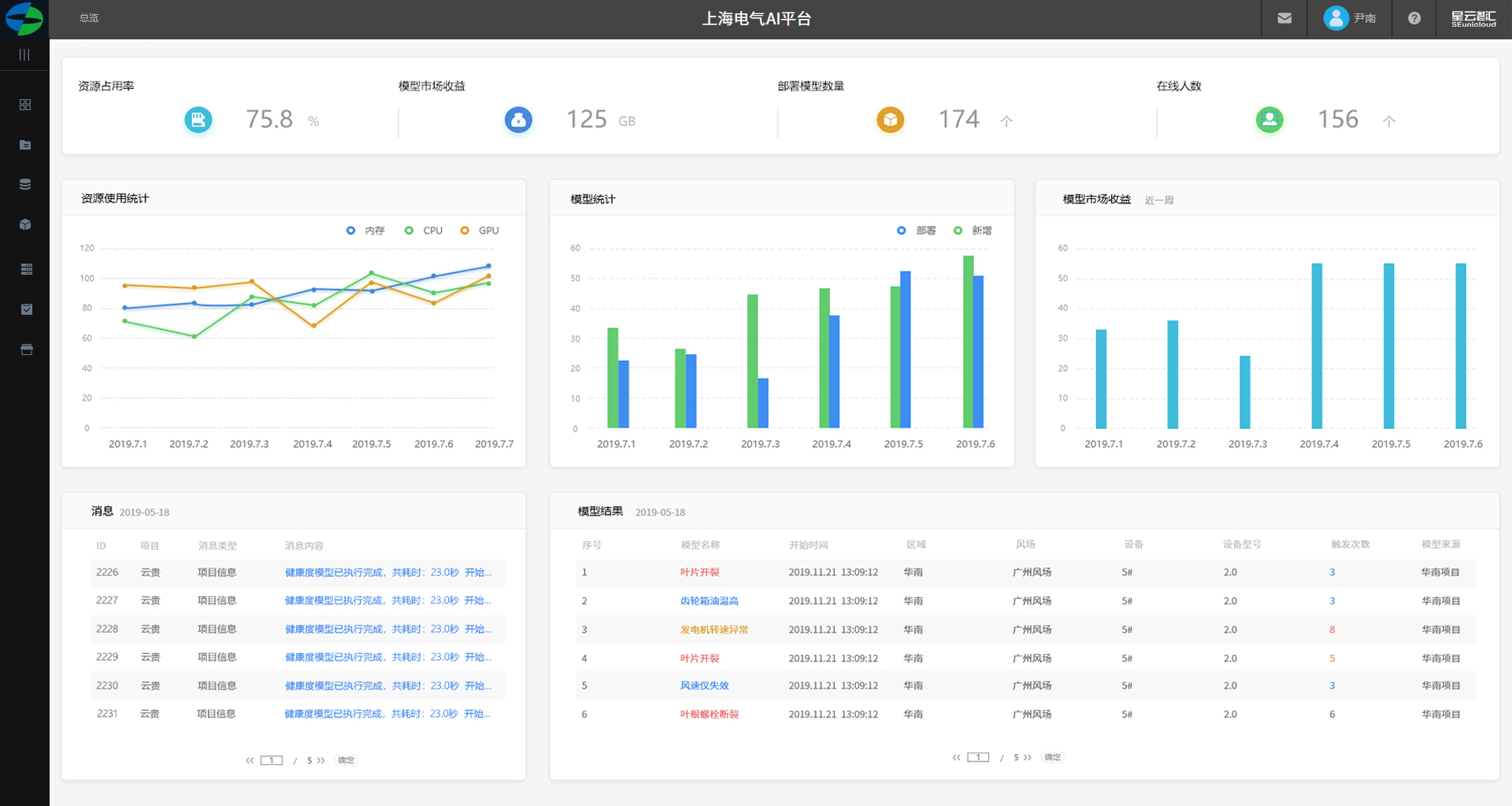
总览
顶部指标
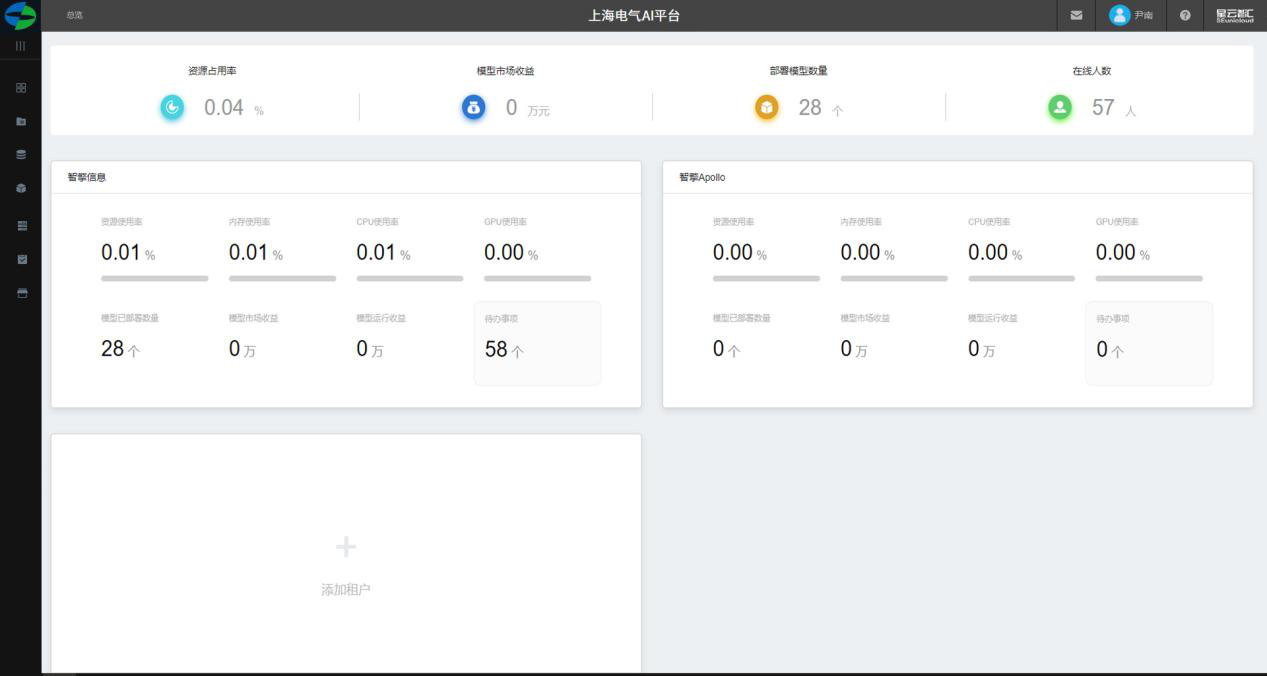

展示整个AI建模平台的各项数据包括:
1. 资源占用率 ,单位:%
1. 模型市场收益 ,单位:万元
1. 部署模型数量 ,单位:个
1. 在线人数 ,单位:个
中部板块
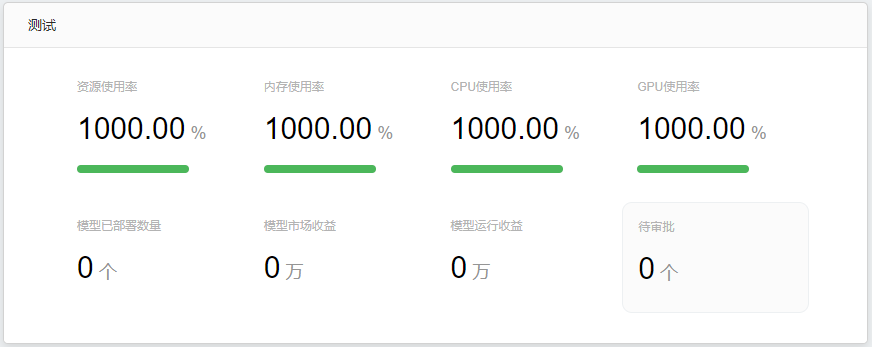
中部板块展示单个租户的资源使用情况。
添加租户
点击【添加租户】跳转到【租户管理员】界面。
租户管理员
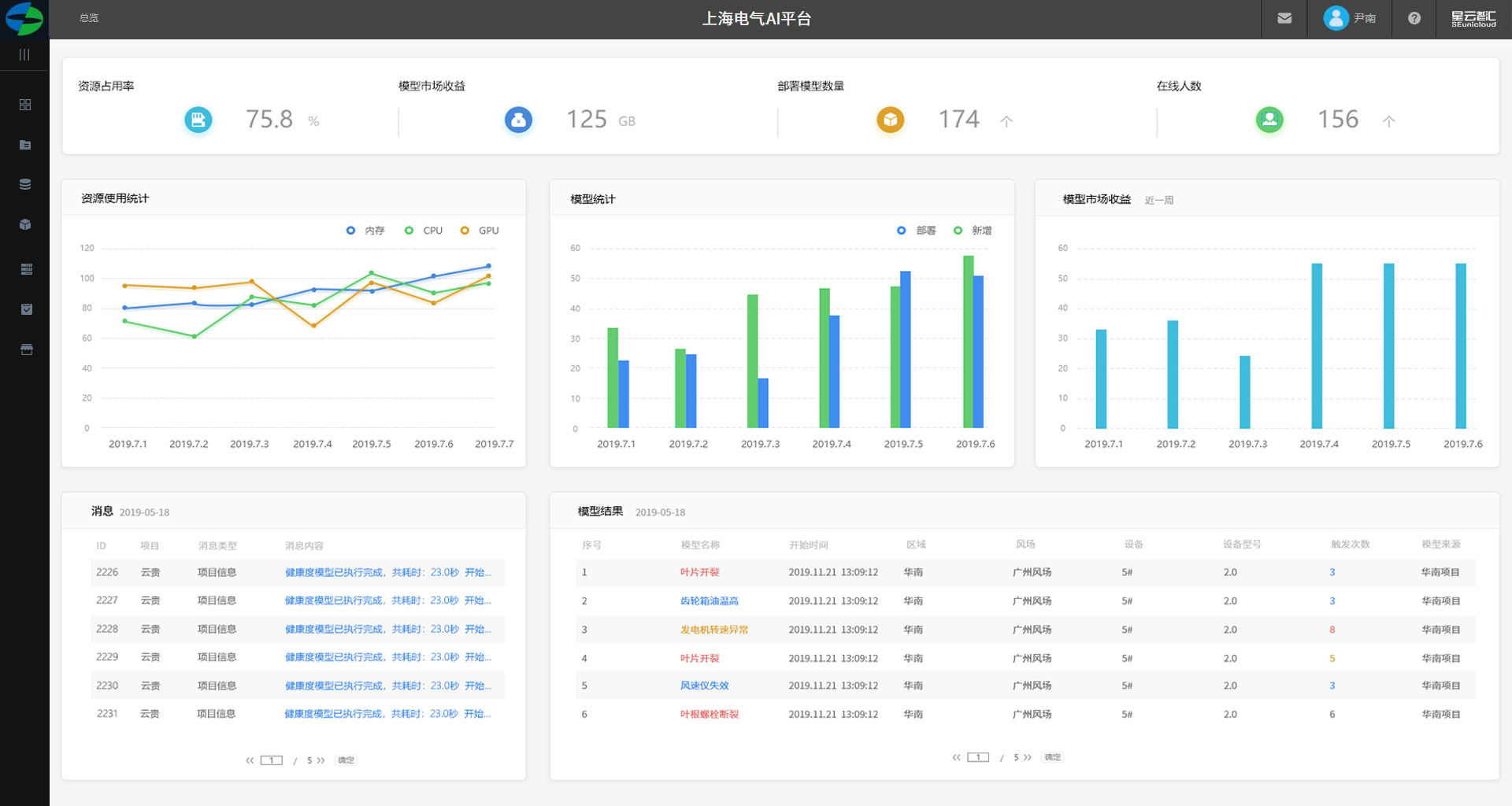
1.顶部展示:资源占用率、模型市场收益、部署模型数量、在线人数以总数展示。
2.以折线图资源使用统计包括:内存、CPU、GPU。
3.模型统计以柱图展示、部署模型及新增。
4.模型市场收益以柱图展示。
5.该租户消息列表。
6.模型运行结果。
用户
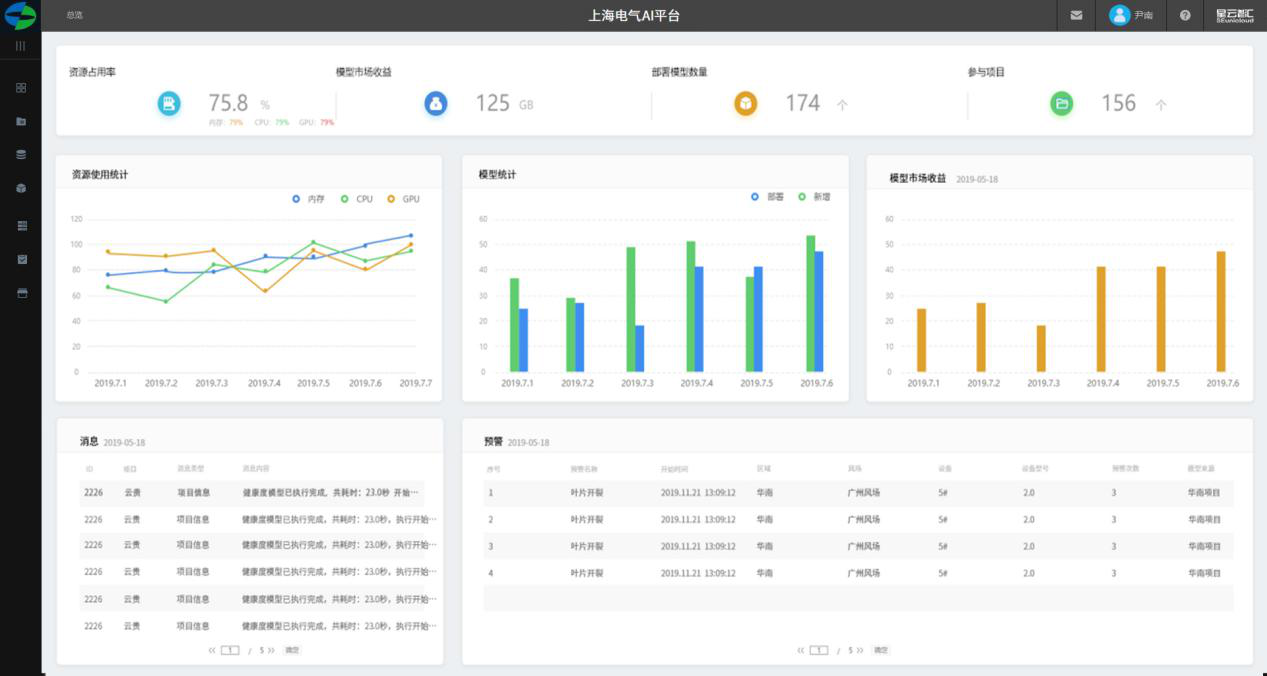
1.顶部展示:资源占用率、模型市场收益、部署模型数量、参与项目以总数展示。
2.以折线图资源使用统计包括:内存、CPU、GPU。
3.模型统计以柱图展示、部署模型及新增。
4.模型市场收益以柱图展示。
5.消息列表。
6.模型运行结果。
我的项目
查看所有项目
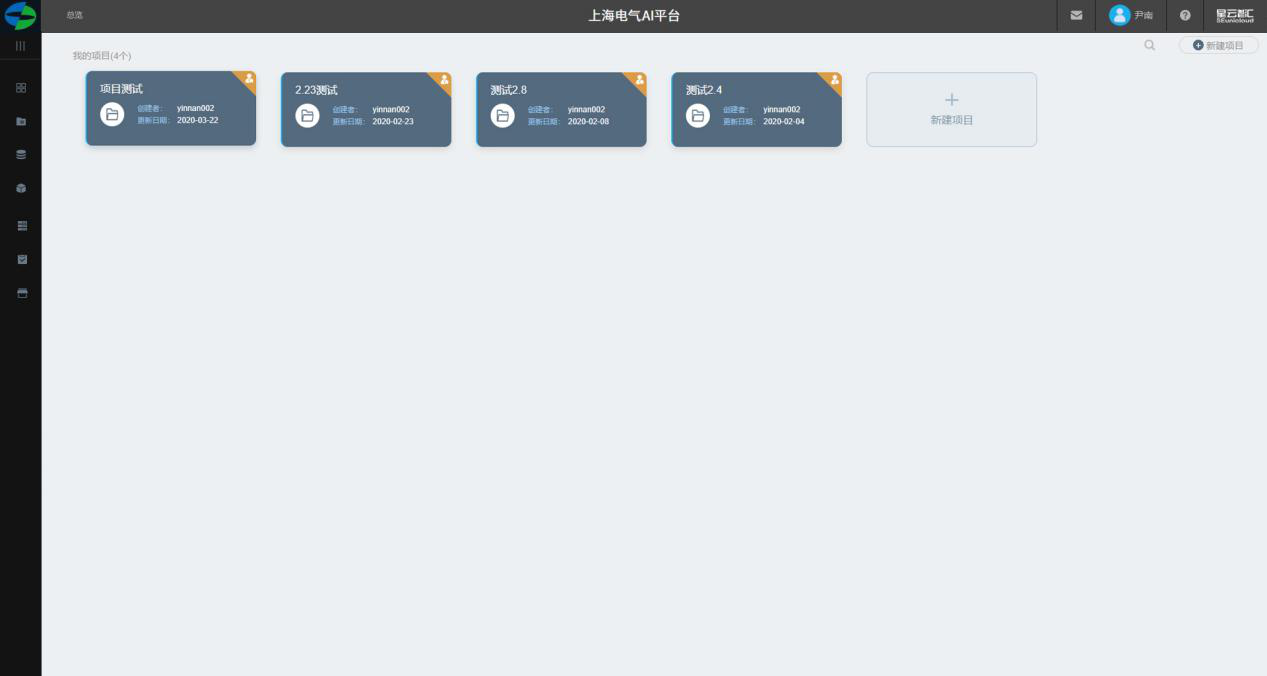
点击查看所有项目,可查看所有已参与的项目。
新建项目

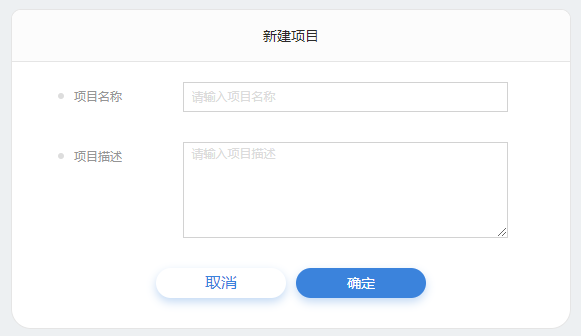
1.添加项目入口
2.添加项目名称,项目描述。
项目资产
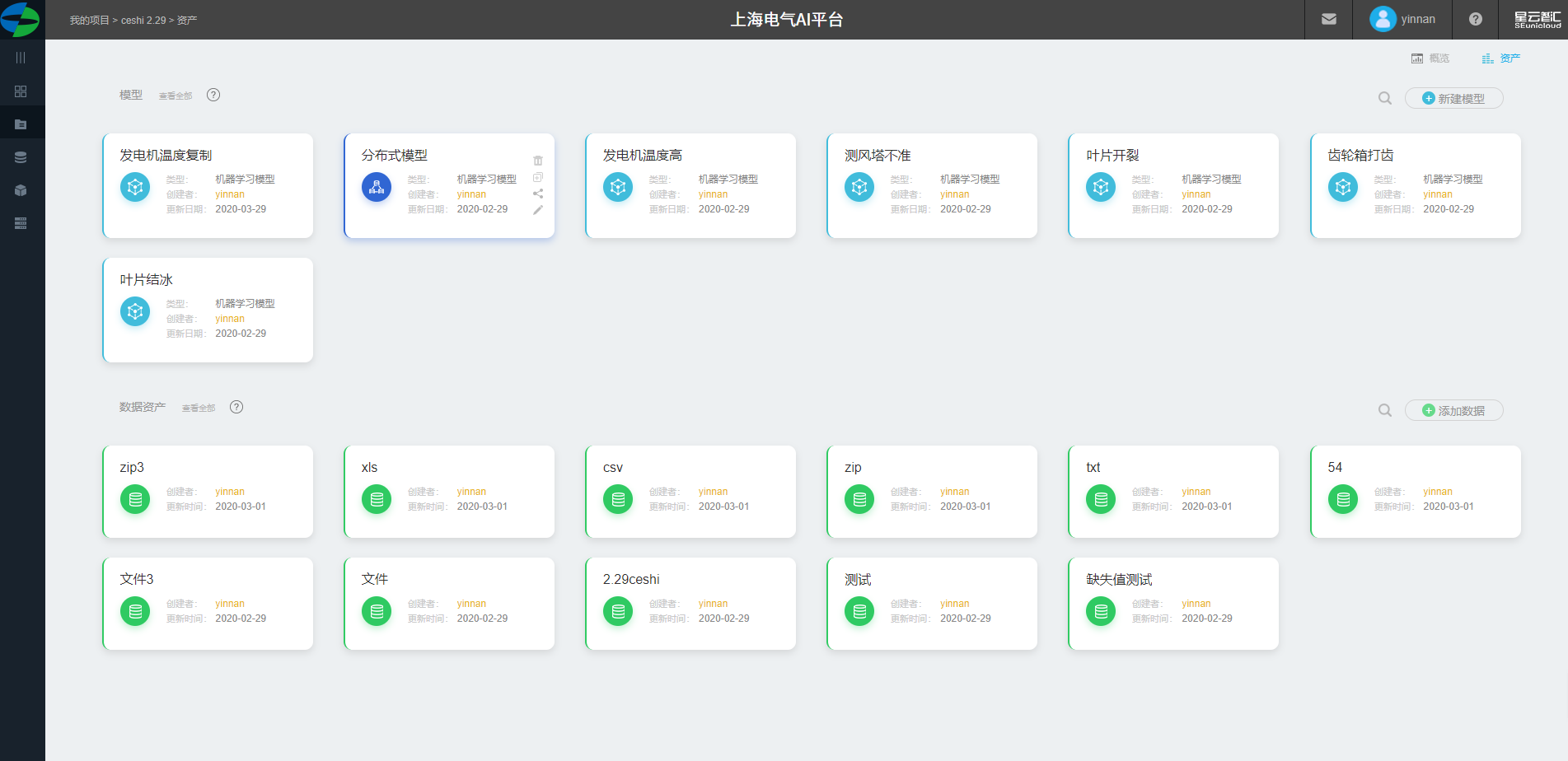
1.点击进入某个项目进入。
2.展示项目内已创建模型、上传的数据。
3.可添加模型和数据入口。
4.模型、数据多与一行(5个)进行自动折叠,可手动展开查看。
5.模型展示信息包括:模型名称、运行方式、更新时间、类型、版本号、项目名称、创建者。
6.数据展示信息包括:数据名称、类型、更新时间、创建者。
7.新建模型、数据入口。
8.模型删除、模型复制、模型分享、模型编辑入口。
上传数据资产
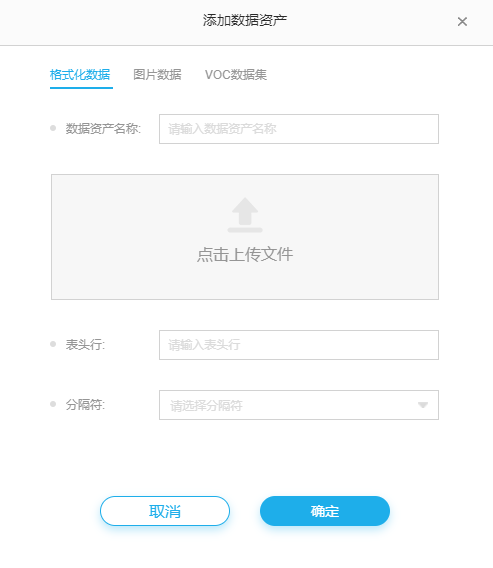
支持TXT、CSV、XLS、XLSX、ZIP、RAR等文件格式。
项目概览
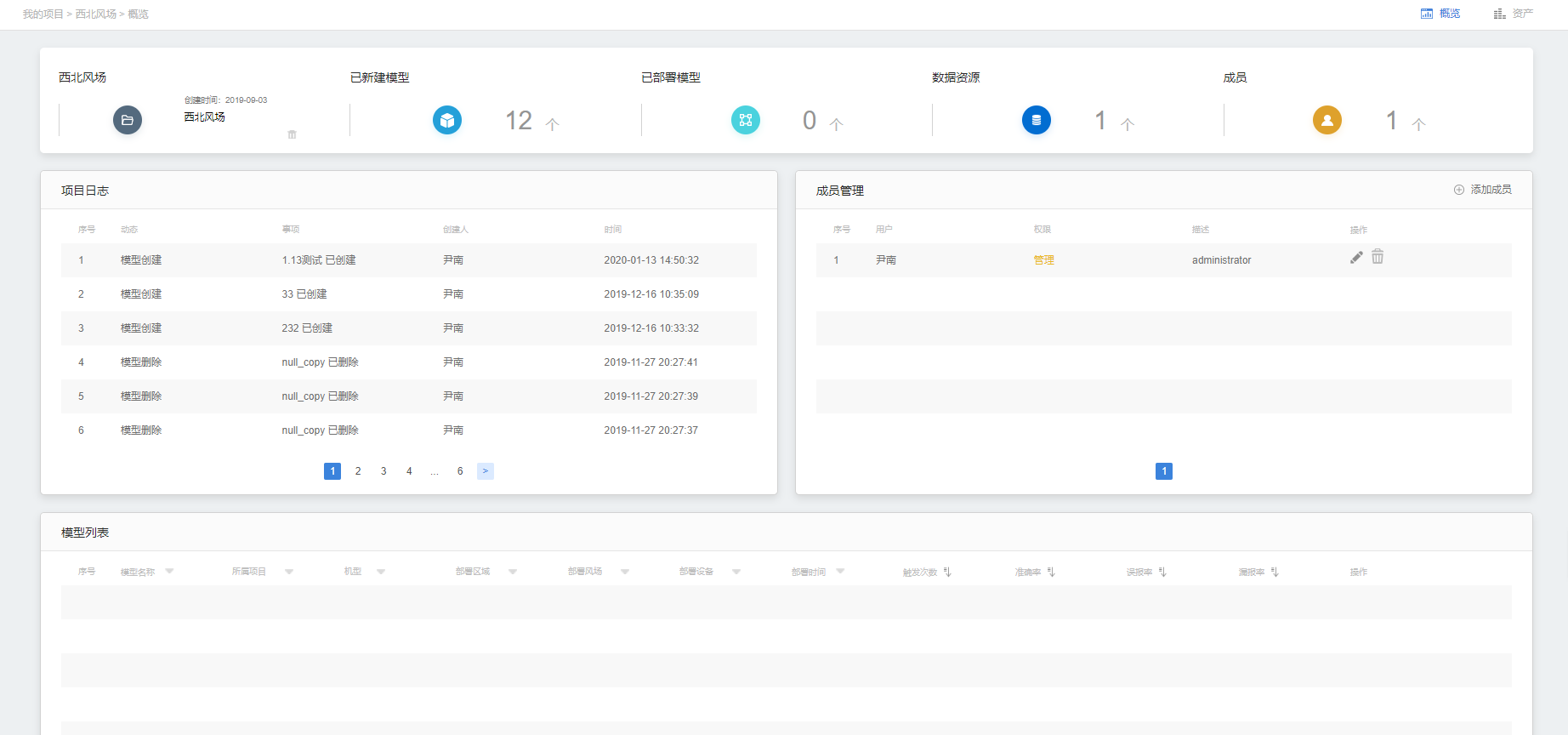
1.顶部展示:项目名称、项目资料。已创建模型、已部署模型、数据资源、项目成员以总数进行展示。
2.项目日志列表。
3.成员管理列表、添加成员入口、编辑成员项目权限、删除。
4.模型列表。
数据管理
同步数据源
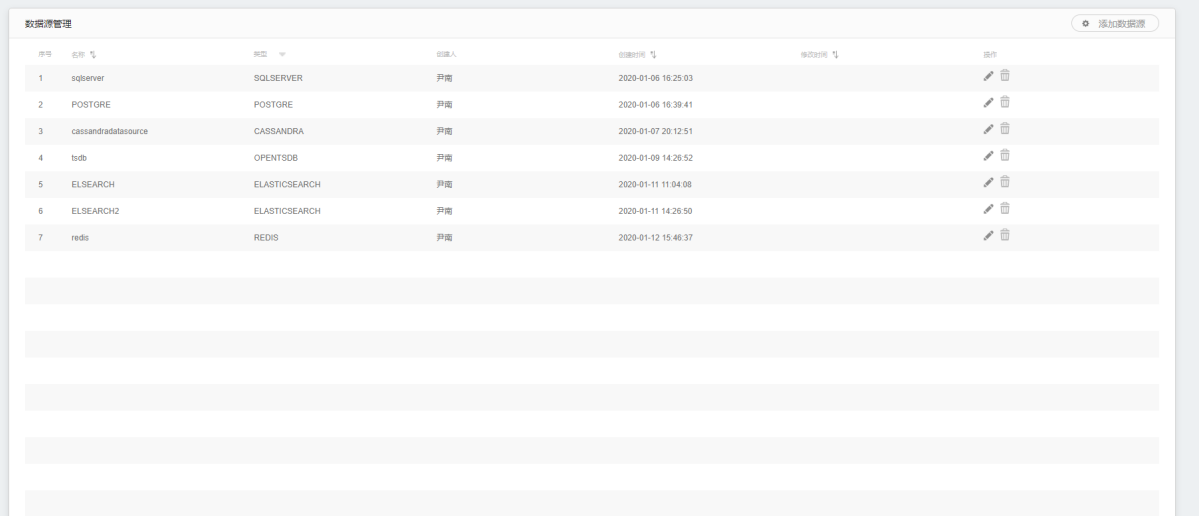
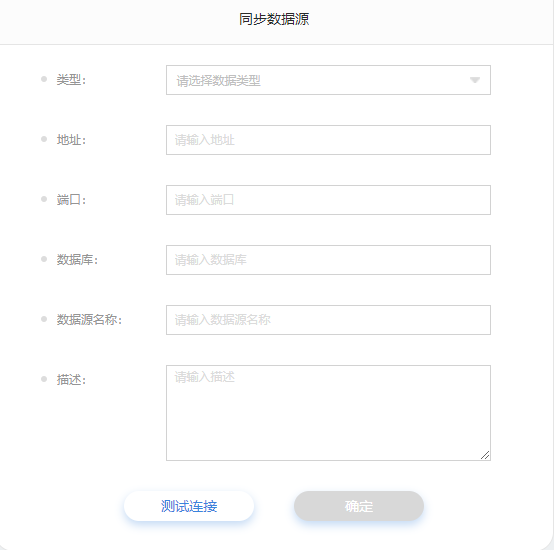
1.点击进入某个项目进入。
2.展示项目内已创建模型、上传的数据。
3.可添加模型和数据入口。
4.模型、数据多与一行(5个)进行自动折叠,可手动展开查看。
5.模型展示信息包括:模型名称、运行方式、更新时间、类型、版本号、项目名称、创建者。
6.数据展示信息包括:数据名称、类型、更新时间、创建者。
7.新建模型、数据入口。
8.模型删除、模型复制、模型分享、模型编辑入口。
模型管理
新建模型
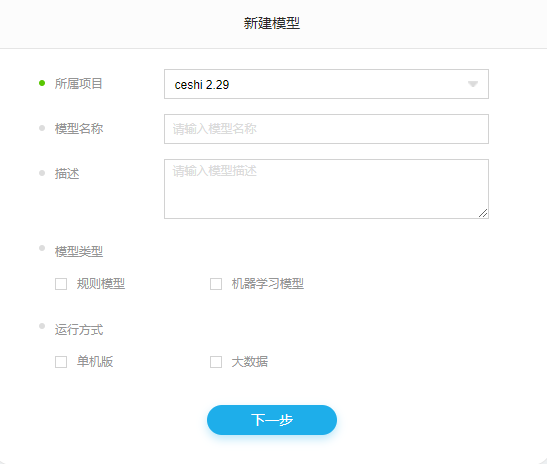
选择模型所属项目、模型名称、模型描述、模型运行方式(单机版、分布式版)、模型类型(规则模型、机器学习模型)。
模型发布及部署
在线部署
选择运行方式
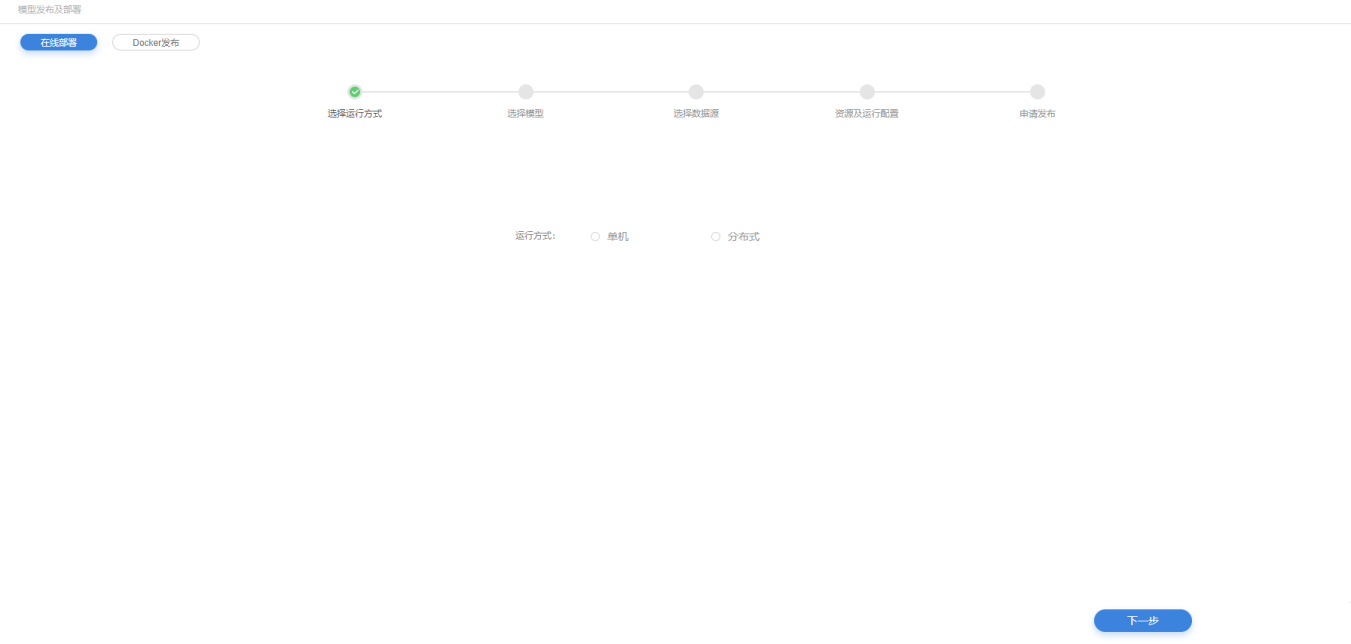
1.选择模型运行方式
选择模型
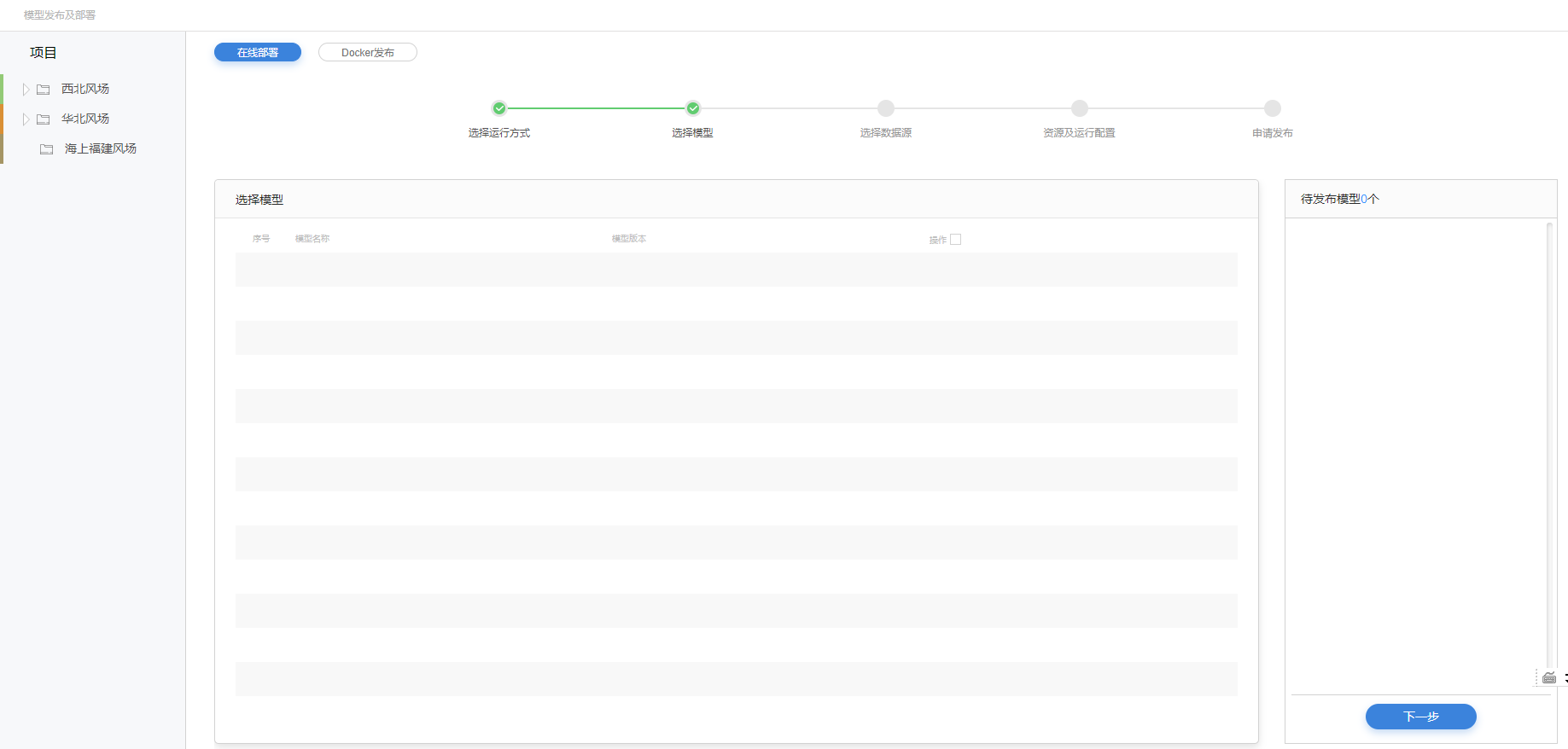
2.在权限范围项目内选择要发布的模型及不同的模型版本,支持多选。
选择数据
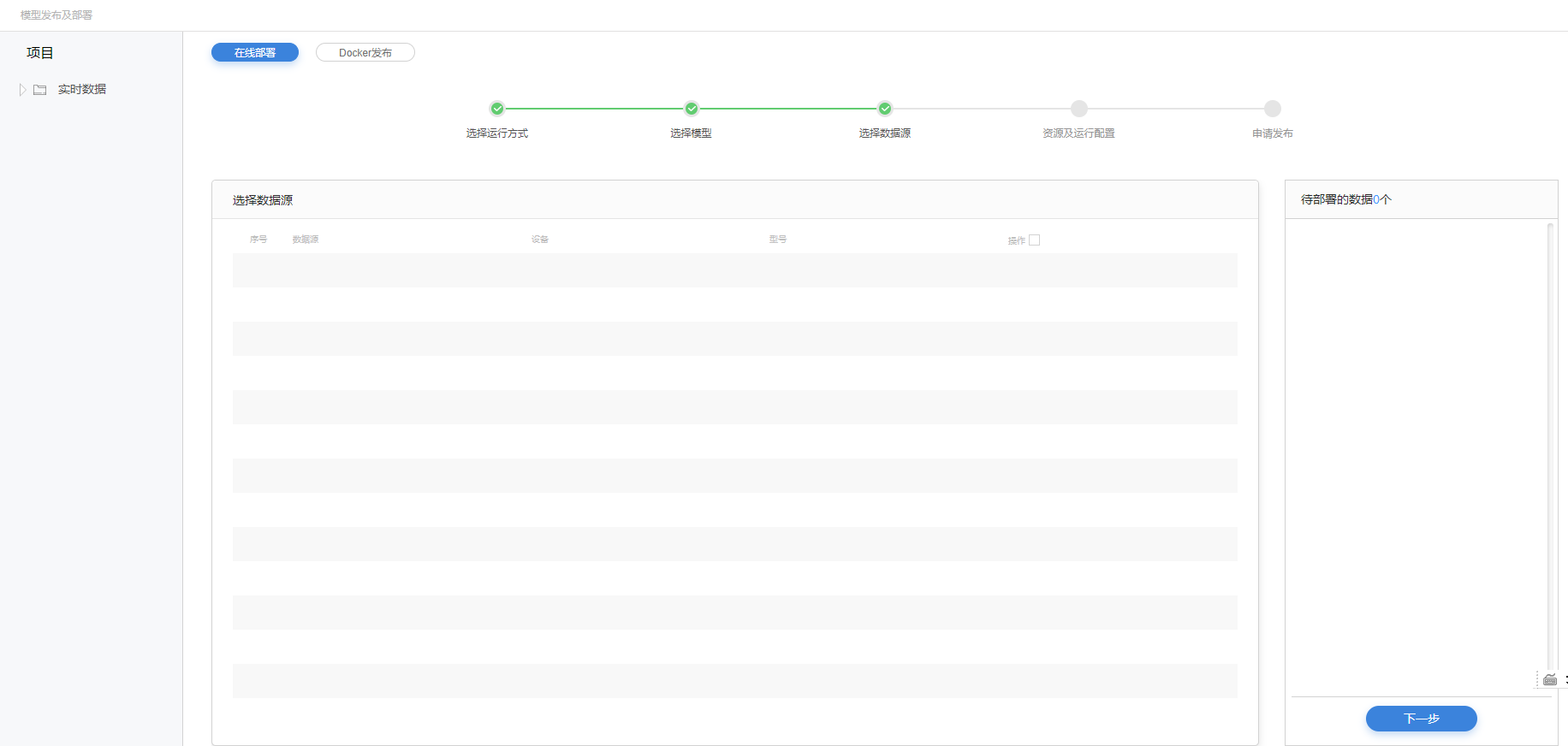
3.选择需要部署的实时数据。
资源及运行配置
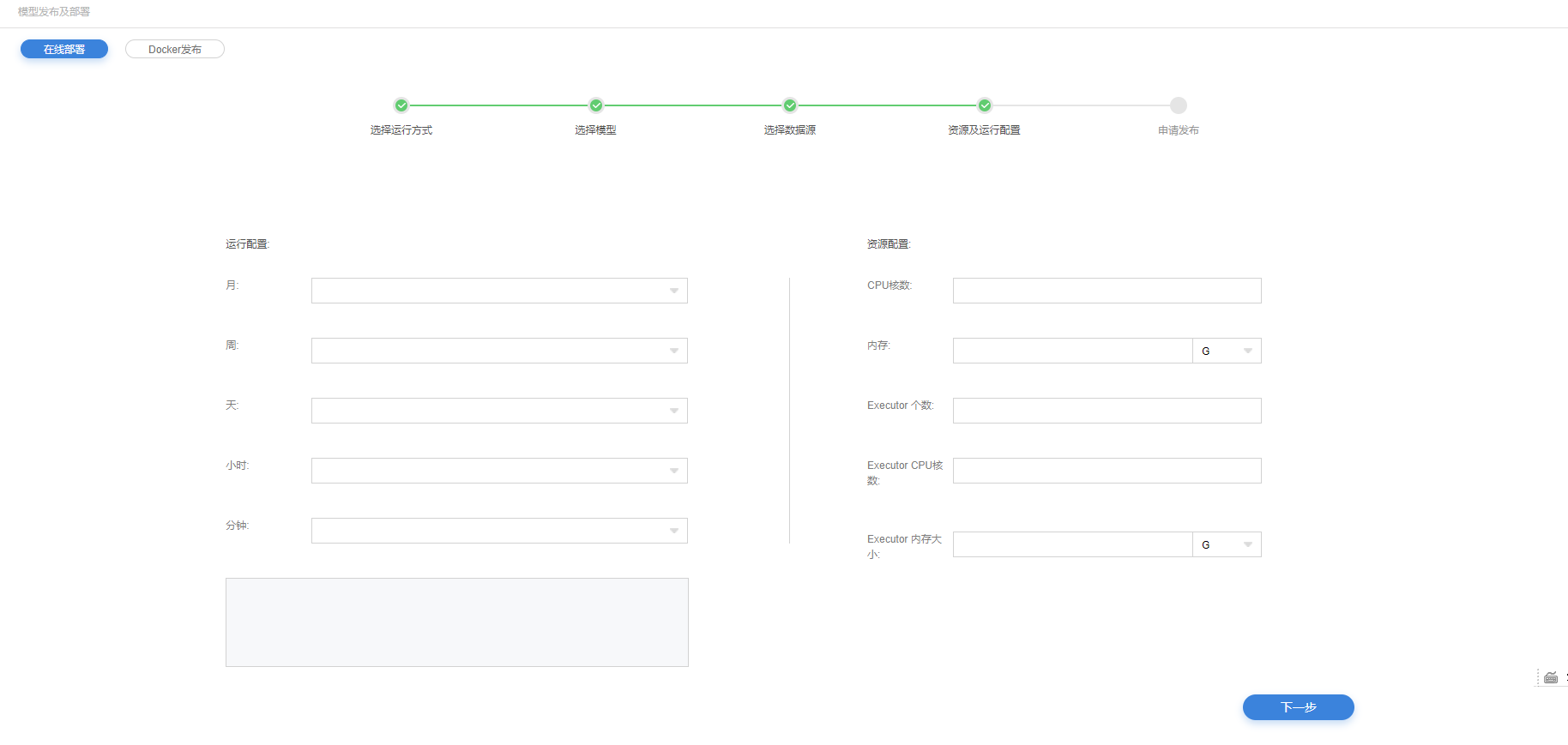
4.对模型运行进行配置。以月、周、天、小时、分钟进行配置。
5.可对模型使用的CPU核数、内存、Executor个数、Executor CPU核数、Executor内存大小的资源配置。
申请发布
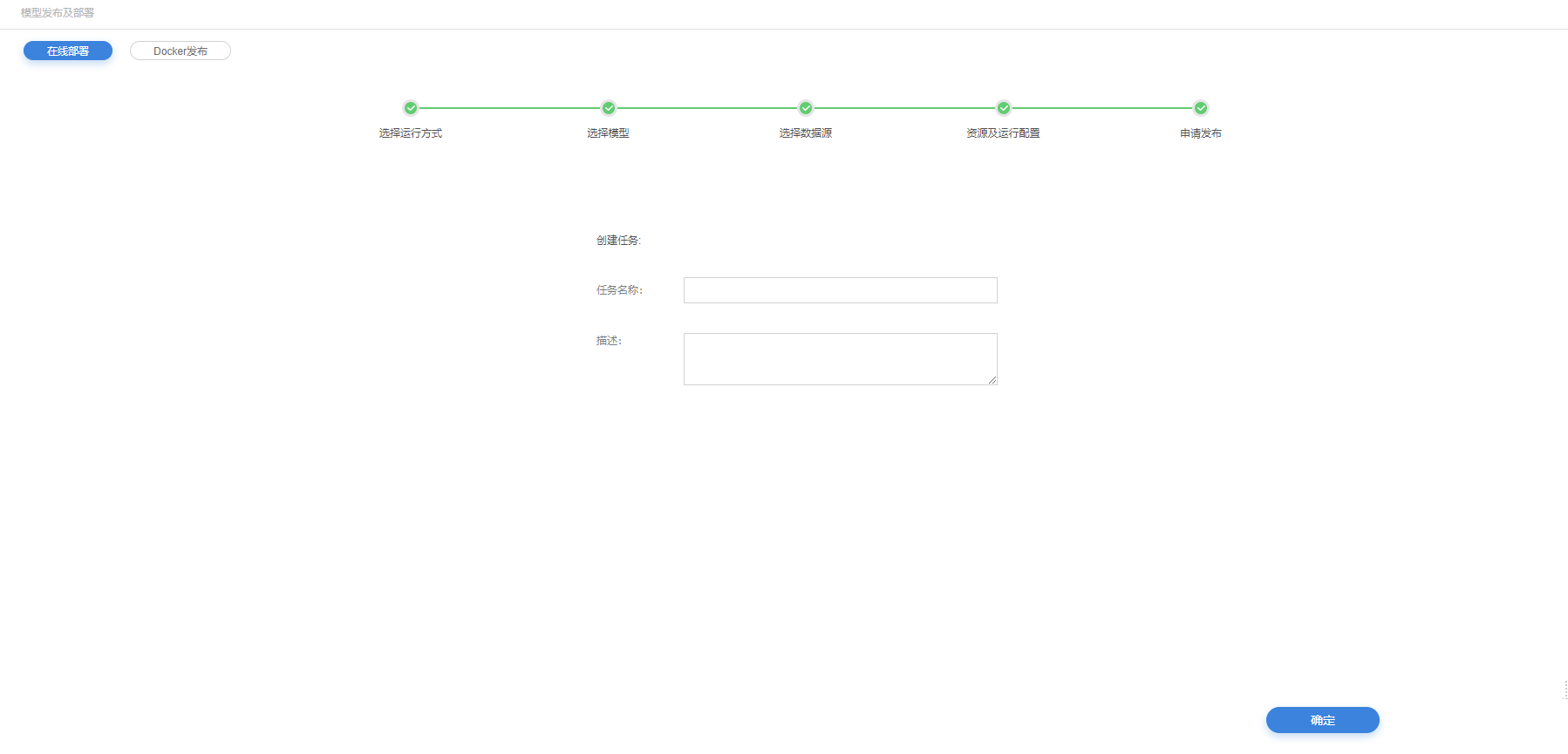
6.将在线部署模型发布生成任务,以便模型部署审核。
7.任务描述。
docker发布
选择运行方式
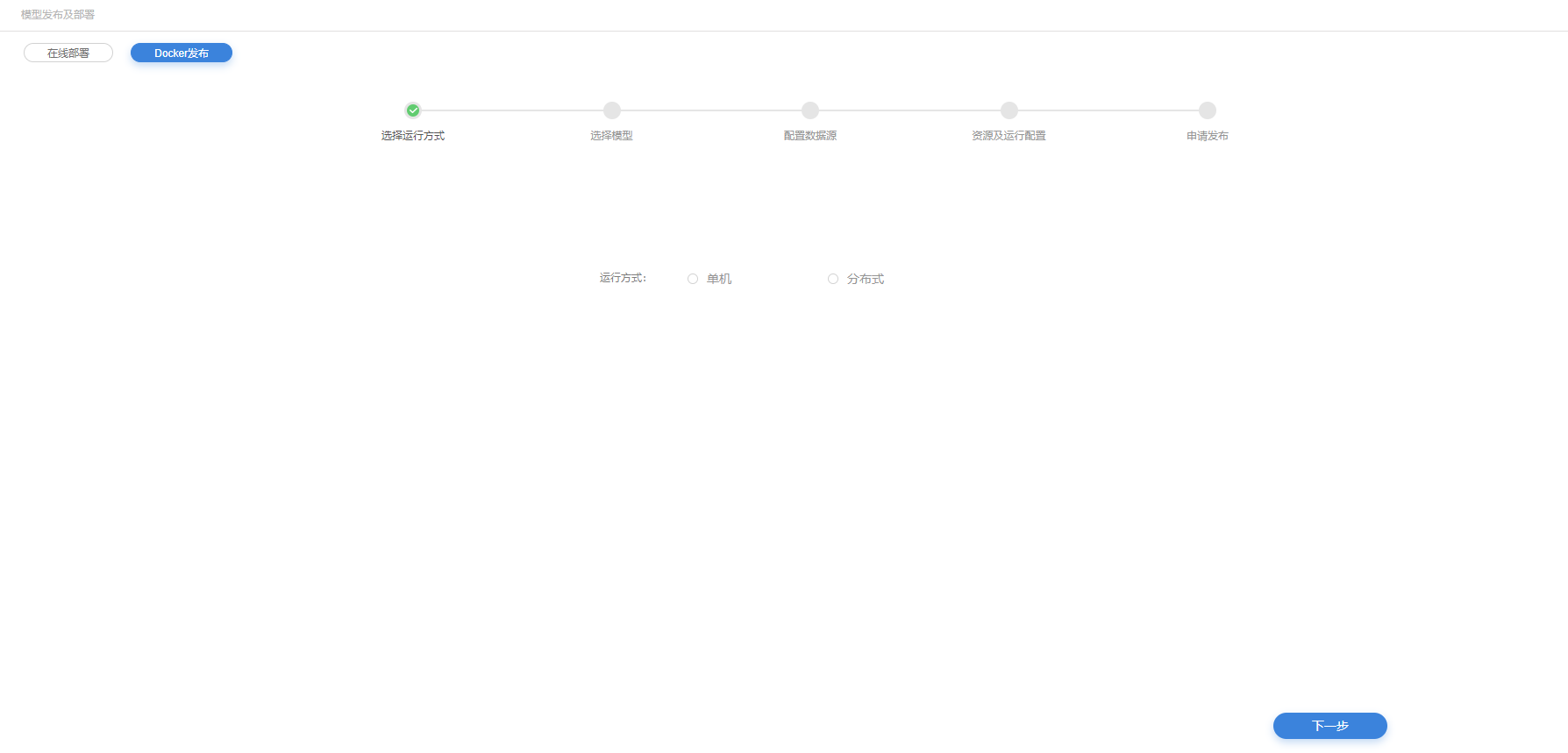
8.选择模型运行方式
选择模型
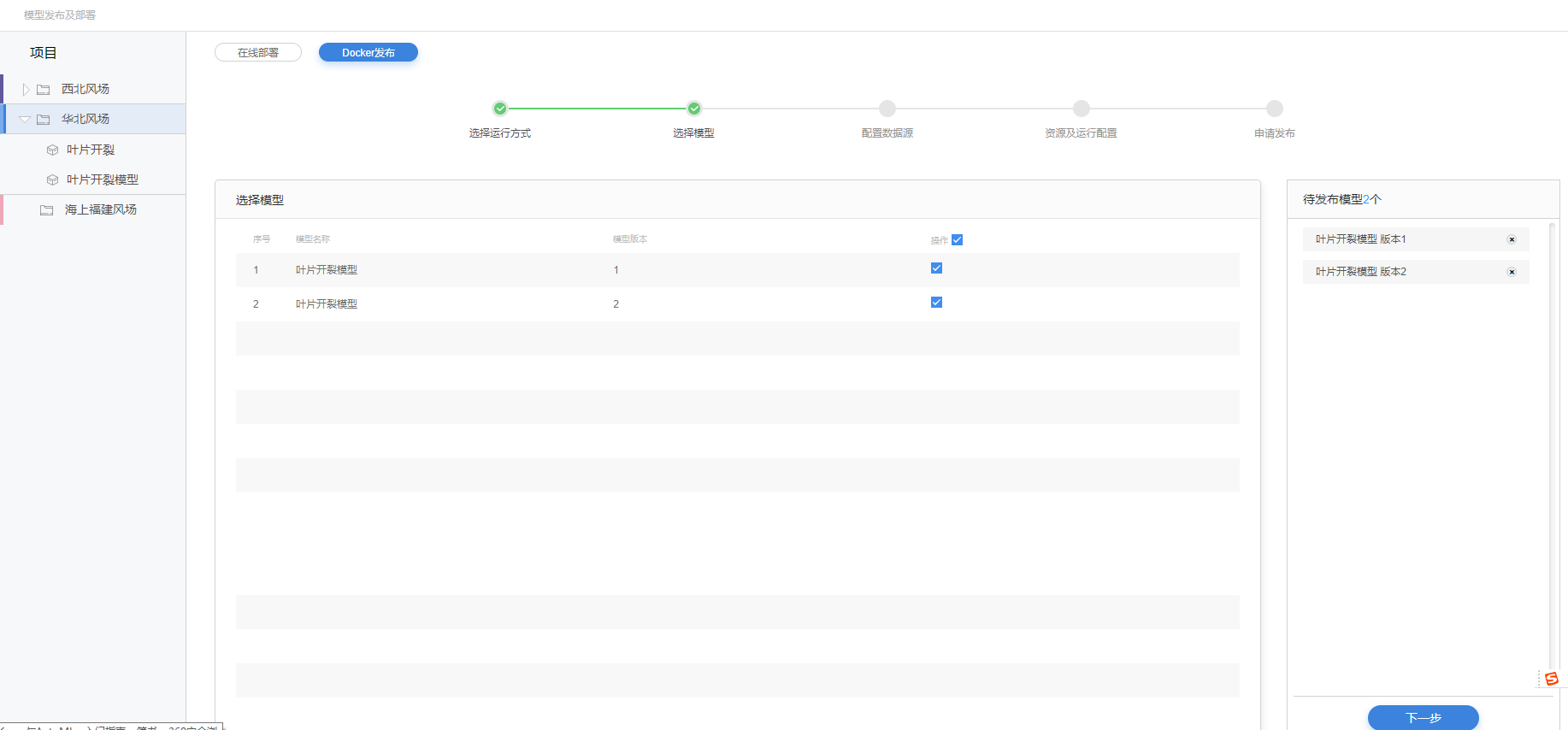
9.在权限范围项目内选择要发布的模型及不同的模型版本,支持多选
选择数据
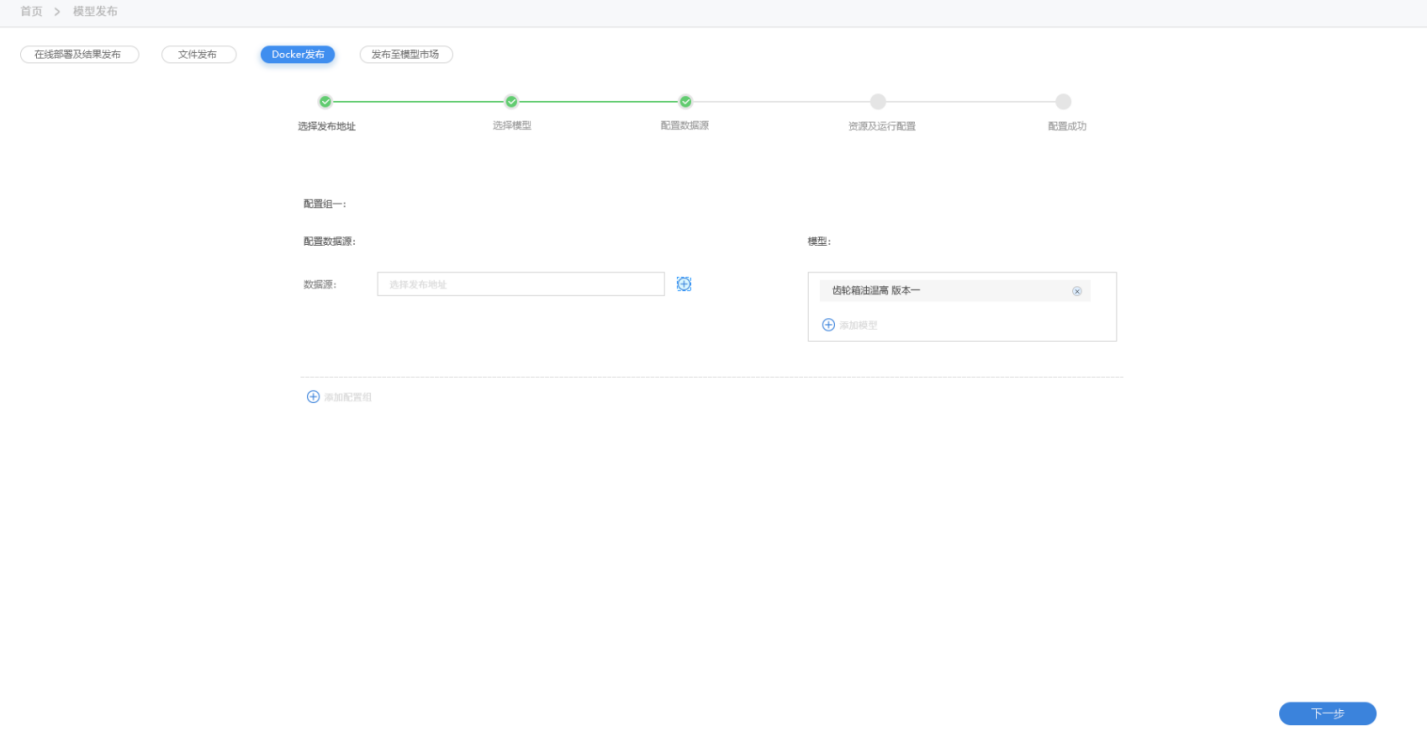
10.选择需要部署的实时数据。
11.可选择不同的数据对应部署不同的模型,以配置组进行区分。
资源及运行配置
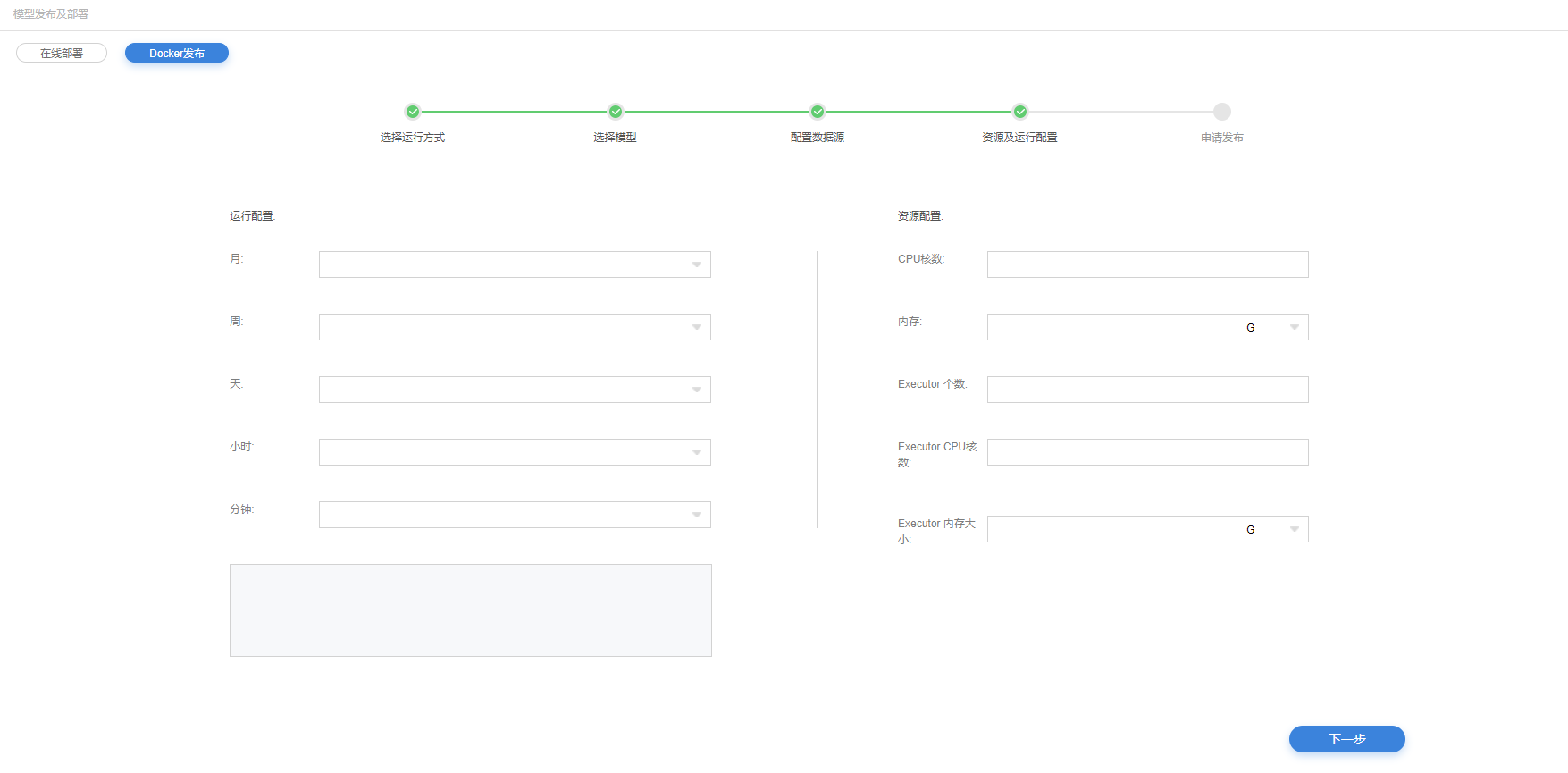
12.对模型运行进行配置。以月、周、天、小时、分钟进行配置。
13.可对模型使用的CPU核数、内存、Executor个数、Executor CPU核数、Executor内存大小的资源配置。
申请发布
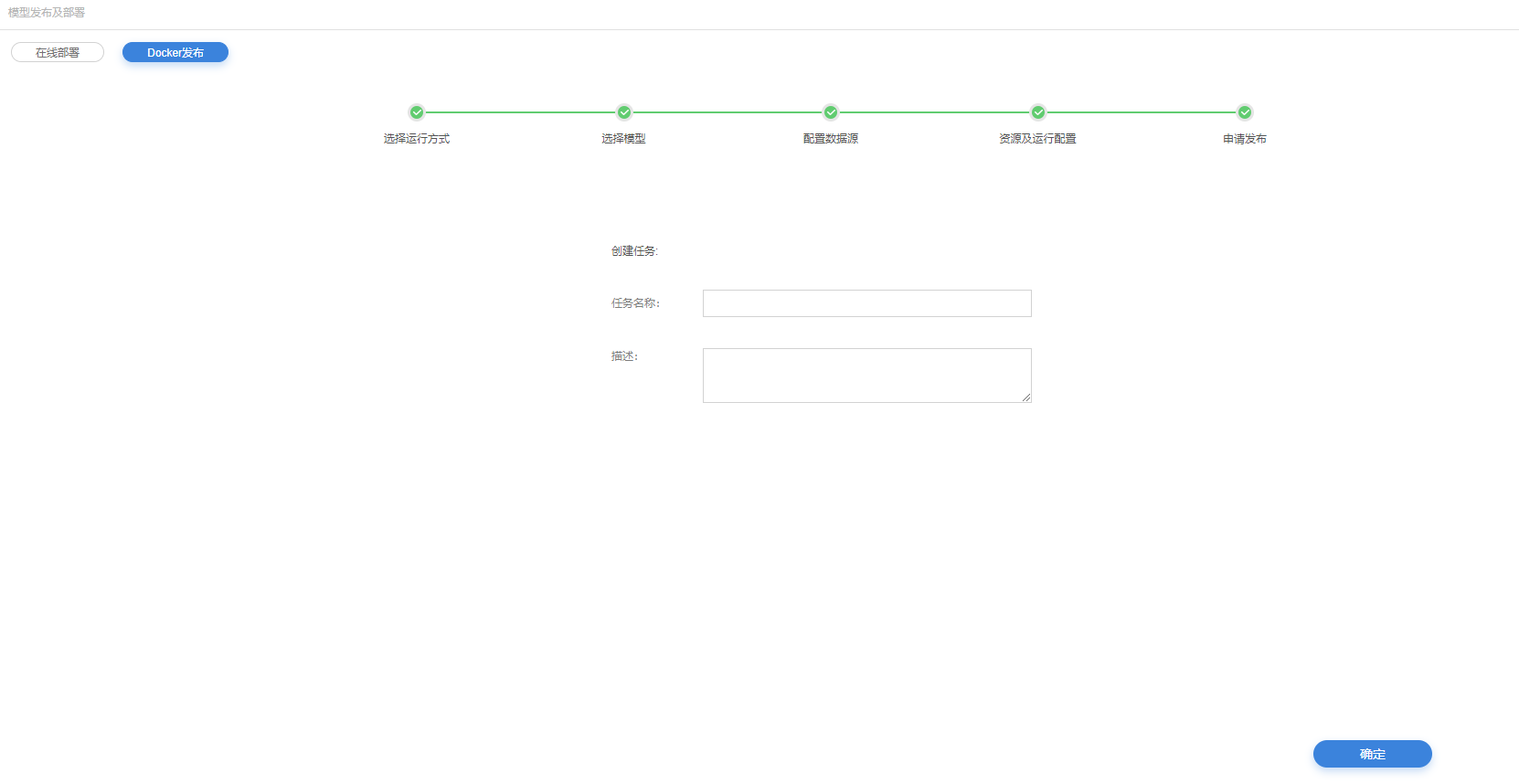
14.将在线部署模型发布生成任务,以便模型部署审核。
15.任务描述。
已部署模型及结果
已部署模型及结果
模型结果
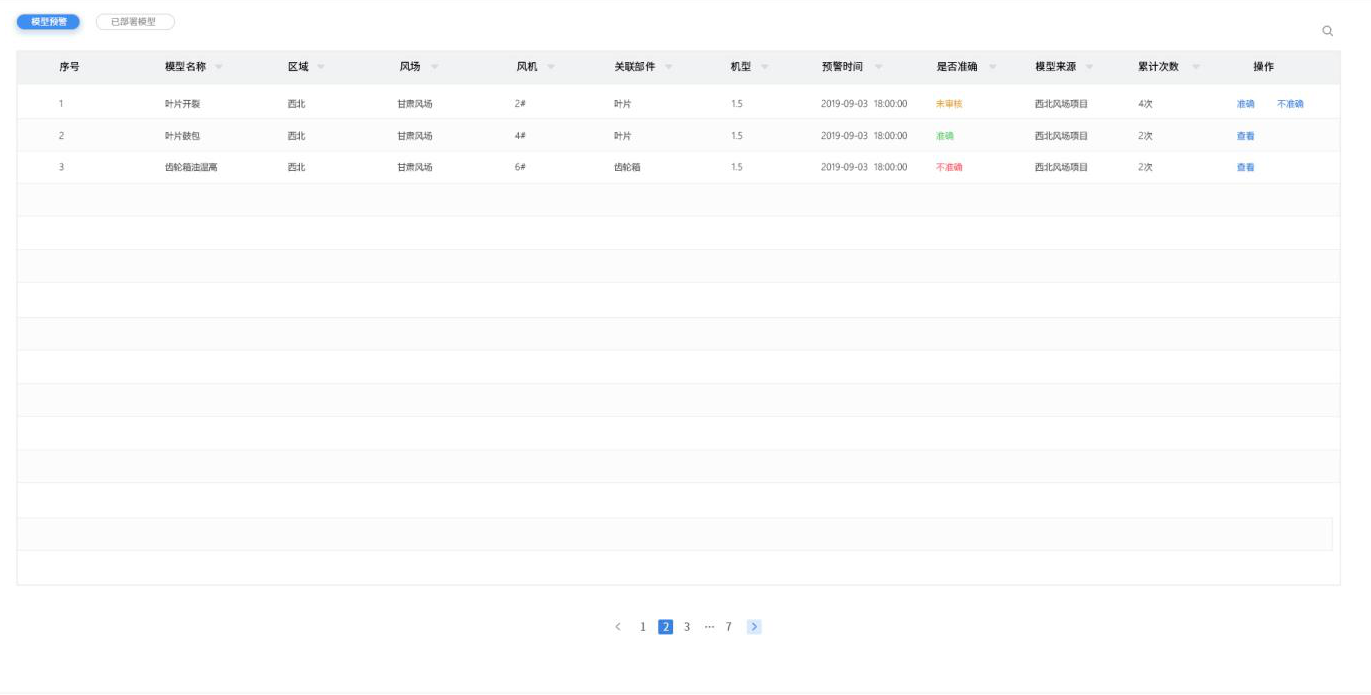
1.展示模型运行结果列表。
2.展示字段:模型名称、项目、区域、场站、设备、设备属性、机型、触发时间、是否准确、模型来源、累计次数、操作。
已部署模型
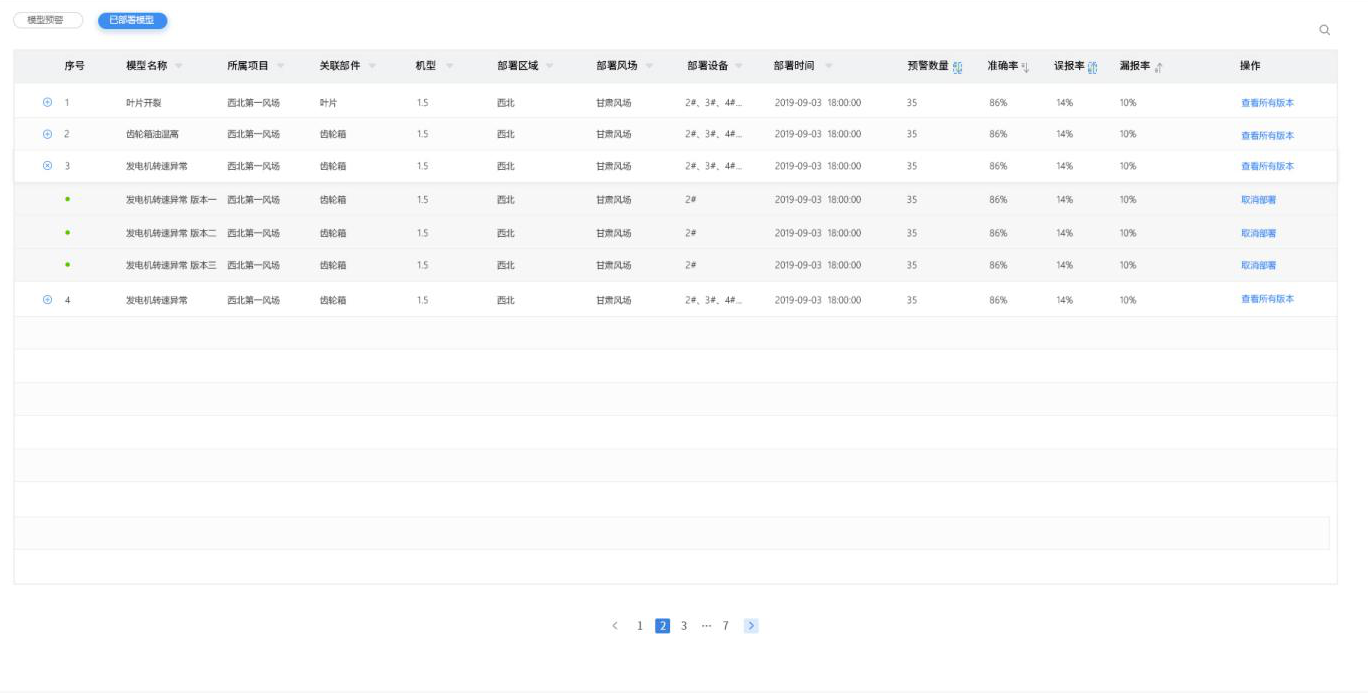
1.展示已部署模型列表。
2.展示字段:模型名称、所属项目、关联部件、部署区域、部署场站、部署设备、部署时间、预警数量、准确率、误报率、漏报率、操作。
发布申请管理
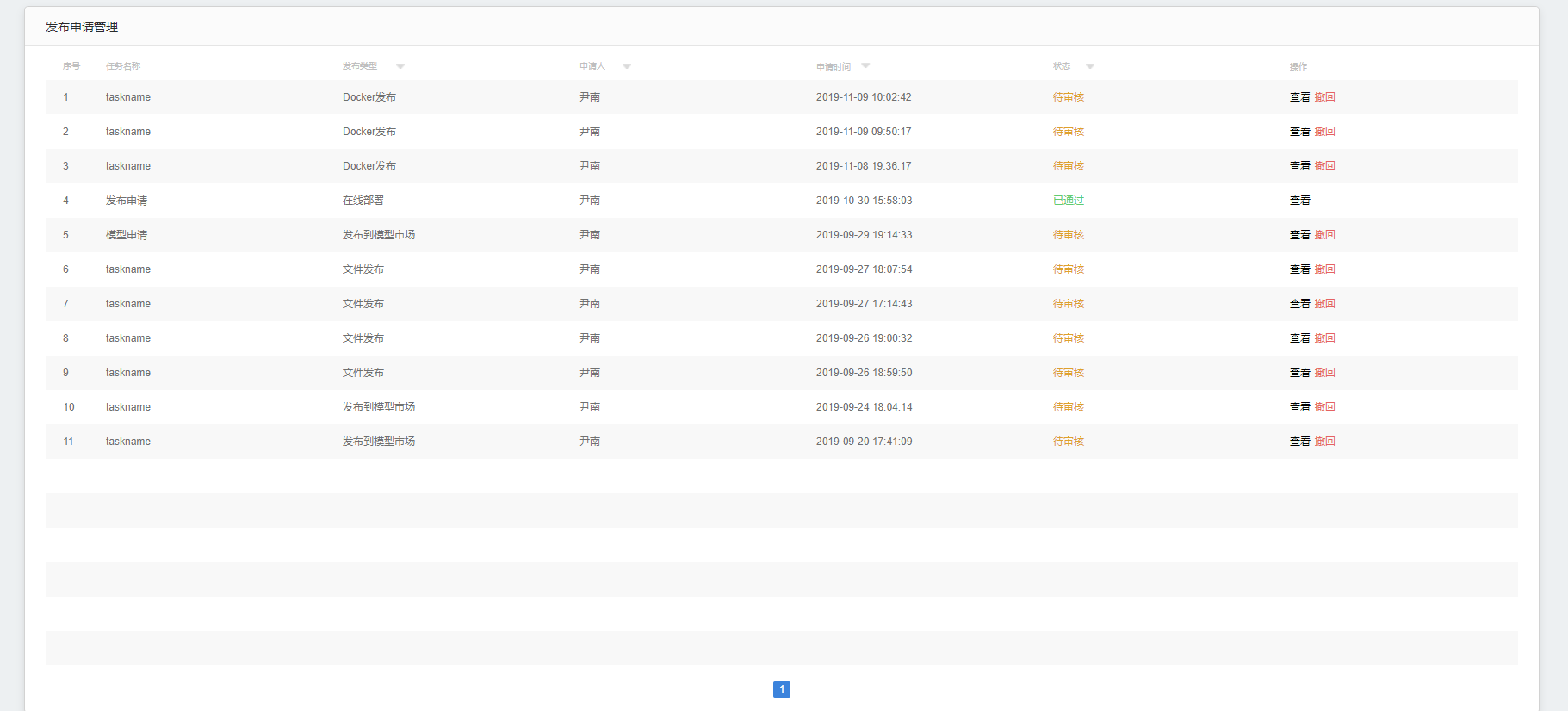
1.模型发布审核界面。
2.表头:任务名称、发布类型、申请人、申请时间、状态、操作(查看、撤回)
3.操作状态:建模权限用户为查看、撤回。审核权限用户为查看、通过、不通过。
4.可查看模型发布的每一步相关配置。
5.表头字段可对列表进行筛选。
资源管理
平台管理员-资源管理
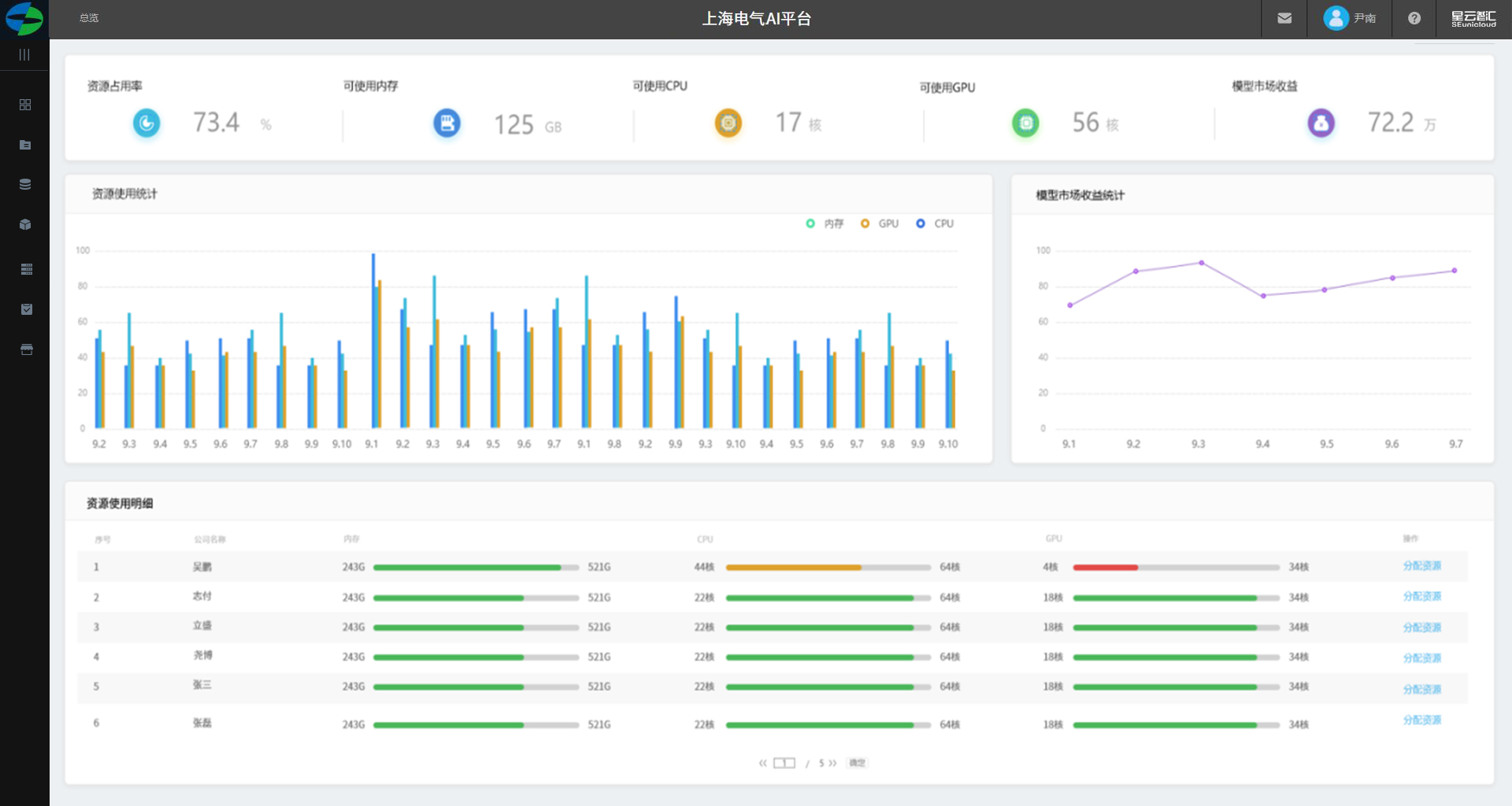
1.展示资源收益、可用内存、可用CPU、可用GPU、模型市场收益以数字展示。
2.展示近一个月的内存、CPU、GPU以天为单位展示峰值柱图。
3.模型使用收益统计展示近一周来自模型市场的收益以折线图展示。
4.资源使用明细展示各个租户的资源总量及剩余量。
5.对租户进行资源分配入口。
租户管理员-资源管理
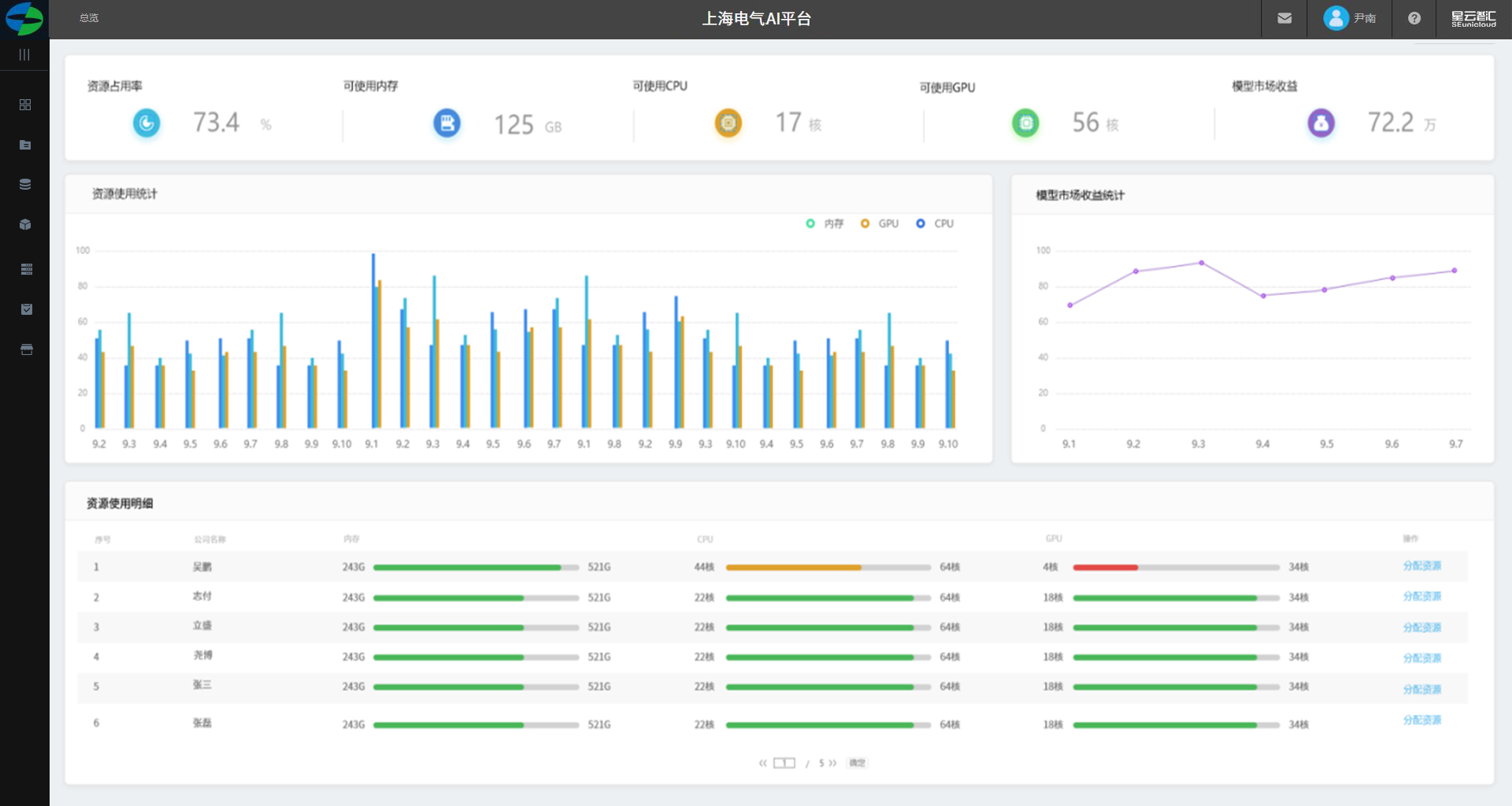
1.展示资源收益、可用内存、可用CPU、可用GPU、模型市场收益以数字展示。
2.展示近一个月的内存、CPU、GPU以天为单位展示峰值柱图。
3.模型使用收益统计展示近一周用户来自模型市场的收益以折线图展示。
4.资源使用明细展示租户权限下各用户的资源总量及使用量。
5.对个人用户进行资源分配入口。
用户-资源管理
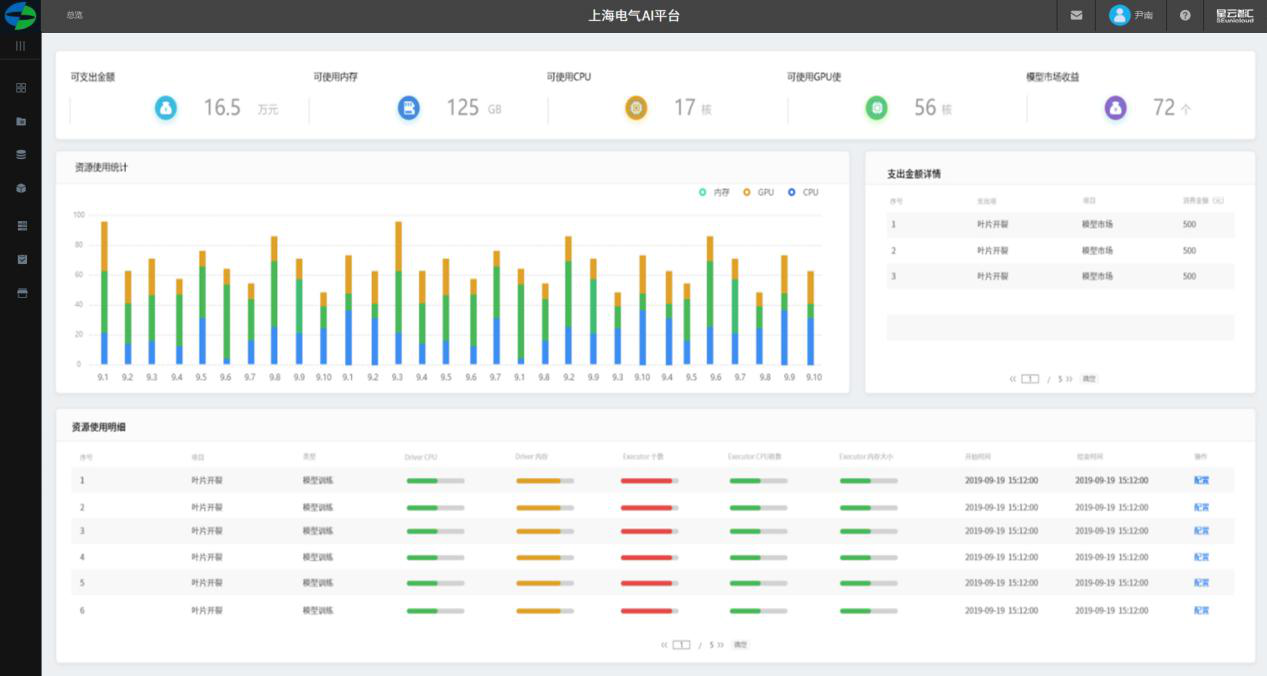
1.展示资源收益、可用内存、可用CPU、可用GPU、模型市场收益以数字展示。
2.展示近一个月的内存、CPU、GPU以天为单位展示峰值柱图。
3.以列表展示所有购买模型支出金额纪录
4.资源使用明细展示租户权限下各用户的资源总量及使用
5.对个人用户进行资源分配入口。
消息
全部消息
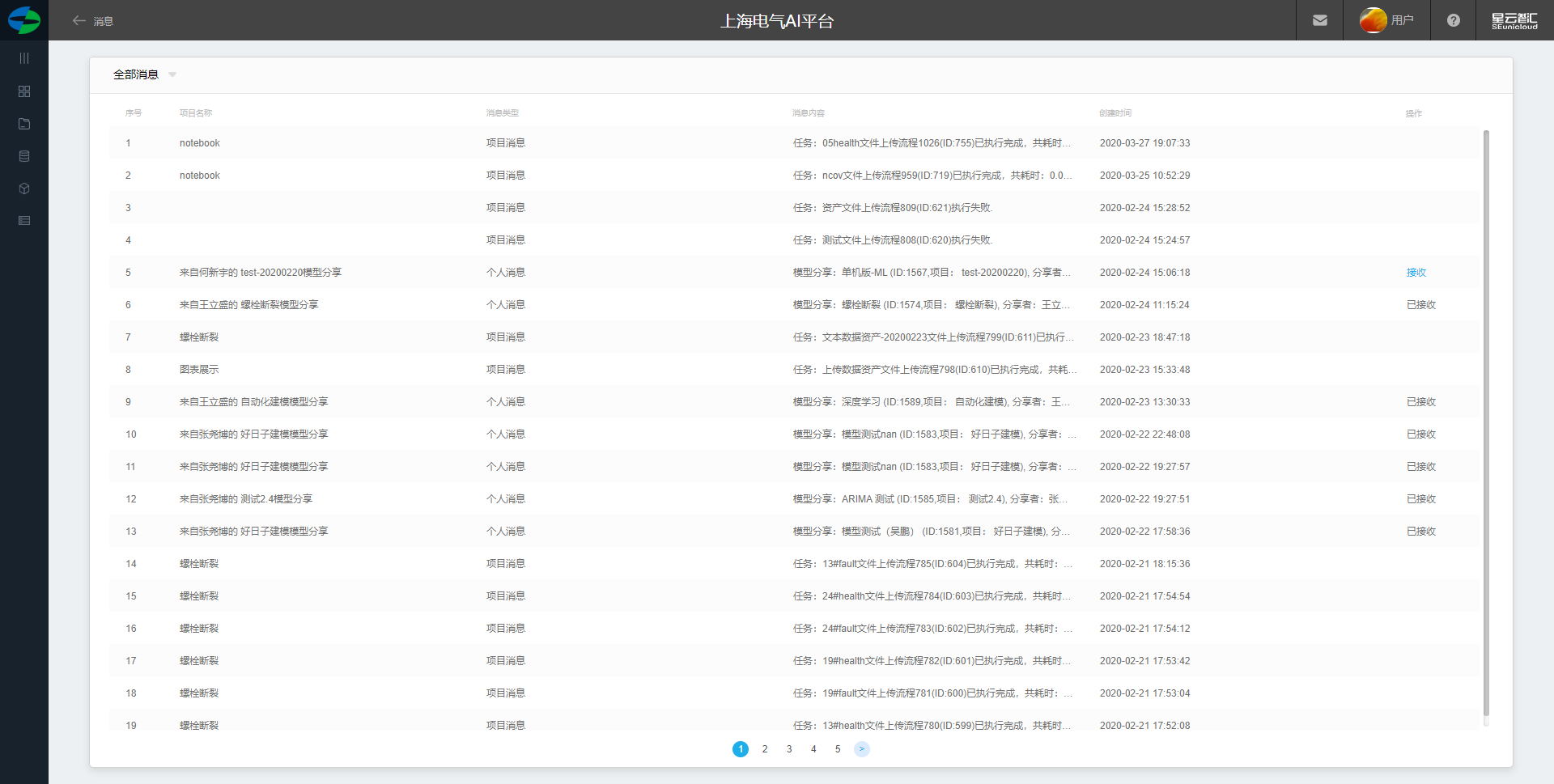
1.展示全部消息列表
2.表头展示字段: 项目名称, 消息类型,消息内容,创建时间, 操作 (可接收被分享的模型,消息删除)。
项目消息
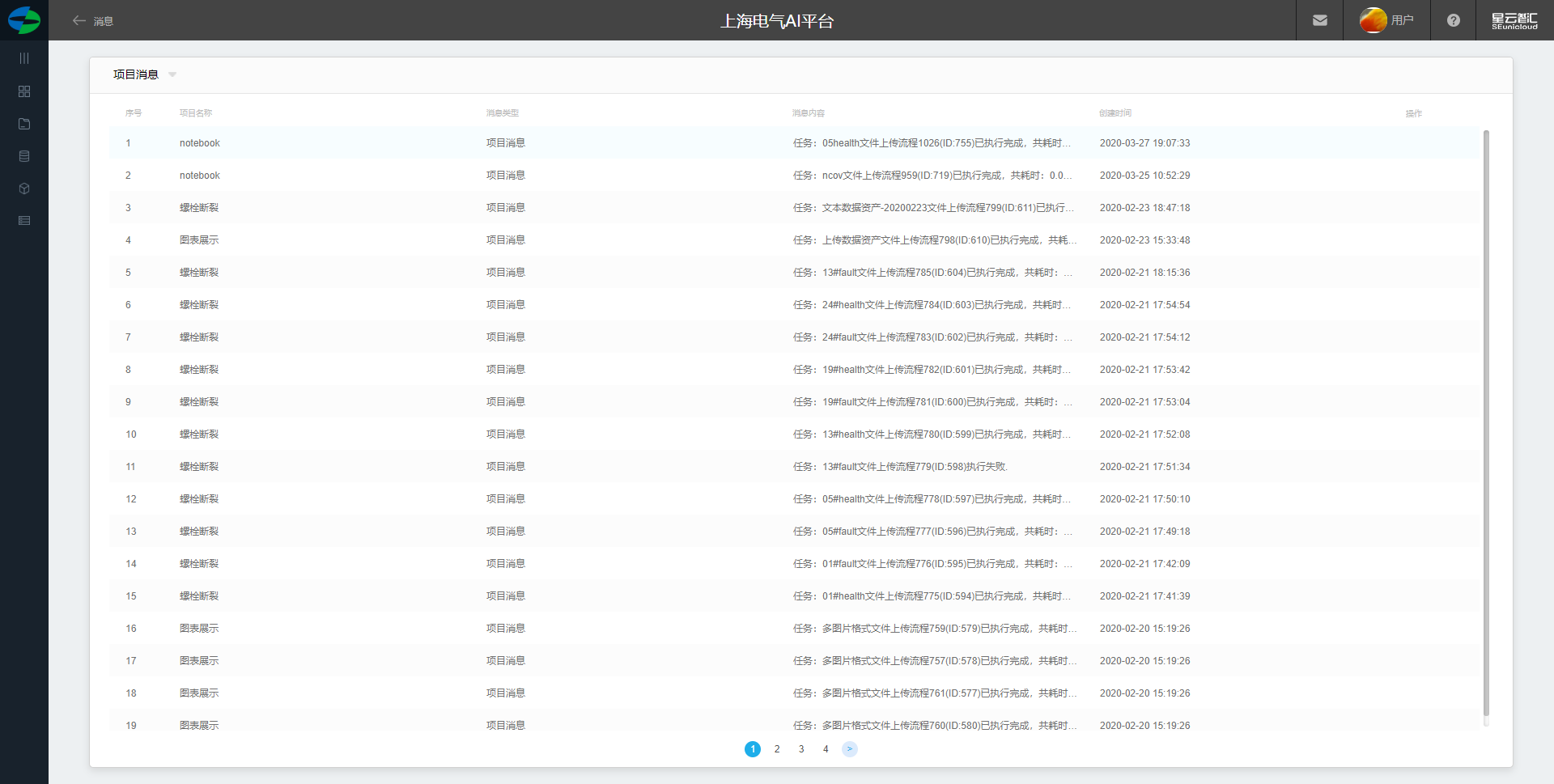
1.展示项目内消息列表
2.表头展示字段: 项目名称, 消息类型,消息内容,创建时间, 操作 (删除)。
平台消息
1.展示平台内消息列表
2.表头展示字段: 项目名称, 消息类型,消息内容,创建时间, 操作 (删除)。
建模组件介绍
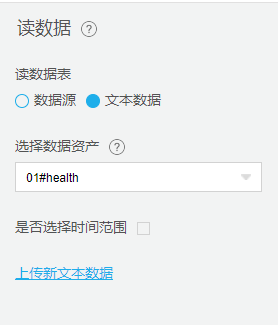
读数据源
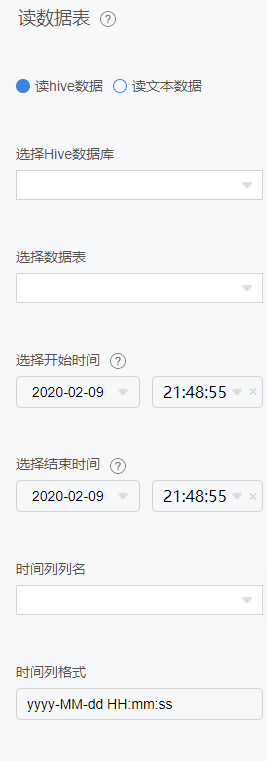
可读取数据中台或第三方数据如:Mongodb、Mysql和大数据hive、hbase、流式数据、图像数据等,或本地数据如:TXT、CSV、XLS、XLSX、ZIP、RAR等文件格式。
打标签
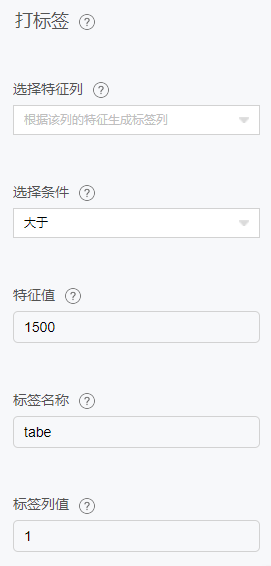
数据标签分为纯数据标签、图像类标签、自然语言标签、音视频标签等。纯数据标签主要实现对机器传感类时序数据进行标签实现对数据的分类或回归建模。图像类标签主要实 现对图像中目标位置的框选标定并记录标定的类型。自然语言标签主要实现对原始无结构的文本进行结构化标注,便于计算机分析。音视频标签实现对视频帧和音频帧进行标注。
缺失值填充
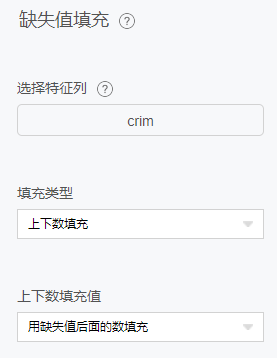
缺失值填充用来将空值或者一个指定的值替换为最大值,最小值,均值或者一个自定义的值。可以通过给定一个缺失值的配置列表,来实现将输入表的缺失值用指定的值来填充。
1.可以将数值型的空值替换为最大值,最小值,均值或者一个自定义的值。
2.可以将字符型的空值,空字符串,空值和空字符串,指定值替换为一个自定义的值。
3.待填充的缺失值可以选择空值或空字符,也可以自定义。
4.缺失值若选择空字符,则填充的目标列应是string型。
5.数值型替换可以自定义,也可以直接选择替换成数值最大值,最小值或者均值。
归一化
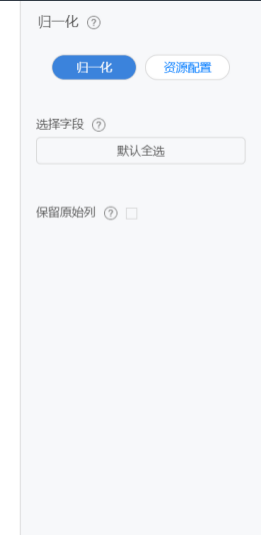
对一个表的某一列或多列,进行归一化处理,产生的数据存入新表中。
正则化
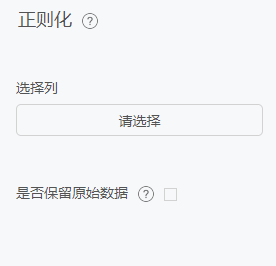
正则化器缩放单个样本让其拥有单位 p 范数。
采样
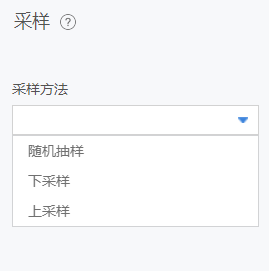
为了满足建模的数据均衡要求,AI平台能够对数据开展不同采样策略,包括上采样、下采样、随机采样。
类型转换
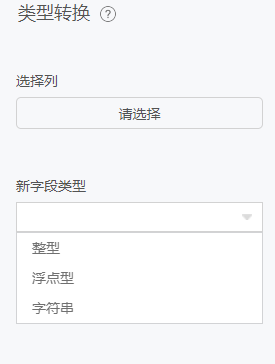
类型转换
数据切分
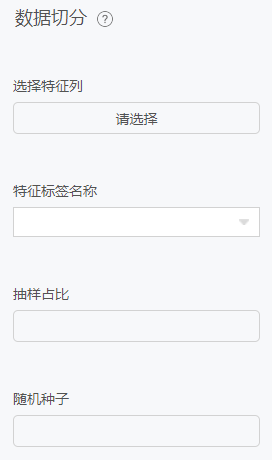
数据切分是另外一种常用的数据预处理算法。在机器学习建模过程中,通常需要训练数据集和验证数据集两类数据集。该方法将数据集按照一定的比例切分为训练数据集和验证数据集。
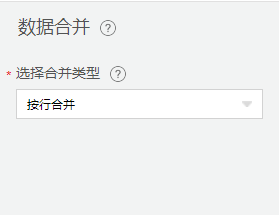
数据合并
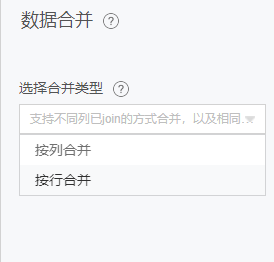
两张表通过关联信息,合成一张表,并决定输出的字段,与SQL的join语句功能类似。
随机森林重要性
使用原始数据和随机森林模型,计算特征重要性。
GBDT特征重要性
计算梯度渐进决策树(GBDT)特征重要性。
独热编码
将离散型特征的每一种取值都看成一种状态,若您的这一特征中有 N 个不相同的取值,那么我们就可以将该特征抽象成 N 种不同的状态,独热编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这 N 种状态中只有一个状态位值为1,其他状态位都是0。
二值化
二值化是一个将数值特征转换为二值特征的处理过程。阈值参数表示决定二值化的阈值。 值大于阈值的特征二值化为1,否则二值化为0。
分箱
特征分箱将连续的特征列转换成离散的列。这些离散值由用户指定,通过“切分区间”参数来确定。
分位数
分位数输入连续的特征列,输出离散的特征。
生成索引列
把数据集中的列特征转换为索引。
过滤
该组件为线性特征重要性、GBDT特征重要性、随机森林特征重要性等重要性评估组件提供过滤功能,支持过滤TopN的特征。
卡方特征选择
卡方检验是一种常用的特征选择方法。卡方用来描述两个事件的独立性或者描述实际观察值与期望值的偏离程度。卡方值越大,则表明实际观察值与期望值偏离越大,也说明两个事件的相互独立性越弱。
方差特征选择
如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。所以通过对低方差的特征进行过滤,是特征选择常用的方法。
协方差
在概率论和统计学中,协方差用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。期望值分别为E(X) = μ 与 E(Y) = ν 的两个实数随机变量X与Y之间的协方差定义为:cov(X, Y) = E((X - μ) (Y - ν))。
相关系数矩阵
相关系数算法用于计算一个矩阵中每一列之间的相关系数,范围在[-1,1]之间。计算的时候,count数按两列间同时非空的元素个数计算,两两列之间可能不同。
卡方效验

卡方校验是校验单个多项分类名义型变量各分类间的实际观测次数与理论次数之间是否一致,其零假设是观测次数与理论次数之间无差异。
正态效验

正态性检验是检验观测值是否服从正态分布,用户可以自选某一种或多种检验方法。
T效验
单样本T检验是检验某个变量的总体均值和某指定值之间是否存在显著差异。T检验的前提是样本总体服从正态分布。
箱线图

可视化多个连续值特征与某个枚举类特征的箱线图和扰动关系。
散点图
在回归分析中,数据点在直角坐标系平面上的分布图。
皮尔森系数
对输入表或分区的2列(必须为数值列),计算其pearson相关系数,结果存入输出表。
小提琴图
小提琴图 (Violin Plot) 用于显示数据分布及其概率密度。
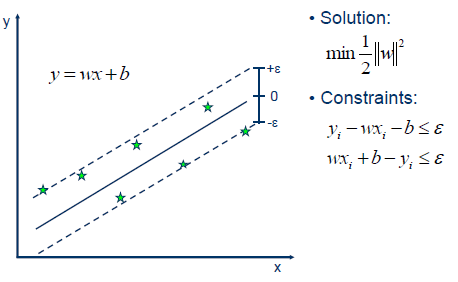
线性回归
线性回归是分析因变量和多个自变量之间线性关系的模型。
原理
在统计学中,线性回归是一种建模因变量与一个或多个解释变量(或自变量)之间关系的线性方法。一个解释变量的情况称为简单线性回归。对于一个以上的解释变量,这个过程称为多元线性回归。这一项不同于多变量线性回归,多变量线性回归预测多个因变量,而不是单个因变量。
在线性回归中,利用线性预测函数对关系进行建模,预测函数的未知模型参数由数据估计得到。这种模型称为线性模型。最常见的情况是,给定解释变量(或预测因子)的值的响应的条件平均值假定为这些值的仿射函数;不太常用的是条件中位数或其他分位数。与所有形式的回归分析一样,线性回归关注给定预测因子值响应的条件概率分布,而不是多元分析中的所有变量的联合概率分布。
线性回归是第一种需要严格研究并在实际应用中得到广泛应用的回归分析方法。这是因为线性依赖于其未知参数的模型比与参数非线性相关的模型更容易拟合,而且结果估计量的统计特性更容易确定。
线性回归有许多实际用途。可以分为以下两大类:
如果目标是预测,或减少误差,线性回归可用于建立预测模型,匹配响应值和解释变量的观测数据集之间的关系。建立该模型后,如果在没有相应响应值的情况下收集解释变量的附加值,则可以使用拟合模型对响应进行预测。
如果目的是将响应变量的变化归因于解释变量的变化,线性回归分析可以应用于量化响应变量和解释变量之间的关系的强度,特别是一些解释性变量与响应变量是否可能没有线性关系,或确定解释变量的子集可能包含的冗余信息。
线性回归模型通常使用最小二乘拟合的方法,但是也可以使用其他方法拟合,比如在其他范数的基础上最小化“失拟项”(如最小绝对偏差回归),或最小化最小二乘法增加惩罚项的代价函数像岭回归(L2范数惩罚项)和Lasso(L1范数惩罚项)。相反,最小二乘法可用于拟合非线性模型。因此,尽管术语“最小二乘”和“线性模型”是紧密联系的,但它们并不是同义词。
配置项

指定标签名称:标签列(单选)。
样本占比:输入为0-1之间。
选择特征列:可多选。
最大迭代次数:非必选默认100。
最小似然误差:非必选默认0.000001。
岭回归
岭回归属于算法组件中机器学习的一种回归组件。
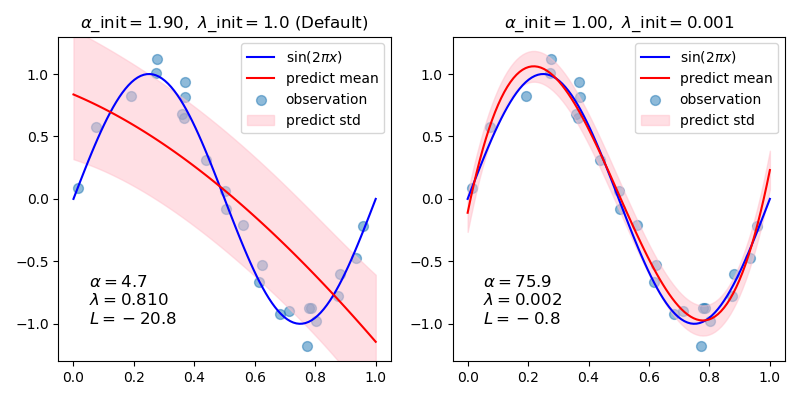
原理
在统计学中,贝叶斯线性回归是在贝叶斯推理的背景下进行统计分析的一种线性回归方法。当回归模型的误差服从正态分布时,如果假设某一特定形式的先验分布,则模型参数的后验概率分布可以得到显式的结果。
在贝叶斯观点中,我们使用概率分布而不是点估计来表示线性回归。响应y不是一个单独的值,而是假设从概率分布中得到的。以正态分布为样本,建立贝叶斯线性回归模型:
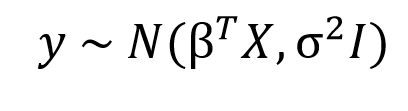
输出y是由正态(高斯)分布产生的,其特征是均值和方差。线性回归的均值是权矩阵的转置乘以预测矩阵。方差的平方标准差σ(乘以单位矩阵,因为这是一个多维模型的制定)。
贝叶斯线性回归的目的不是寻找模型参数的单一“最佳”值,而是确定模型参数的后验分布。不仅响应是由概率分布产生的,而且模型参数也假定是由分布产生的。模型参数的后验概率取决于训练输入和输出:
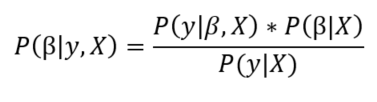
这里,P(β| y, X)模型的后验概率分布参数的输入和输出。这等于数据的可能性,P (y |β,X),乘以参数的先验概率,除以一个归一化常数。这是贝叶斯定理的一个简单表达,它是贝叶斯推理的基础:
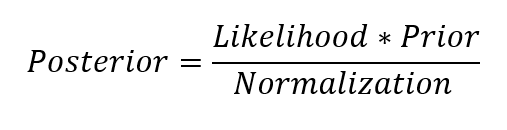
让我们停下来想想这意味着什么。与OLS相比,模型参数的后验分布与数据的可能性乘以参数的先验概率成正比。在这里,我们可以观察到贝叶斯线性回归的两个主要好处。
先验:如果我们有领域知识,或者对模型参数应该是什么有一个猜测,我们可以将它们包含在我们的模型中,而不是像频域方法那样假设所有关于参数的知识都来自于数据。如果我们事先没有任何估计,我们可以对参数使用非信息性先验,比如正态分布。
后验:贝叶斯线性回归的结果是基于数据和先验的可能模型参数的分布。这允许我们量化模型的不确定性:如果我们有更少的数据点,后验分布将会更分散。
随着数据点数量的增加,似然性会冲掉先验,在无限数据的情况下,参数的输出收敛到OLS得到的值。
作为分布的模型参数的表达式封装了贝叶斯世界观:我们从一个初始估计开始,我们的先验,当我们收集更多的证据时,我们的模型变得不那么错误。贝叶斯推理是我们直觉的自然延伸。通常,我们有一个初始的假设,当我们收集支持或反对我们想法的数据时,我们改变了我们对世界的模型(理想情况下,这是我们推理的方式)!
配置项
指定标签名称:标签列(单选)。
样本占比:输入为0-1之间。
选择特征列:可多选。
lasso回归
原理
LassoLarsIC类的损失函数和损失函数的优化方法完全与LassoLarsCV类相同,区别在于验证方法。
验证方法
LassoLarsIC类对超参数α没有使用交叉验证,而是用 Akaike信息准则(AIC)和贝叶斯信息准则(BIC)。此时我们并不需要指定备选的α值,而是由LassoLarsIC类基于AIC和BIC自己选择。用LassoLarsIC类我们可以一轮找到超参数α,而用K折交叉验证的话,我们需要K+1轮才能找到。相比之下LassoLarsIC类寻找α更快。
配置项
指定标签名称:单选。
样本占比:输入为0-1之间。
选择特征列:可多选。
最大迭代次数:非必选默认100。
随机种子:非必选。
是否计算截距:是、否。
弹性网络回归
原理
在统计学中,特别是在线性或逻辑回归模型的拟合中,弹性网络是一种正则化的回归方法,它将L1和L2惩罚值线性组合起来。
弹性网最初是由于对lasso的批评而出现的,lasso的变量选择可能过于依赖于数据,因此不稳定。解决方案是结合岭回归和lasso的惩罚项,以得到最好的模型。弹性网络的目标是使以下损失函数最小化:
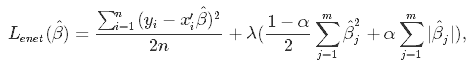
现在,有两个参数需要调优:λ和α。
配置项
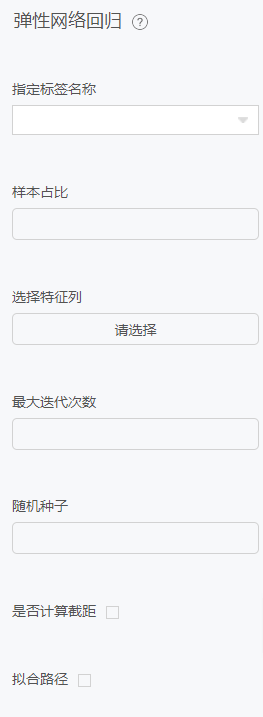
偏最小二乘回归
原理
偏最小二乘用于查找两个矩阵(X和Y)的基本关系,即一个在这两个空间对协方差结构建模的隐变量方法。偏最小二乘模型将试图找到X空间的多维方向来解释Y空间方差最大的多维方向。偏最小二乘回归特别适合当预测矩阵比观测的有更多变量,以及X的值中有多重共线性的时候。通过投影预测变量和观测变量到一个新空间来寻找一个线性回归模型。
配置项
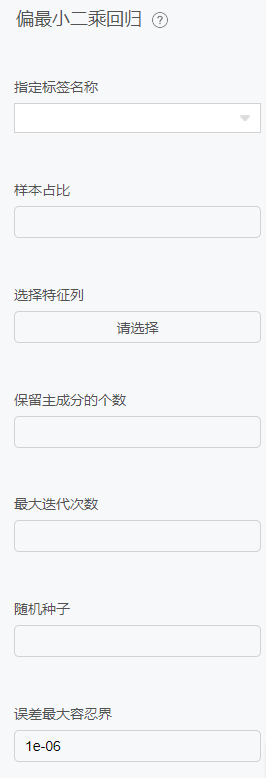
稳健回归
原理
稳健回归(robust regression)是将稳健估计方法用于回归模型,以拟合大部分数据存在的结构,同时可识别出潜在可能的离群点、强影响点或与模型假设相偏离的结构。当误差服从正态分布时,其估计几乎和最小二乘估计一样好,而最小二乘估计条件不满足时,其结果优于最小二乘估计。
配置项
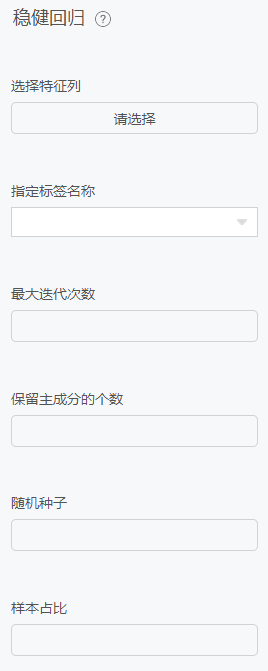
支持向量机回归
原理
在机器学习中,支持向量机(SVMs,也称为支持向量网络)是一种有关联学习算法的监督学习模型,支持分类和回归问题的数据建模。给定一组训练数据,每个样本属于一个或其他类别,用支持向量机算法构建并训练一个模型,将新样本分配到一个类别,使它成为一个非概率性二分类器。支持向量机模型是将样本表示为空间中的点,并将其映射,以便将不同类别的样本之间的间距尽可能大。然后,新的样本被映射到相同的空间中,并根据它们所处的位置,预测它们属于某个类别。
除了执行线性分类,支持向量机还可以通过使用核线方程有效地执行非线性分类,隐式地将它们的输入映射到高维特征空间。
当数据没有标记时,监督学习是不可能的,需要一种无监督学习方法,通过无监督学习试图找到数据到类别的自然聚类,然后将新数据映射到这些形成的类别。支持向量聚类算法是由Hava Siegelmann和Vladimir Vapnik共同创建的,它利用支持向量的统计量对未标注的数据进行分类,是工业应用中应用最广泛的聚类算法之一。
支持向量机也可以作为回归方法,保持算法的所有主要特征(最大边缘算法)。支持向量回归(SVR)使用与支持向量机相同的原则进行分类,只有一些细微的差异。首先,因为输出是一个连续值,所以很难预测,因为它有无限种可能性。在回归的情况下,容忍度(epsilon)被设置为支持向量机的近似值,算法将更加复杂。然而,其主要思想始终是相同的:为了最小化误差,使超平面的类别间距最大化,但是部分误差是可以容忍的。
配置项
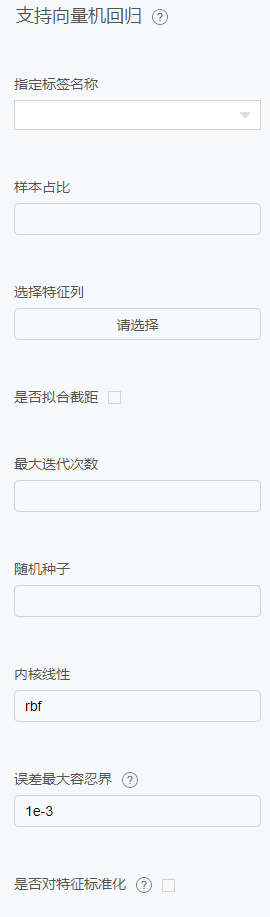
最近邻回归
原理
最近邻方法原理是从训练样本中找到与查询点在距离上最近的预定数量或范围的多个点,然后依据这些点来预测查询点的标签。从训练样本中找出点的数量可以是用户定义的常量,这叫ķ最近邻学习即KNN,也可以通过用户定义的查询点的距离半径范围得出,这叫基于半径的最近邻学习即RNN。
数据之间的距离可以理解为数据之间的相似度。距离可以通过多种方式来度量,如欧几里得距离,曼哈顿距离等。标准欧几里得是最常见的选择。
最近邻学习方法称为非泛化机器学习方法,因为只是简单的“记住”了其所有的训练数据,死记硬背下所有历史数据,在新数据面前就与所有的历史数据比较从而找出最相似的历史数据。而泛化的机器学习方法在给定的样本数据进行训练之后会形成概念模型,在新数据面前则依据概念模型直接推导计算得出结论。
配置项

高斯回归
原理
高斯过程回归(Gaussian Process Regression, GPR)是使用高斯过程(Gaussian Process, GP)先验对数据进行回归分析的非参数模型(non-parameteric model) [1]。
GPR的模型假设包括噪声(回归残差)和高斯过程先验两部分,其求解按贝叶斯推断(Bayesian inference)进行 。若不限制核函数的形式,GPR在理论上是紧致空间(compact space)内任意连续函数的通用近似(universal approximator)。此外,GPR可提供预测结果的后验,且在似然为正态分布时,该后验具有解析形式。因此,GPR是一个具有泛用性和可解析性的概率模型 。
配置项
随机森林回归
原理
随机森林是一种集成的机器学习方法,能够使用多个决策树和统计技术(即bagging)执行回归和分类任务。Bagging和Boosting是两种最流行的集成技术,旨在解决高方差和高偏差。RF不只是对树的预测进行平均,它使用了两个关键概念,并因此得名random:
1 建立决策树时使用训练样本的随机抽样结果 2 分裂节点使用随机特征子集
换句话说,随机森林构建多个决策树,并将它们的预测合并在一起,从而获得更准确、更稳定的预测,而不是依赖于单个决策树。
随机森林中的每棵树都是从训练观察样本的随机抽样中学习。这些样本是通过有放回抽样取出,称之为bootstrapping,这意味着一些样本将在单个树中多次使用。这个想法是通过用不同的样本训练每棵树,虽然每棵树可能对特定的一组训练数据有很高的方差,但总体来说,整个森林的方差会更低,也不会以增加偏差为代价。在随机森林的Sklearn实现中,如果设置bootstrap=True,每棵树的子样本是通过有放回抽样取出,并且大小总是与原始输入相同,如果设置bootstrap=False,每棵树都将使用完全相同的数据集,没有任何随机性。
随机森林的另一个主要概念是,在决定拆分节点时,每棵树只能看到所有特征的子集。在Skearn中,这可以通过指定max_features = sqrt(n_features)来设置,这意味着如果每棵树的每个节点上有16个特性,那么将只考虑4个随机特征来分割节点。
随机森林的基本思想是将许多决策树的预测组合成一个模型。单独来看,决策树做出的预测可能并不准确,但综合起来,这些预测将更接近真实的平均值。
每棵树都有自己的信息源,因为它们在形成问题时考虑的是特征的随机子集,并且可以访问一组随机的训练数据点。如果我们只构建一棵树,我们将只利用它们有限的信息范围,但是通过将许多树的预测组合在一起,我们的净信息将会大得多。如果相反,每棵树都使用相同的数据集,那么每棵树都会受到异常或离群值的影响。
这增加了森林的多样性,导致了鲁棒性更强的整体预测。在进行预测时,随机森林回归模型会取所有决策树估计值的平均值。
配置项
xgboost回归
原理
Xgboost的生成过程:
迭代生成新的树,递归生长树,每生成新的树就是去预测上棵树的残差。
Xgboost使用的是CART回归树,是个二叉树,使用gain来选择特征最佳分裂点分裂。
训练后得到的模型是多棵树,每棵树有多个叶子节点
预测过程:样本根据特征值会在每棵树落到一个叶子节点上,最终的预测值就是每颗树对应叶子节点的分数乘树权重和。
配置项
lightgbm回归
原理
GBDT是机器学习中的一个非常流行并且有效的算法模型,它是一个基于决策树的梯度提升算法。
配置项
ARIMA自回归
原理
ARIMA模型是差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动),时间序列预测分析方法之一。ARIMA(p,d,q)中,AR是"自回归",p为自回归项数;MA为"滑动平均",q为滑动平均项数,d为使之成为平稳序列所做的差分次数(阶数)。“差分”一词虽未出现在ARIMA的英文名称中,却是关键步骤。
ARIMA(p,d,q)模型是ARMA(p,q)模型的扩展。ARIMA(p,d,q)模型可以表示为:
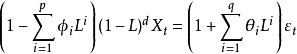
其中L是滞后算子(Lag operator),
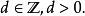
配置项

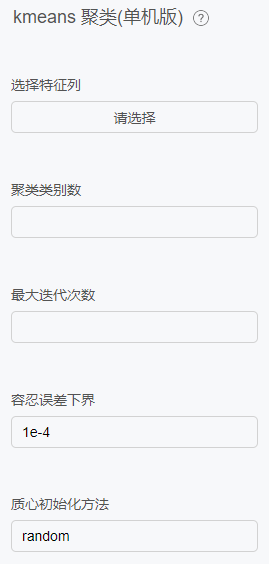
kmeans聚类
原理
KMeans 是一种常用的聚类算法,将无标签的数据聚成 K 个类。
配置项
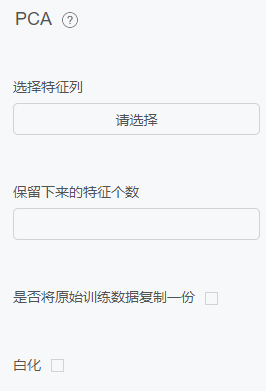
PCA
原理
PCA(Principal Component Analysis) 是一种常见的数据分析方式,常用于高维数据的降维,可用于提取数据的主要特征分量。
配置项
SVD
原理
特征值分解是一个提取矩阵特征很不错的方法,但是它目前只适用于方阵。
配置项

NMF
原理
NMF一种矩阵分解方法,它使分解后的所有分量均为非负值(要求纯加性的描述),并且同时实现非线性的维数约减。NMF已逐渐成为信号处理、生物医学工程、模式识别、计算机视觉和图像工程等研究领域中最受欢迎的多维数据处理工具之一。
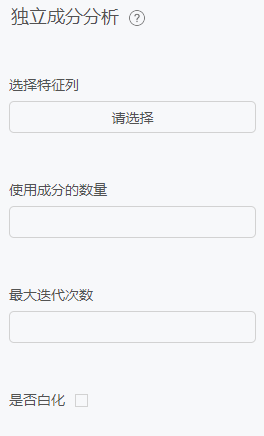
独立成分分析
原理
CA(Independent Component Correlation Algorithm)是一种函数,X为n维观测信号矢量,S为独立的m(m<=n)维未知源信号矢量,矩阵A被称为混合矩阵。ICA的目的就是寻找解混矩阵W(A的逆矩阵),然后对X进行线性变换,得到输出向量U。
配置项
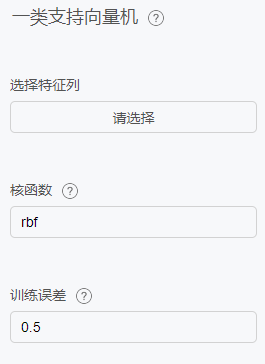
一类支持向量机
原理
支持向量机(SVM)是90 年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。
配置项
隔离森林
配置项
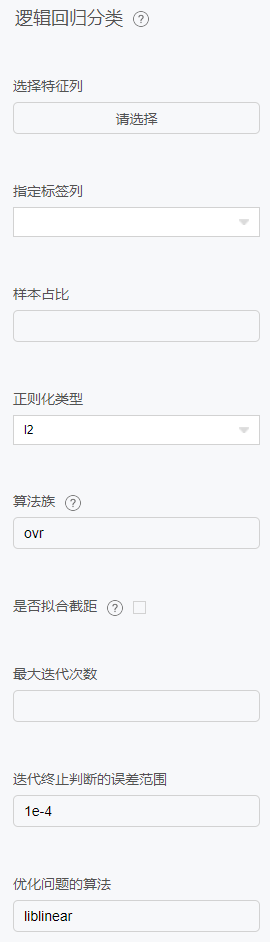
逻辑回归分类
原理
辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏。
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别)。
回归模型中,y是一个定性变量,比如y=0或1,logistic方法主要应用于研究某些事件发生的概率。
配置项
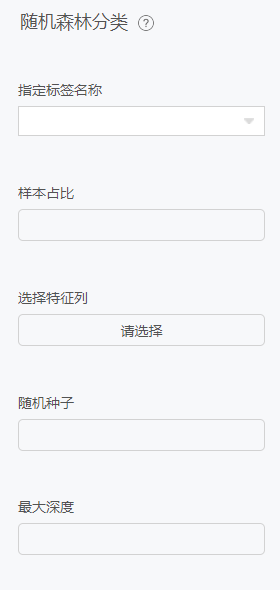
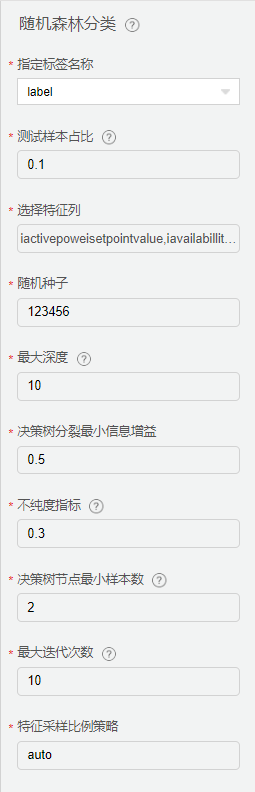
随机森林分类
原理
随机森林算法是一种监督式分类算法。我们从名字上也能看出来,它是用来以某种方式创建一个森林,并使其随机。森林中的树的数量直接关系到算法得到的结果:树越多,结果就越准确。但是需要注意一点是,创建森林并不等同于用信息增益或构建索引的方法来创建决策。
熟悉决策树的人在首次接触随机森林时可能会有些困惑。决策树是一种决策辅助工具,它是用一种树状的图形来展示可能的结果。如果你将一个带有目标和特征的训练集输入到决策树里,它就会表示出一些规律出来。这些规律就可以用于执行预测。举个例子,假如你想预测你的女儿是否会喜欢一部动画片,你就可以收集她以前喜欢的动画片,将某些特征作为输入。然后通过决策树算法,你就可以生成相应的规律。而收集这些信息节点和形成规律的过程就是使用信息增益方法和基尼系数计算的过程。
随机森林算法和决策树算法分不同之处就是,在随机森林中,找到根节点和划分特征节点的过程会以随机的方式进行。
配置项
Xgboost分类
原理
xgboost是在GBDT的基础上对boosting算法进行的改进,内部决策树使用的是回归树,简单回顾GBDT如下:
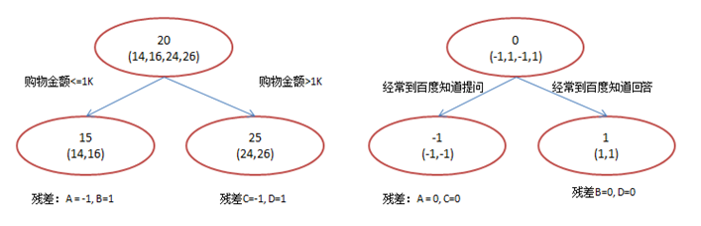
回归树的分裂结点对于平方损失函数,拟合的就是残差;对于一般损失函数(梯度下降),拟合的就是残差的近似值,分裂结点划分时枚举所有特征的值,选取划分点。 最后预测的结果是每棵树的预测结果相加。
配置项
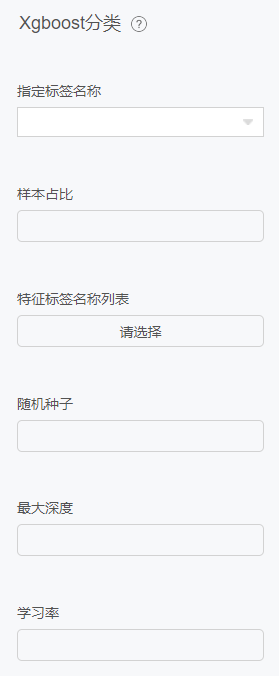
支持向量机分类
原理
在机器学习中,支持向量机(SVMs,也称为支持向量网络)是一种有关联学习算法的监督学习模型,支持分类和回归问题的数据建模。给定一组训练数据,每个样本属于一个或其他类别,用支持向量机算法构建并训练一个模型,将新样本分配到一个类别,使它成为一个非概率性二分类器。支持向量机模型是将样本表示为空间中的点,并将其映射,以便将不同类别的样本之间的间距尽可能大。然后,新的样本被映射到相同的空间中,并根据它们所处的位置,预测它们属于某个类别。
除了执行线性分类,支持向量机还可以通过使用核线方程有效地执行非线性分类,隐式地将它们的输入映射到高维特征空间。
当数据没有标记时,监督学习是不可能的,需要一种无监督学习方法,通过无监督学习试图找到数据到类别的自然聚类,然后将新数据映射到这些形成的类别。支持向量聚类算法是由Hava Siegelmann和Vladimir Vapnik共同创建的,它利用支持向量的统计量对未标注的数据进行分类,是工业应用中应用最广泛的聚类算法之一。
支持向量机也可以作为回归方法,保持算法的所有主要特征(最大边缘算法)。支持向量回归(SVR)使用与支持向量机相同的原则进行分类,只有一些细微的差异。首先,因为输出是一个连续值,所以很难预测,因为它有无限种可能性。在回归的情况下,容忍度(epsilon)被设置为支持向量机的近似值,算法将更加复杂。然而,其主要思想始终是相同的:为了最小化误差,使超平面的类别间距最大化,但是部分误差是可以容忍的。
配置项
最近邻分类
原理
通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的 k 个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。
KNN 算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
配置项
lightgbm分类
原理
LightGBM是一个梯度Boosting框架,使用基于决策树的学习算法。
配置项
CNN卷积神经网络
原理
卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络在图像和语音识别方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网络,卷积神经网络需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构。
配置项

LSTM循环神经网络
原理
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network) 。
配置项
GRU循环神经网络
原理
作为LSTM的一种变体,通过分析LSTM架构中哪些部分是真正需要的,进行了改进,将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
配置项
DNN分类
原理
(1) 加入了隐藏层
(2) 输出层的神经元不止一个
(3) 扩展了激活函数,如sigmod,tanx,softmax,ReLU
配置项
DNN回归
配置项
模型案例
齿轮箱损坏
背景
风电场风机齿轮箱是连接风机主轴和发电机的传动部件,其将主轴的低转速的输入转化成中速或高速发电机所需的输出,是风机中的重要部件之一。
本模型基于AI建模平台,创建风机齿轮箱损坏模型,希望可以通过模型运行结果,及时地预测齿轮箱的状态,更早地发出损坏警告。
数据集介绍
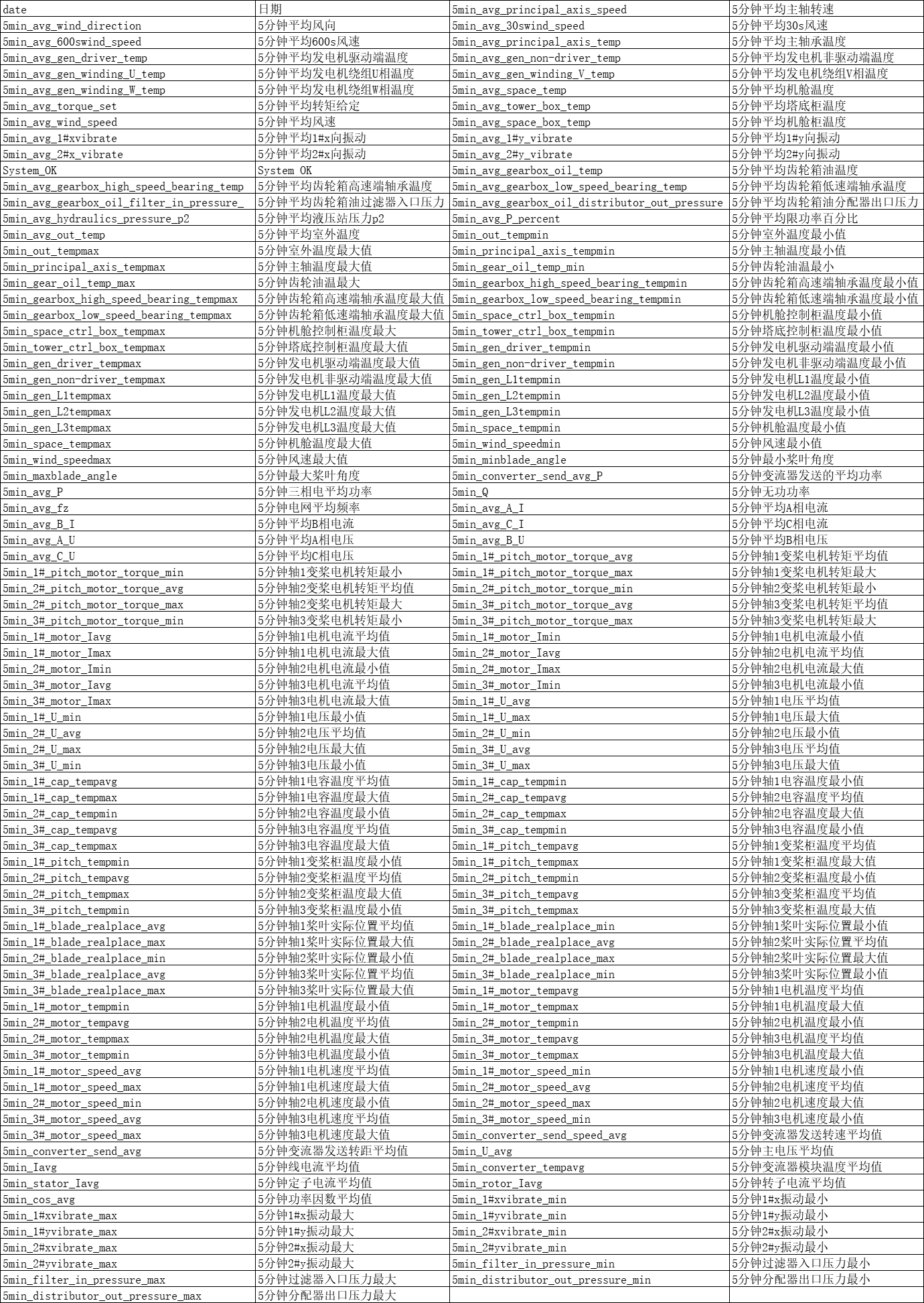
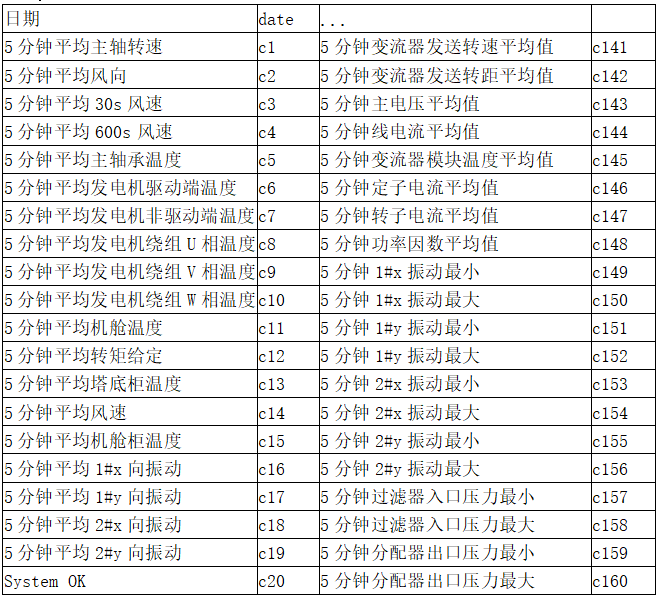
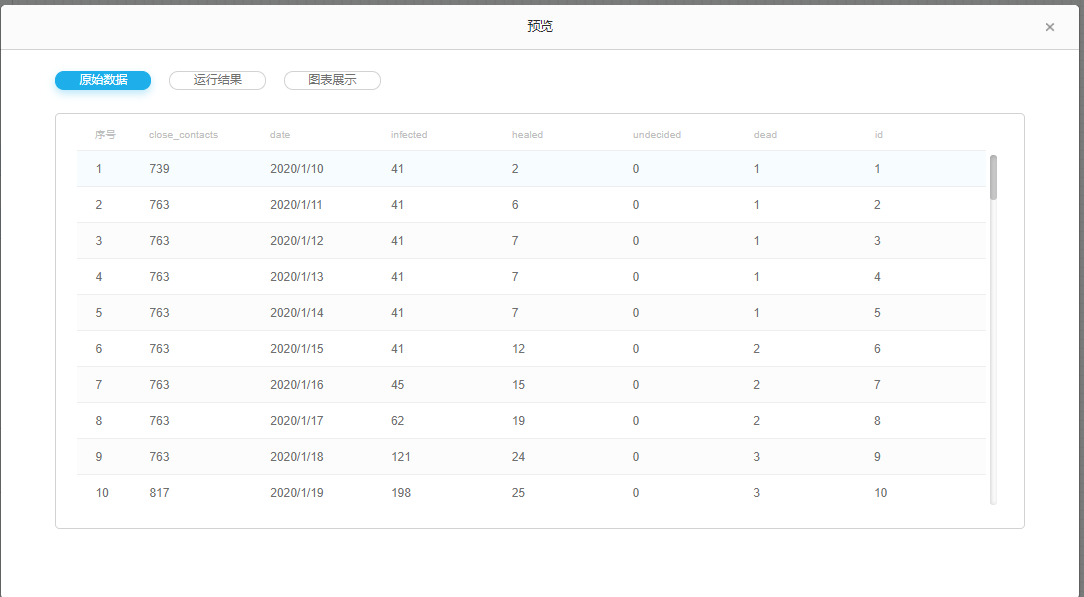
原始数据集为某风场某风机的数据。scada标记了故障发生时间和结束时间。 数据集数据字段如下(所有字段映射关系查看字段映射):
date,5min_avg_principal_axis_speed,5min_avg_wind_direction,5min_avg_30swind_speed,5min_avg_600swind_speed,5min_avg_principal_axis_temp,5min_avg_gen_driver_temp,5min_avg_gen_non-driver_temp,5min_avg_gen_winding_U_temp,5min_avg_gen_winding_V_temp,5min_avg_gen_winding_W_temp,5min_avg_space_temp,5min_avg_torque_set,5min_avg_tower_box_temp,5min_avg_wind_speed,5min_avg_space_box_temp,5min_avg_1#xvibrate,5min_avg_1#y_vibrate,5min_avg_2#x_vibrate,5min_avg_2#y_vibrate,System_OK,...,5min_distributor_out_pressure_max
其字段含义为 :
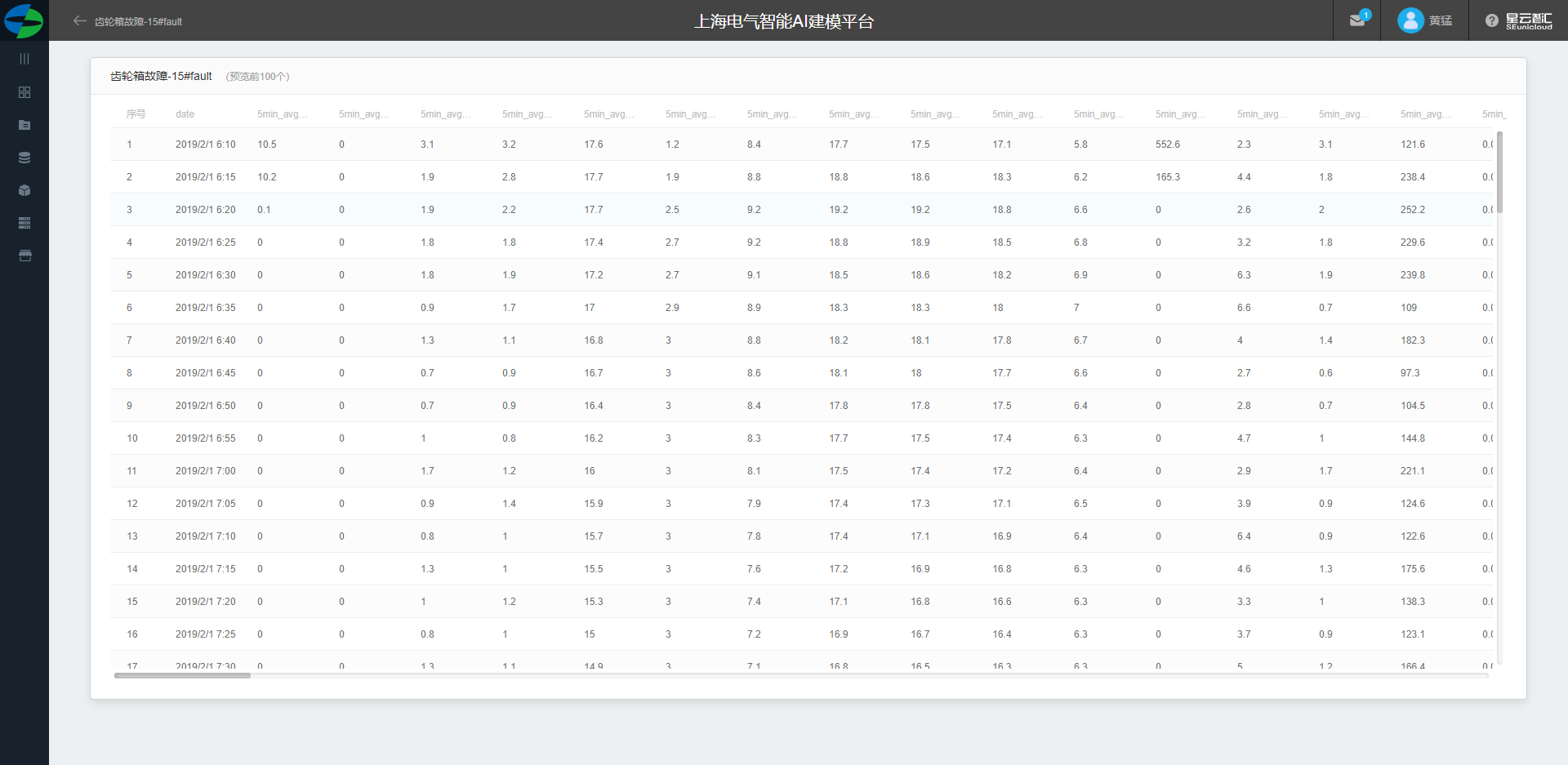
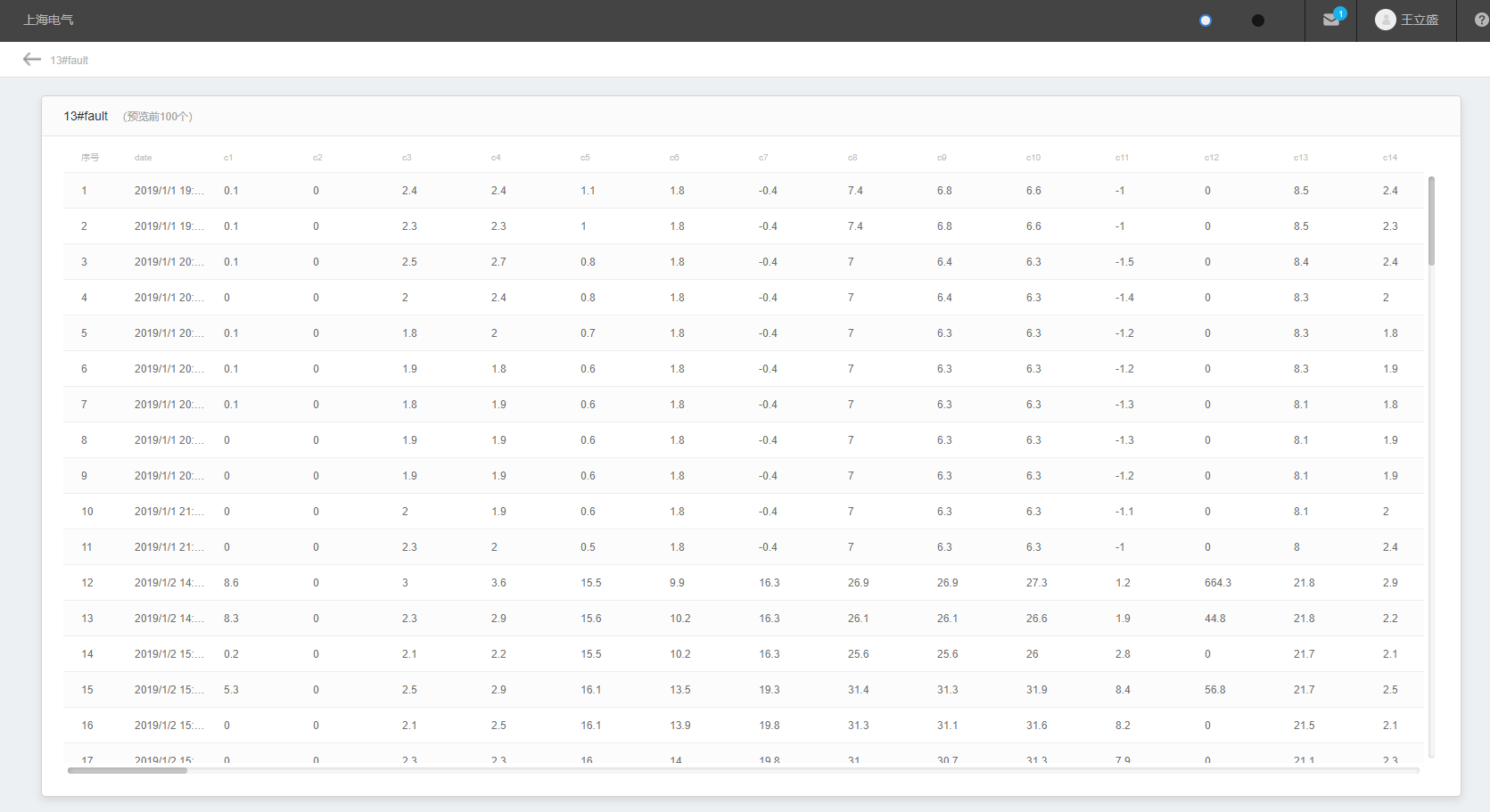
数据集预览
根据故障时间段筛选出所有故障中出现最多的故障做为故障数据,非故障数据作为健康数据。
数据集具体内容部分展示如下:
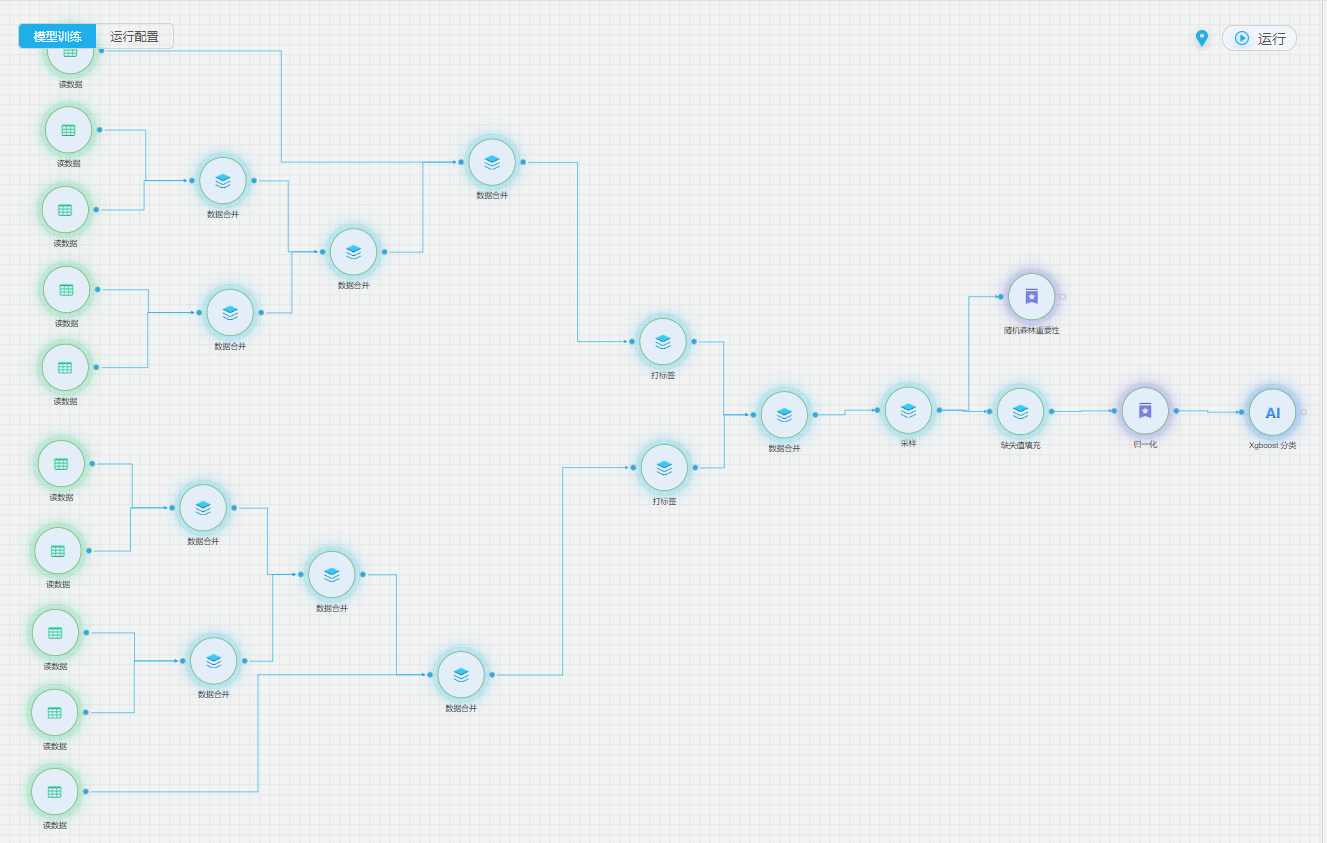
整体流程
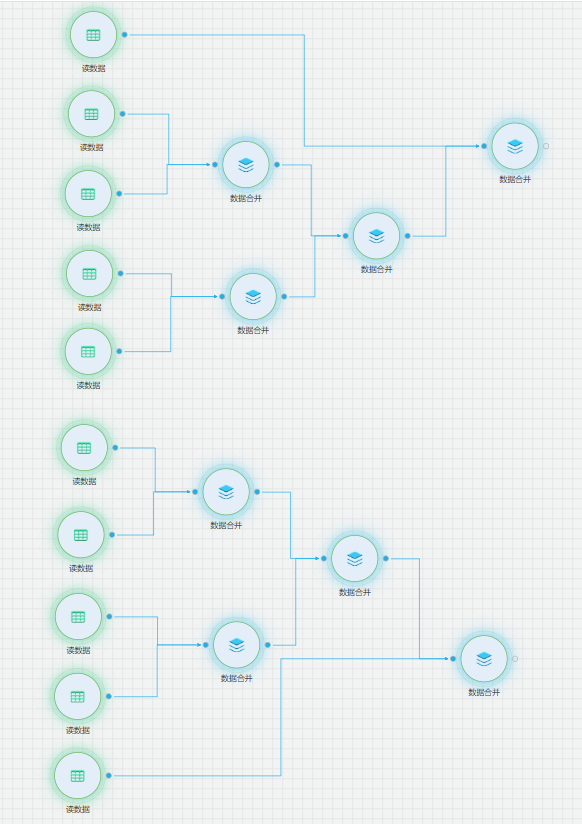
详细流程
通过结合数据挖掘和机器学习的模型,对设备的系统数据进行数据预处理,并建立对历史数据的xgboost机器学习模型,致力于实现设备技术状态的多维关联分析,以及设备故障数据的提前预警。
模型配置
建模分为五部分:数据读取、数据预处理、数据的特征工程、xgboost 模型的训练。首先对数据进行数据清洗、数据的归一化预处理,接着用随机森林特征重要性选出重要特征。预测模型采用了xgboost 模型,通过训练历史数据,实现对未知数据的预测功能。
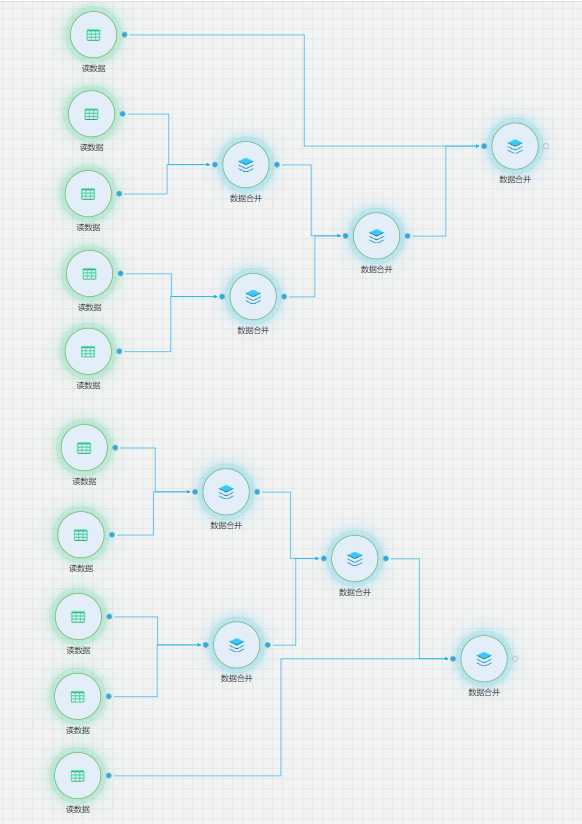
数据源配置
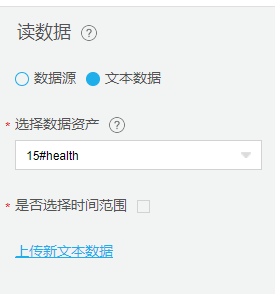
从【源/目录】目录中拖入【读数据表】、从【数据预处理】目录中拖入【数据合并】组件,并进行配置。依次拖入多个【读数据源】组件,分别配置对应的数据资产。并通过【数据合并】组件,将故障数据与健康数据分别两两合并,合并为一份故障数据和一份健康数据。
数据处理
从【数据预处理】中拖入【打标签】、【缺失值填充】、【归一化】、【采样】组件,配置相关参数。对数据进行标准化处理。
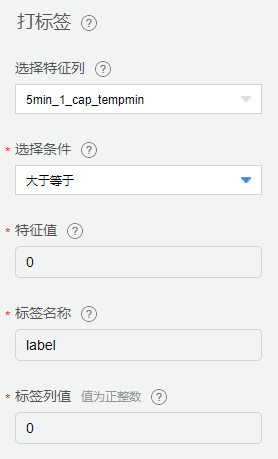
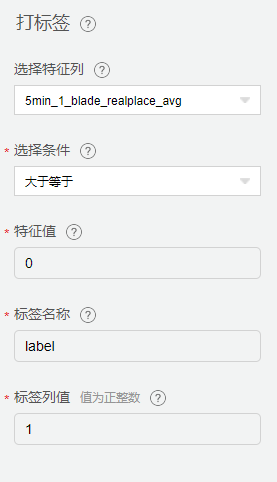
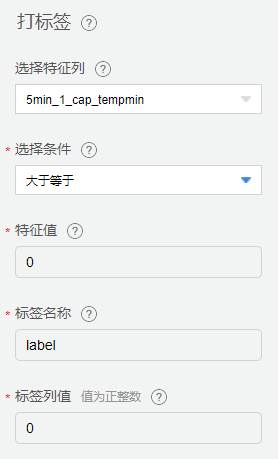
打标签
分别对健康数据和故障数据进行打标签,标签列名为label,健康数据标记为0,故障数据标记为1。
缺失值填充
采集数据中不可避免的会遇到某些特征出现空值的情况,这里我们使用【缺失值填充】用来将空值替换均值。
缺失值填充配置
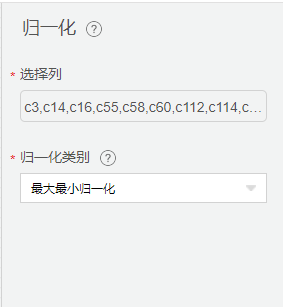
归一化
【归一化】主要作用是: 把数据变成(0,1)或者(0,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速的计算。
归一化配置
采样
由于采集数据中健康数据占比较多,而故障数据占比较小。会导致模型结果倾向于健康数据,训练效率低下和简单的负面样本引发整个模型表现不佳的问题。因此,我们采用【采样】,使用上采样的方式,控制健康数据与故障数据的数据比例。
采样配置
特征工程
从【机器学习】中拖入【随机森林重要性】组件,配置相关参数。
将新的数据集通过随机森林,实现特征的重要性排名,筛选出重要特征。为后续模型组件特征列选择提供指导。
随机森林重要性配置
运行后结果如下 :
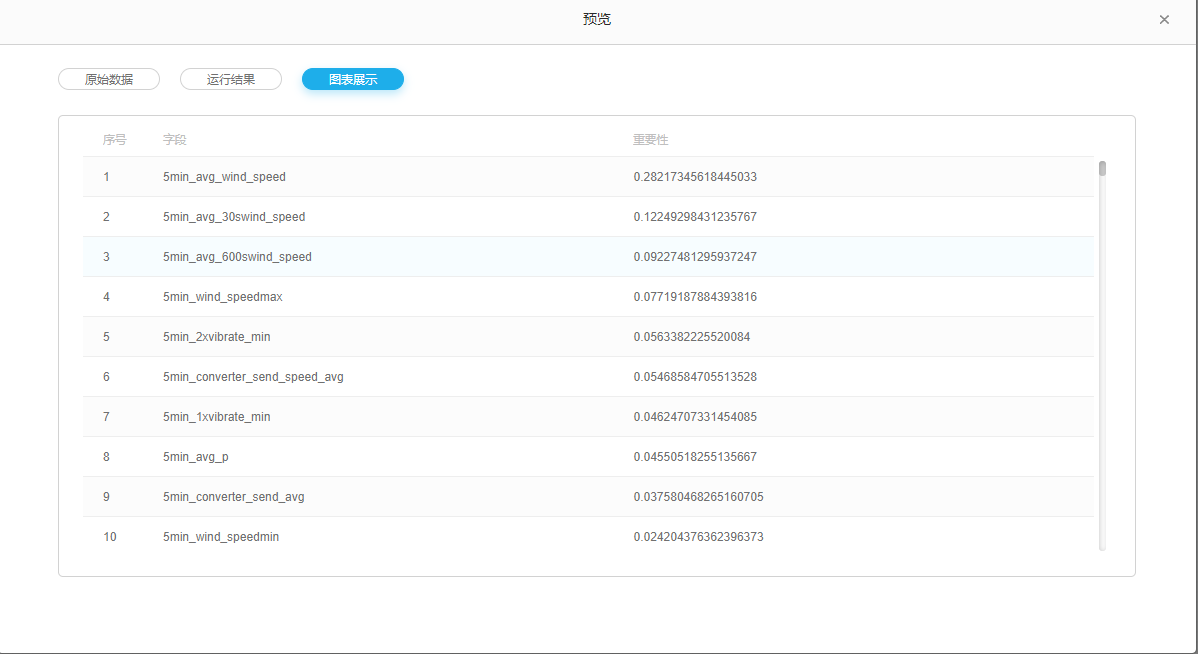
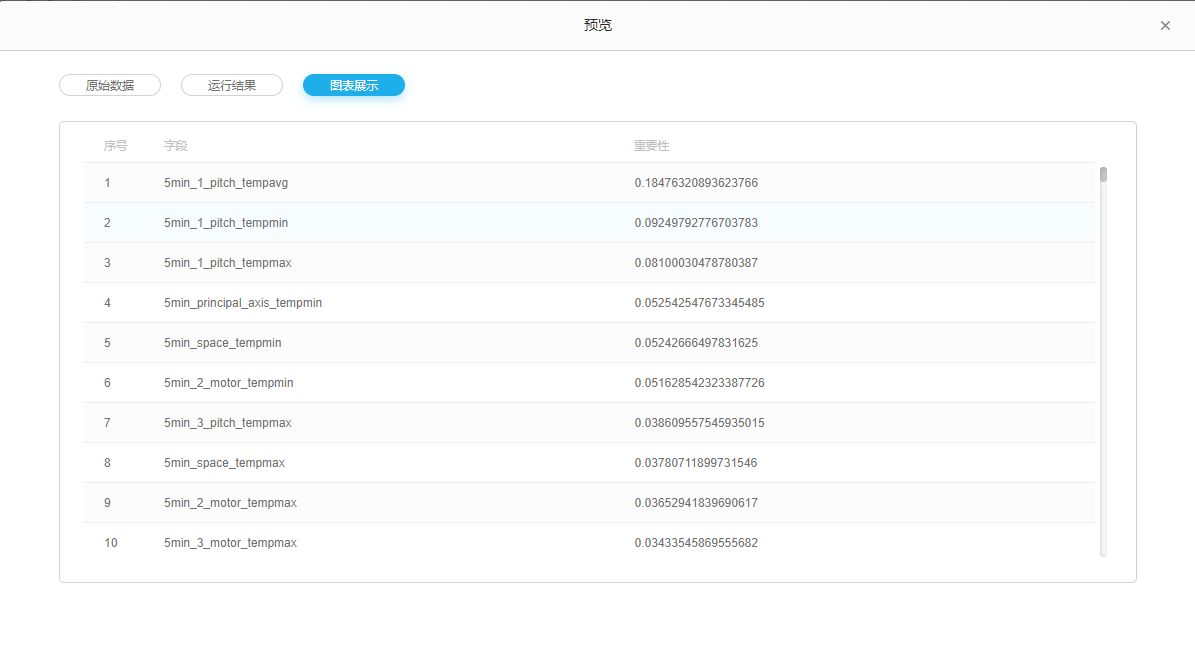
随机森林特征重要性排名
分类器
从【机器学习】中拖入【Xgboost 分类】组件,配置相关参数。
Xgboost 分类优势
Xgboost 分类具有以下优势:
(1) 正则化项防止过拟合。 xgboost在目标函数中显示的加上了正则化项,基学习为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,正则化项防止过拟合。
(2) GB中使用Loss Function对f(x)的一阶导数计算出伪残差用于学习生成fm(x),xgboost不仅使用到了一阶导数,还使用二阶导数,损失更精确,还可以自定义损失。
(3) XGBoost的并行优化,XGBoost的并行是在特征粒度上的
(4) 考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率
(5) 支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
Xgboost 分类配置
配置【Xgboost 分类】组件,其中特征列选择随机森林重要性排名中权重大于1%的特征列。测试样本占比采用0.25,详细配置如下:
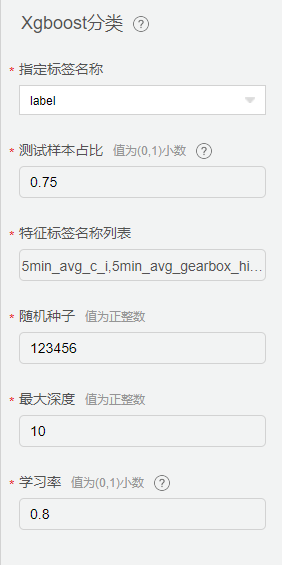
Xgboost 分类配置
模型训练及评估
在【模型组件】右击,选择运行一种运行方式,组件可单独运行,也可按顺序依次执行。所有组件运行成功后,会自动生成模型文件。
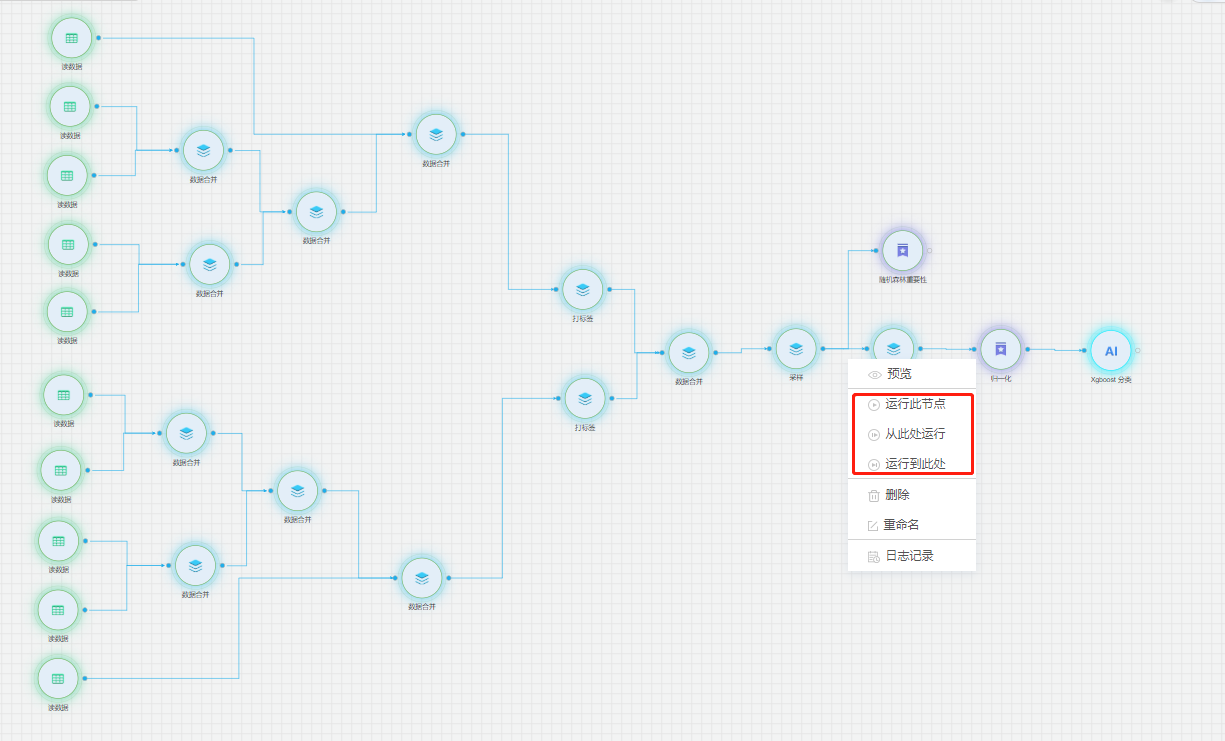
在【模型类型组件】右击,点击【预览】-> 【图表展示】可以展示模型的评估信息。
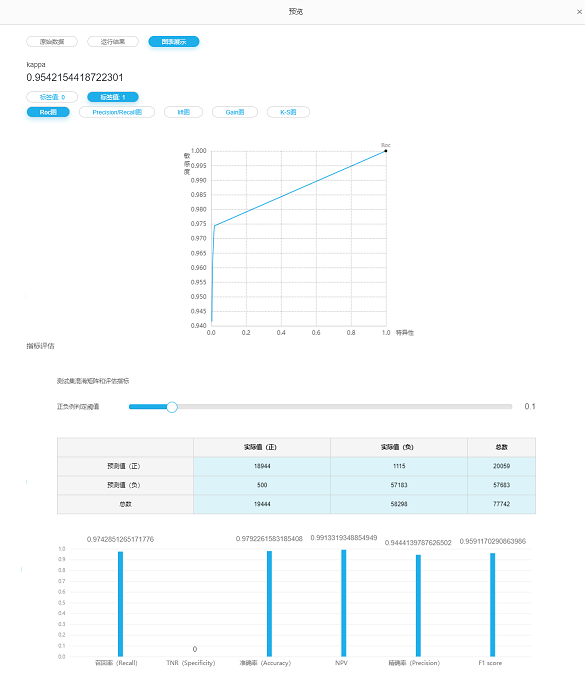
模型评估结果
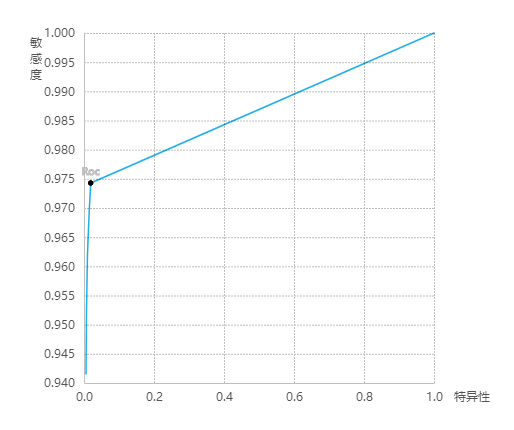
ROC曲线
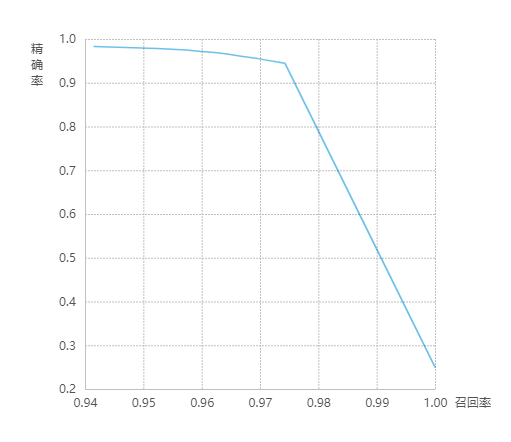
P-R图
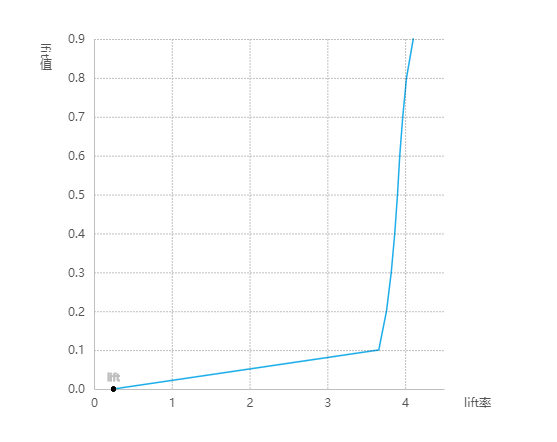
lift图
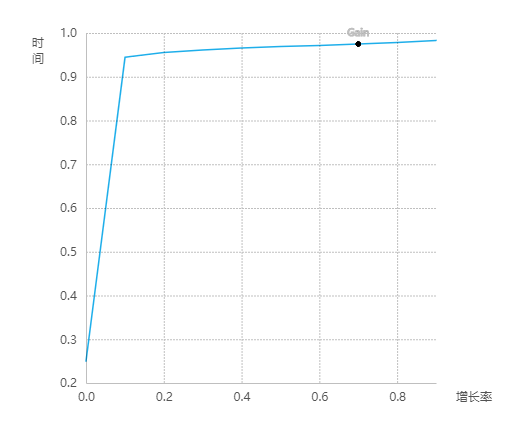
Gain图
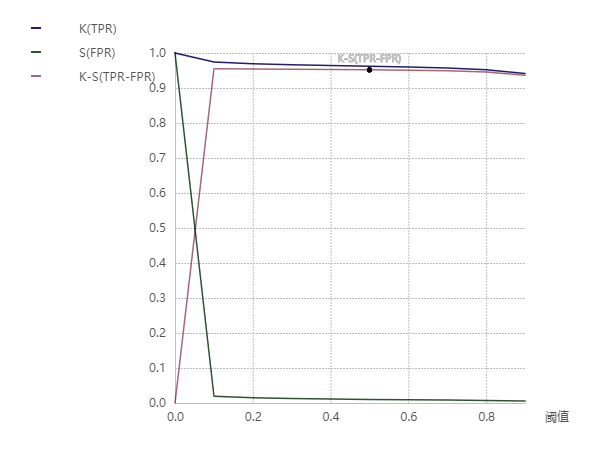
K-S图
模型发布与部署
鼠标单击左侧导航栏 [模型管理] ,选择[模型发布及部署]
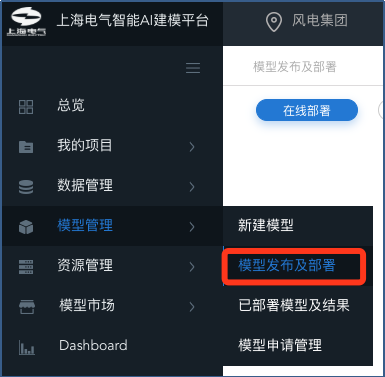
模型发布界面
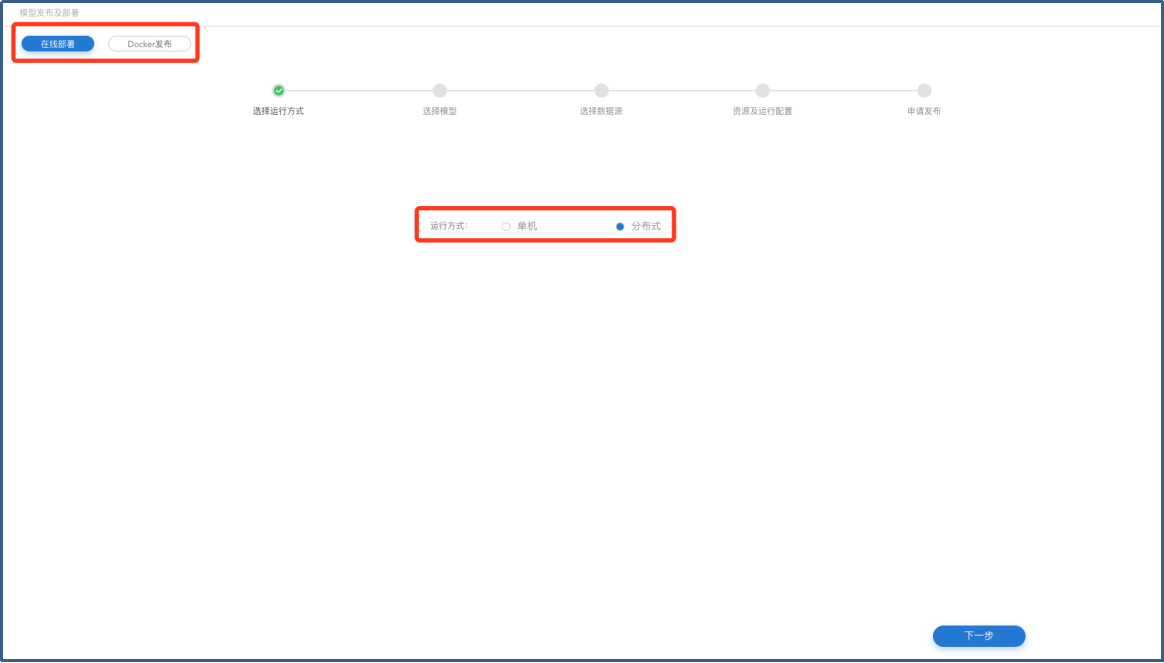
进入【模型发布及部署】页面选择发布类型【在线发布/Docker发布】,以及运行方式【单机/分布式】,单击【下一步】按钮进入【选择模型】页面。
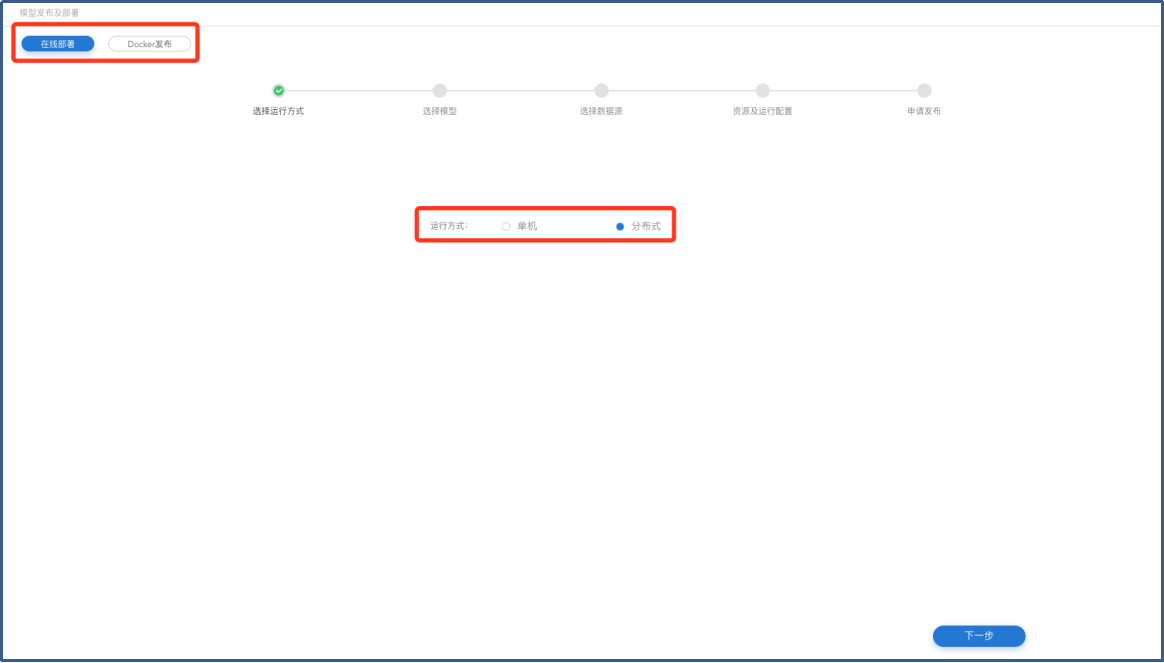
模型发布-运行方式选择
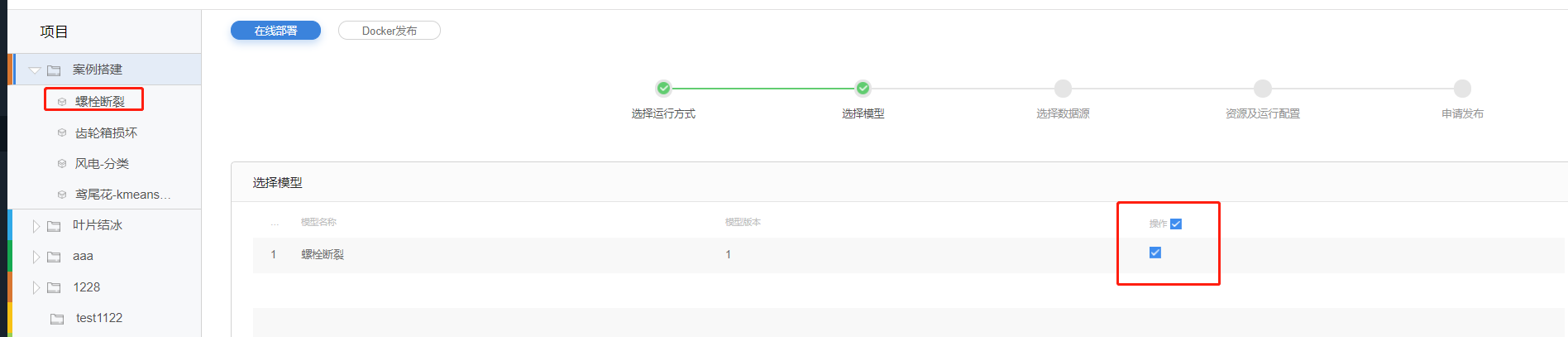
在【选择模型】页面,【项目】菜单中选择要发布的模型,并在【选择模型】页面勾选模型版本,单击【下一步】进入【选择数据源】页面。
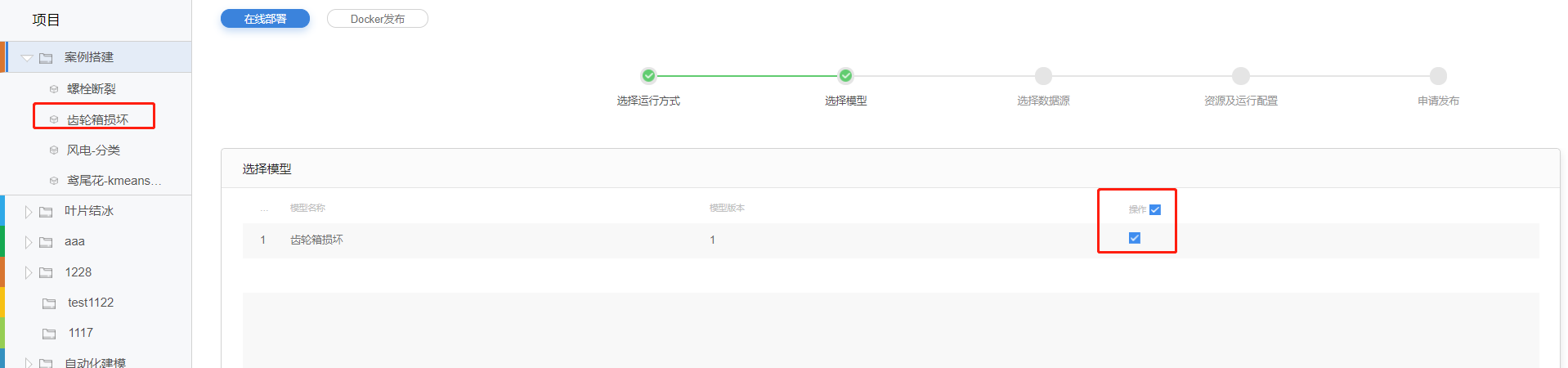
模型发布-模型选择
在【项目】菜单栏选择数据源,并在【选择数据源】页面勾选选择部署所需的数据,查看数据源信息,选择数据,点击下一步进入【资源及运行配置】。
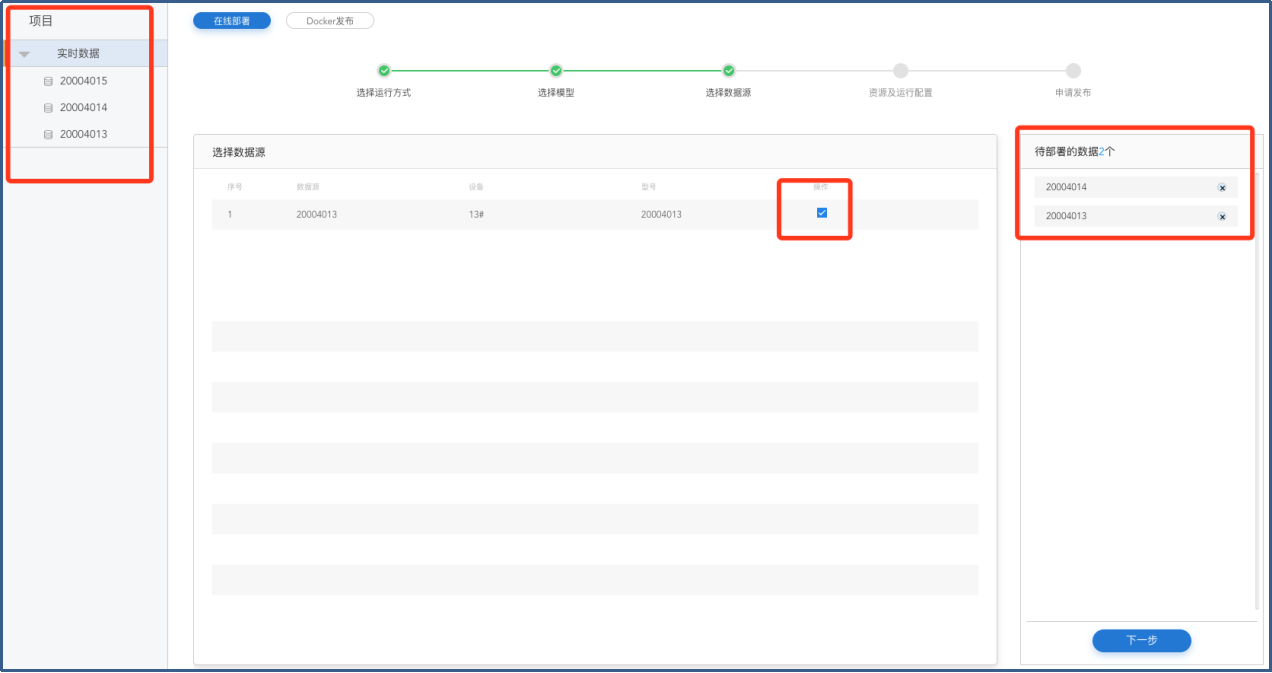
模型发布-数据源选择
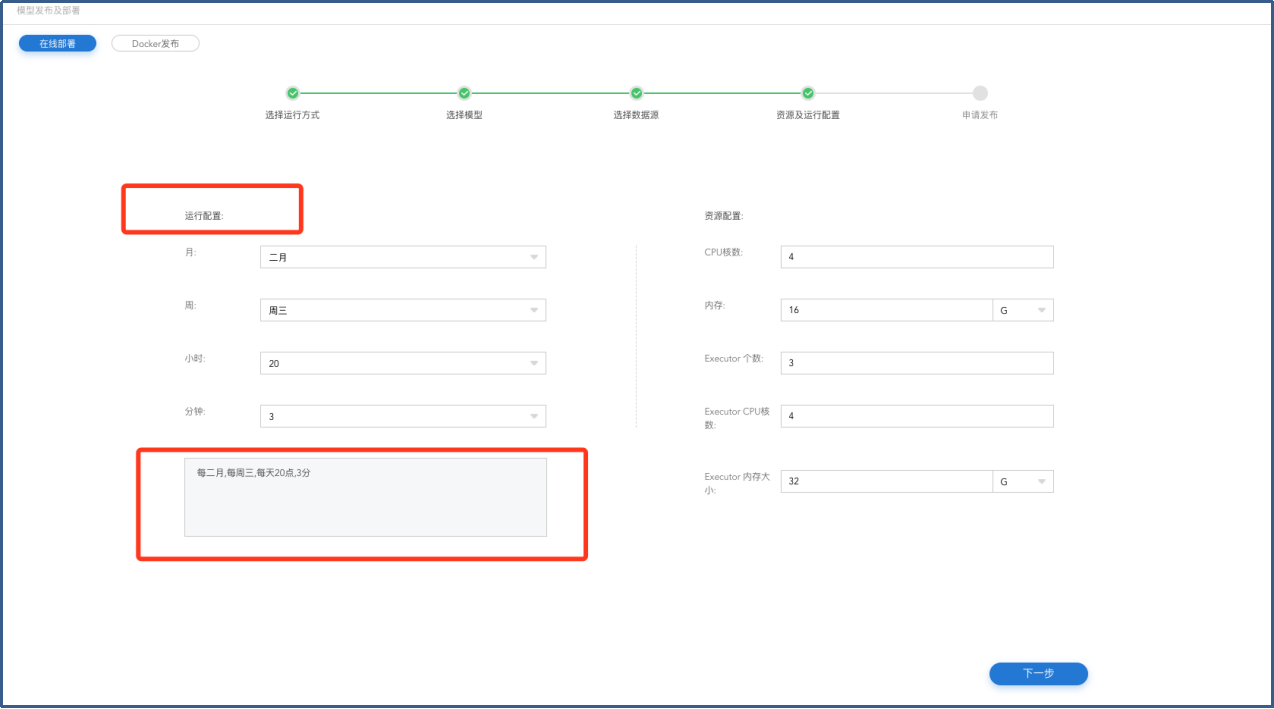
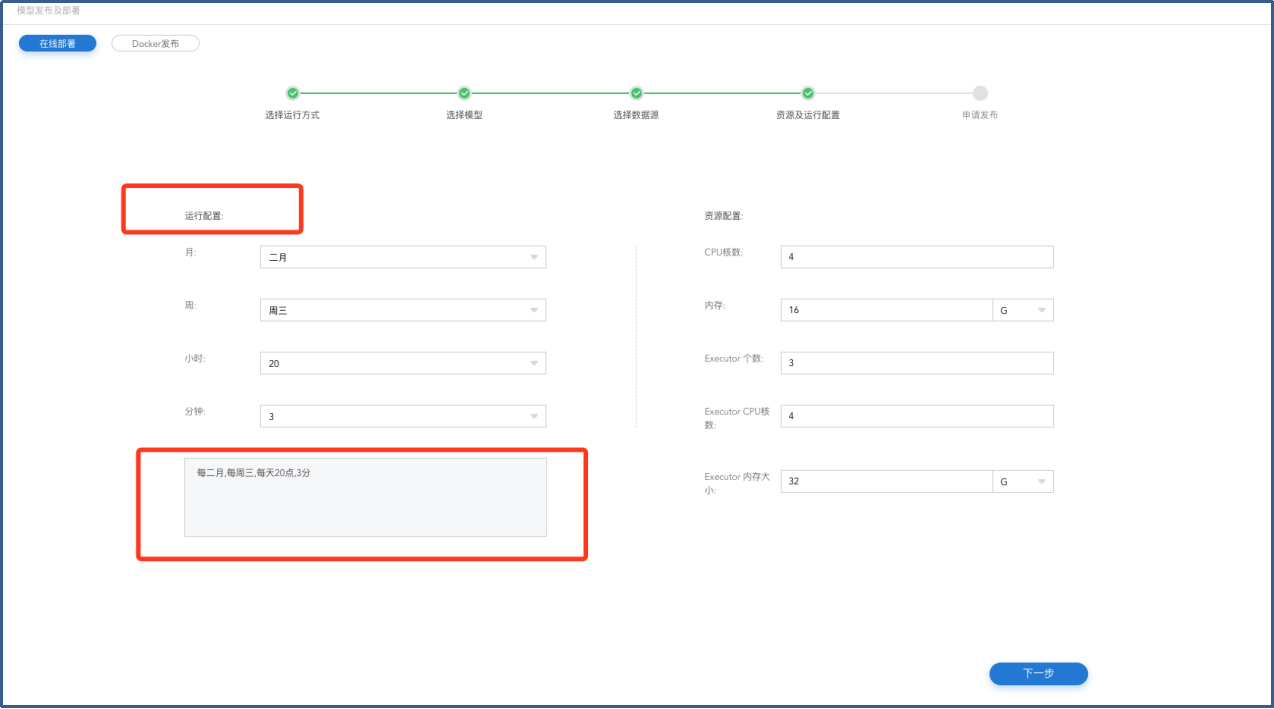
在【资源及运行配置】页面填写【运行配置】和【资源配置】,点击下一步进入【申请发布】页面。
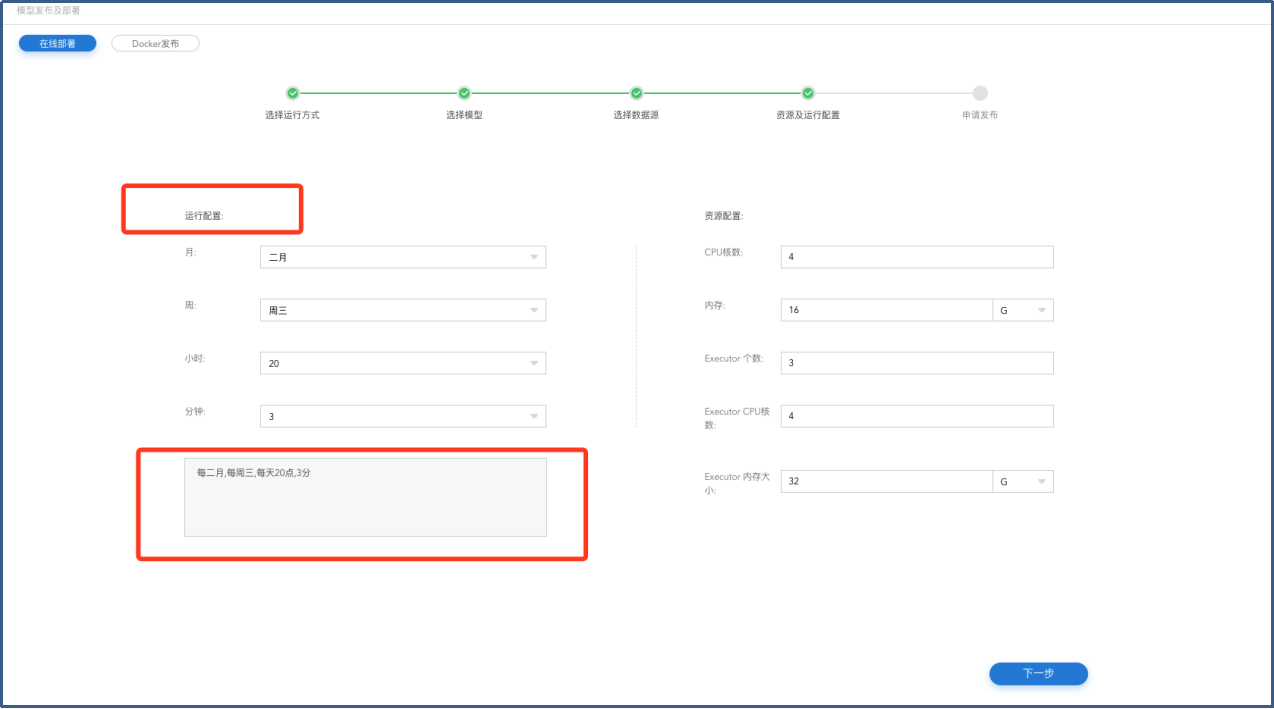
模型发布-资源及调度周期配置
在【申请发布】页面,填写【任务名称】、【描述】,点击【确定】。
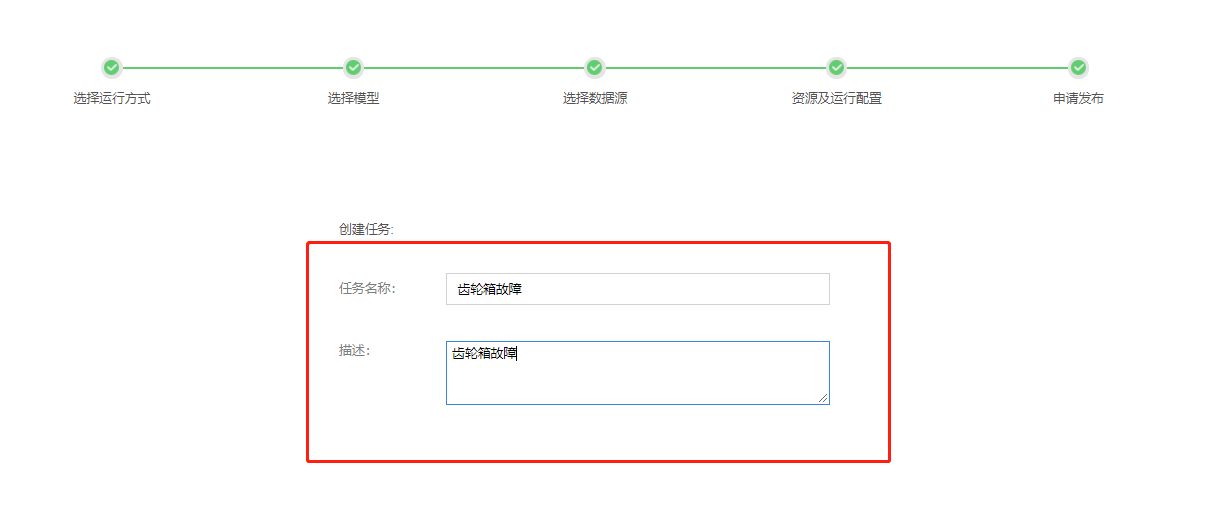
模型发布-创建任务
点击【模型管理】,选择【模型申请管理】页面,可查看申请部署模型的情况。
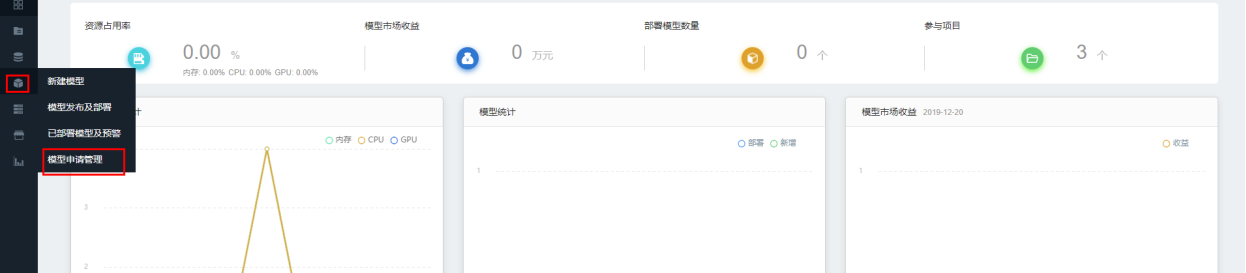
模型申请部署查看界面入口
模型审批通过后,可以在【已部署模型和预警】详情界面查看模型产生的预警及部署相关信息。

已部署模型运行结果
已部署模型及结果
鼠标单击左侧导航栏【模型管理】,点击【模型发布及部署】菜单,进入已部署模型【总览】页面。
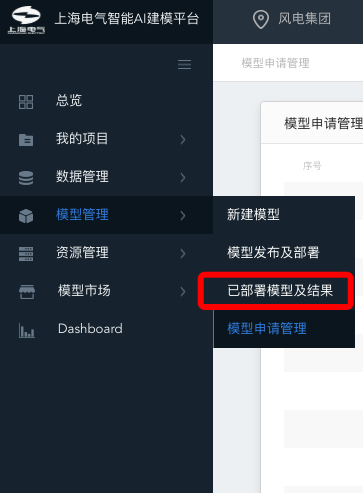
已部署模型查看界面入口
在【已部署模型及结果总览】页面查看已部署模型统计及运行结果信息,点击【模型结果】/【已部署模型】进行页面切换。

模型运行结果
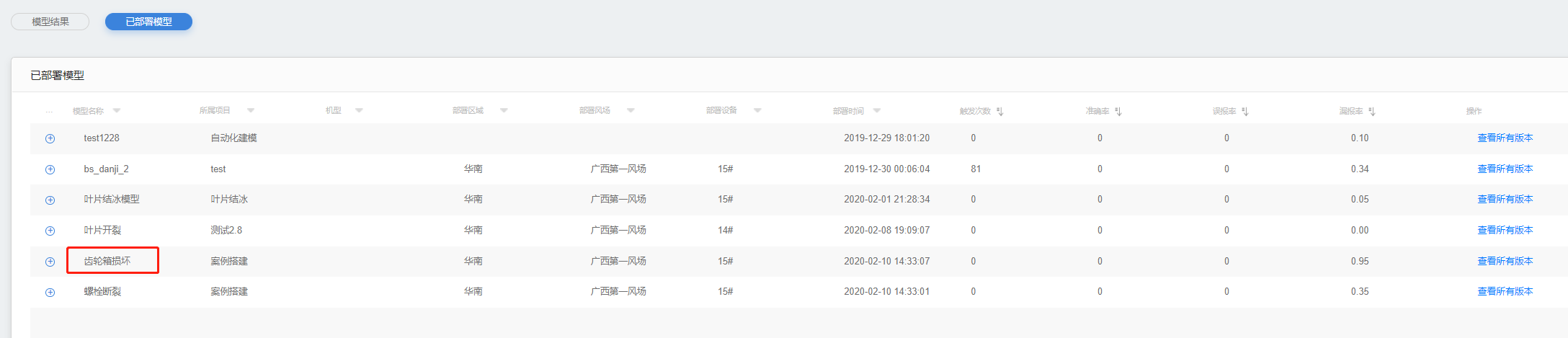
已部署模型
字段映射
锂电池自编码器
背景
当前,电动汽车飞速发展,锂电池作为电池车的动力,具有高能量密度、无自放电效应、可循环利用、制造简单、容易携带、使用寿命长等诸多优点,使其成为混合动力汽车及电动汽车的首选方案。然而,如果锂离子电池在使用过程中管理不当,导致降低电池的能量利用率和缩短锂电池的使用寿命,甚至可能会导致严重的事故或电池爆炸。因此,需要一个有效的电池管理系统监测电池状态,在使用锂离子电池时保证电池的安全运行。荷电状态作为电池性能的重要状态之一,是锂电池管理必不可少的参数,准确和可靠的荷电状态估算一直是一个长期的挑战。准确的预测电池状态能够优化电池的性能,延长电池的使用寿命。
本模型基于AI建模平台,创建锂电池自编码器-支持向量机回归模型,希望可以通过模型运行结果,及时地预测锂电池的状态,优化电池的性能,延长电池的使用寿命。
数据集介绍
原始数据集为某锂电池的相关数据,数据集数据字段如下:
数据集具体内容部分展示如下:
整体流程
(1) 首先我们通过相关系数矩阵、直方图、散点图的方式探索数据的分布情况。
(2) 数据经过缺失值填充与归一化进行预处理。
(3) 将处理后的数据经过自编码器,输出解码后的内容,并计算均方差。
(4) 根据自编码器的输出及均方差,训练支持向量机回归模型,用来预测随着时间增长,均方差的变化趋势。当有偏离预测值较大范围时,可能是电池发生了故障情况。
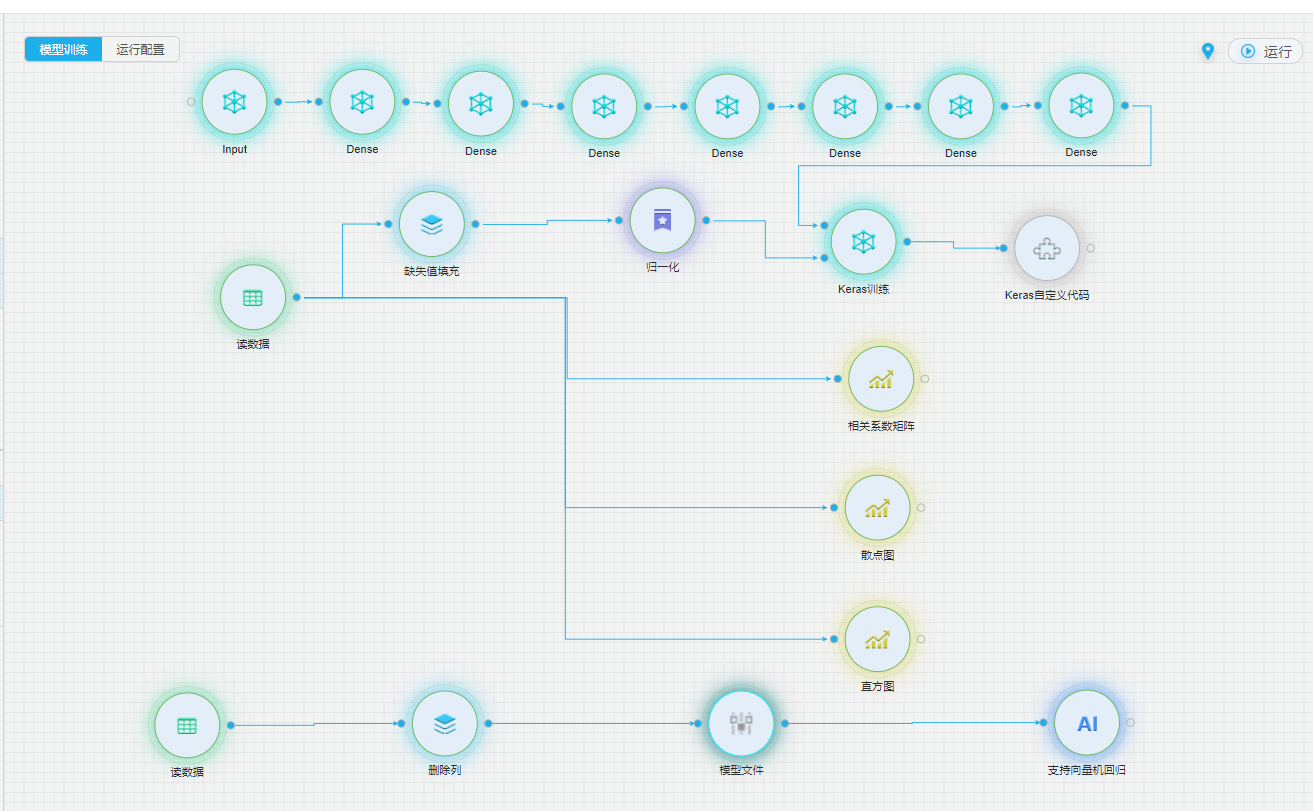
详细流程
数据探索
主要从两方面入手,一方面是数据分布情况,可以通过计算该变量的直方图了解;另一方面,是该变量与其他特征变量间的关系,通过相关系数矩阵可以获得。此外,还可以通过散点图观察数据的详细特点。
官方图
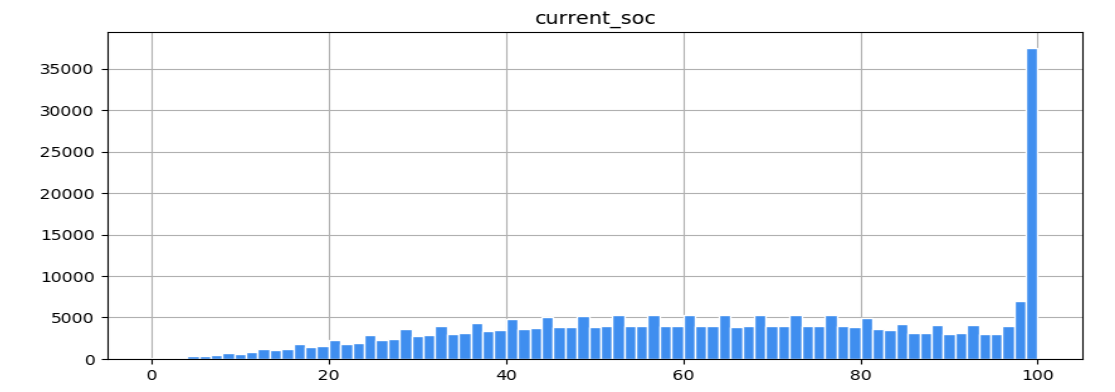
直方图中我们选择除了battery_id 与 record_time 之外的所有列,查看各个字段的数据分布情况:
以current_soc为例,可以看到,电量分布在90-100的最多,0-20的最少,40-80的基本平均分布。
有经验的运营人员通过数据分析,也可以直观的发现一些运营中的问题,也可以与天气数据及其他生产数据进行关联分析。例如,从储能设备的电量分布可以看出,目前大多数的储能设备处于饱和状态。
相关系数矩阵
可以看到个字段间的相关系数情况,如图,除了有具体的数字,还用颜色进行了标识,绿色(深色)为+1,红色(深色)为-1,0用白色表示,颜色越淡说明线性相关性越弱,绿色越深说明正相关性越强,红色越深说明负相关性越强。
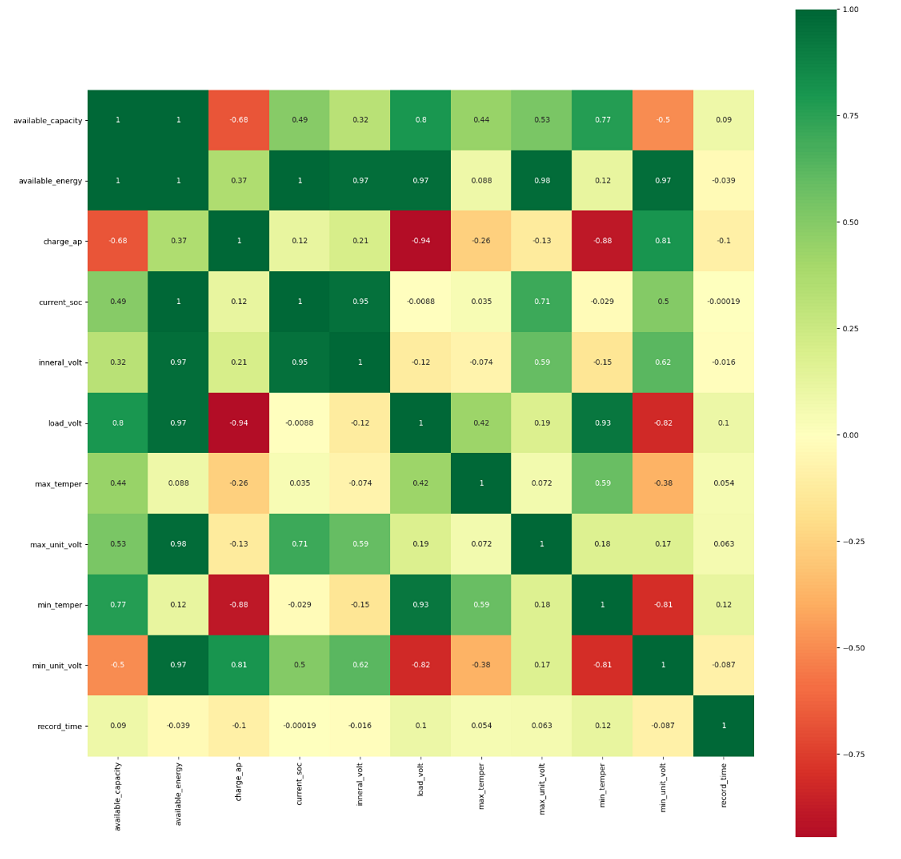
相关系数矩阵
从图中可以看出如下特点:
(1) available_energy 与available_capacity、current_soc、load_volt、inneral_volt、max_unit_volt、min_unit_volt成正相关。
(2) Charge_ap 与 load_volt、min_temper负相关性较强,对于强相关的特征,在建模过程中可以只选择其中一个特征列参与模型训练。
散点图
这里我们已选择available_energy、inneral_volt、max_temper为例。可以清晰的看到某变量在其他变量的维度上数据分布的情况。
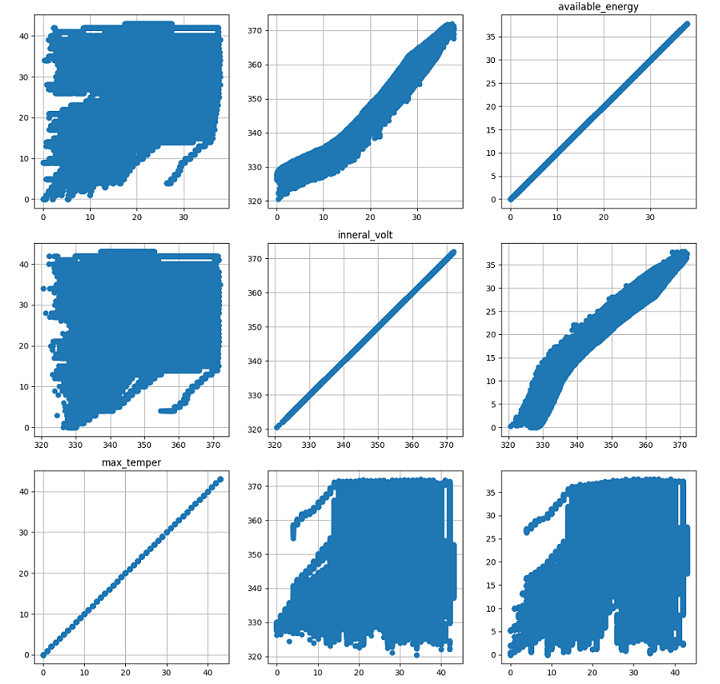
散点图
自编码
自编码器是一种无监督的学习算法,主要用于数据的降维或者特征的抽取。自动编码器是一种无监督的神经网络模型,它可以学习到输入数据的隐含特征,这称为编码(coding),同时用学习到的新特征可以重构出原始输入数据,称之为解码(decoding)。从直观上来看,自动编码器可以用于特征降维,类似主成分分析PCA,但是其相比PCA其性能更强,这是由于神经网络模型可以提取更有效的新特征。除了进行特征降维,自动编码器学习到的新特征可以送入有监督学习模型中,所以自动编码器可以起到特征提取器的作用。
在本模型中,我们采用自编码器,可以通过数据降维和特征抽取的方式学习到更多数据中的隐含特征。
由于各个电池的文件字段存在缺失的情况,我们先将数据经过缺失值填充,然后再经过归一化,把数据变成(0,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速的计算。
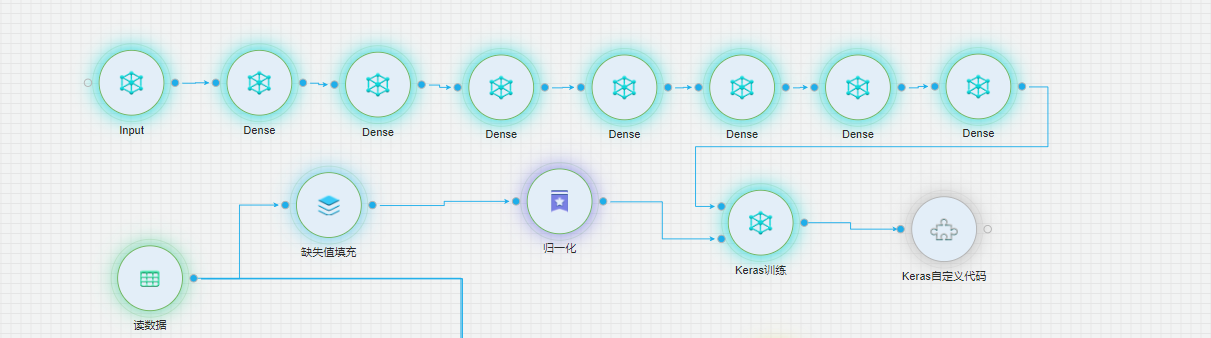
模型搭建我们采用current_soc、inneral_volt、charge_ap、max_temper min_temper、max_unit_volt、min_unit_volt、available_energy 8个变量,自编码器我们采用7层Dense稀疏层,层数分别为8,6,4,2,4,6,8。
数据经过keras训练后,会将原有的输入与经过自编码器转换后的数据输出。然后我们通过keras自定义代码,计算出每行的均方差,输出每行数据的均方差,并绘制曲线。
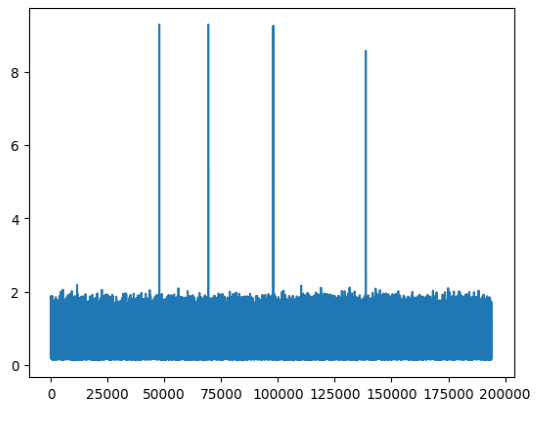
均分差曲线
支持向量机回归
通过对自编码器输出数据,每行数据的均方差,我们使用支持向量机回归来拟合均方差的走向趋势,可以观察电池的状态的变化趋势。
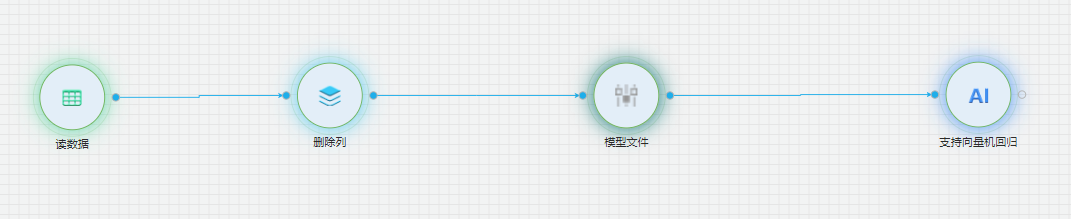
支持向量机回归训练流程
支持向量机的实现原理是:通过某种事先选择的非线性映射(核函数)将输入向量映射到一个高维特征空间,在这个空间中构造最优分类超平面。
这里我们选择mse作为标签列,id作为特征值,内核参数选择径向基函数。得到模型的预测结果:
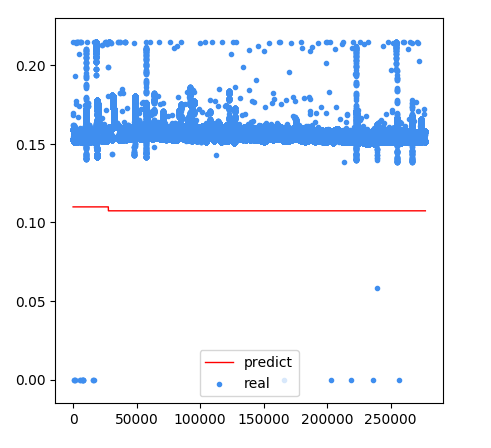
支持向量机回归真实值与预测曲线
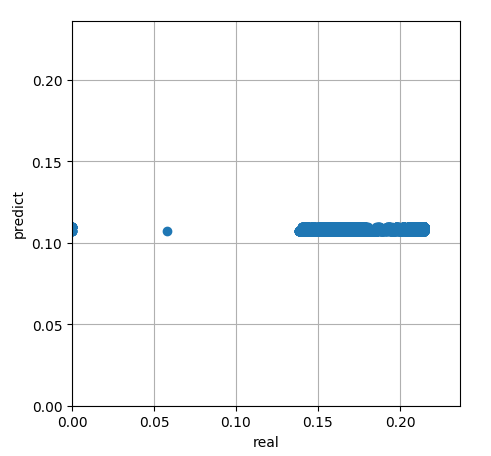
支持向量机真实值与预测值散点分布图
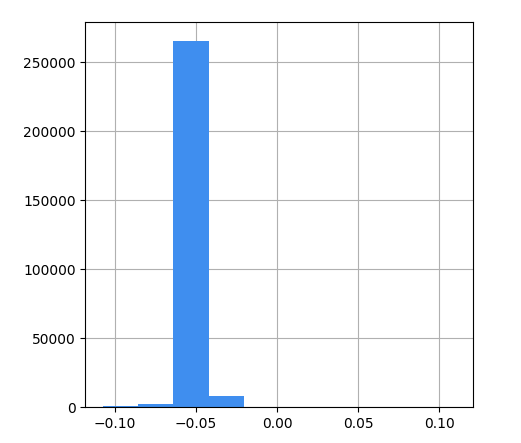
支持向量机残差直方图
风机叶片结冰
背景
风电场风机叶片结冰是风电领域的一个全球性的难题,叶片结冰会影响风机的载荷和功率输出,使其偏离正常工况导致减小风机的使用寿命,当结冰严重的时候会造成叶片断裂,威胁风电场人员安全。当前,对于风机叶片结冰故障的诊断主要技术手段是比较风机实际功率与理论功率之间的偏差,当偏差达到一定值后触发风机的报警,但该方法的缺点是不能在结冰的早期诊断出结冰现象,当触发报警时往往已经发生了叶片大面积结冰。针对现有的技术手段原理过于简单导致预测准确率低,预测结果的粗糙以致不能预测出早期的叶片结冰状态等问题。
数据集介绍
原始数据集为某风场某风机的数据,(2017年3月4日到2017年3月16日)。scada标记了故障发生时间和结束时间。 数据集数据字段如下:
turID,rectime,iActivePoweiSetPointValue,iAvailabillityToday,iAvailabillityTotal,iBlade1TempBattBox_1sec,iBlade1TempInvBox_1sec,iBlade1TempMotor_1sec,iBlade1TempPMCHeatsink_1sec,iBlade1TempPMMHeatsink_1sec,iBlade2TempBattBox_1sec,iBlade2TempInvBox_1sec,iBlade2TempMotor_1sec,iBlade2TempPMCHeatsink_2sec,iBlade2TempPMMHeatsink_2sec,iBlade3TempBattBox_1sec,iBlade3TempInvBox_1sec,iBlade3TempMotor_1sec,iBlade3TempPMCHeatsink_3sec,iBlade3TempPMMHeatsink_3sec,iBPLevel,iCableTwistTotal,iCosPhi,iCosPhiSetValue,iFiequency,iGenPower,iGenSpeed,iIL1_690V,iIL2_690V,iIL3_690V,iKWhOverall_h,iKWhOverall_l,iKWhThisDay_h,iKWhThisDay_l,iNacellePositionLtd,iNacellePositionTotal,iOperationHoursDay,iOperationHoursOverall_h,iOperationHoursOverall_l,iPitchAngle1,iPitchAngle2,iPitchAngle3,iReactivePower,iSetValueGenSpeed,iSetValuePitchAngle,iTemp1GearOil_1sec,iTempCabinetNacelle_1sec,iTempCabinetTowerBase_1sec,iTempCntr_1sec,iTempGearBearDE_1sec,iTempGearBearNDE_1sec,iTempGenBearDE_1sec,iTempGenBearNDE_1sec,iTempGenCoolingAir_1sec,iTempGenStatorU_1sec,iTempGenStatorV_1sec,iTempGenStatorW_1sec,iTempHub_1sec,iTempMV_1sec,iTempNacelle_1sec,iTempOutdoor_1sec,iTempRotorBearA_1sec,iTempRotorBearB_1sec,iTempTowerBase_1sec,iTempTransformer690_400V_1sec,iTurbineOperationMode,iUL1_690V,iUL2_690V,iUL3_690V,iVaneDiiection,iVibrationY,iVibrationZ,iwindDirection,iWindSpeed,iYPLevel,SCW001,SCW002,SCW003,SCW004,SCW005,SCW006,SCW007,SCW008,SCW009,SCW010,SCW011,SCW013,SCW014,SCW015,SCW016,SCW017,SCW018,SCW019,SCW020,SCW021,SCW022,SCW023,SCW024,SCW025,SCW026,SCW027,SCW028,SCW029,SCW030,SCW031,SCW032,SCW033,SCW034,SCW035,SCW036,SCW038,SCW039,SCW040,SCW041,SCW042,WT_Faultcode,WT_Runcode,entercount,TurbineStatus,EnterType,iWindSpeed1,iWindSpeed2,iVaneDirection1,iVaneDirection2,bYawCCW_RemCOM,bYawCW_RemCOM,iRotorSpeedPDM,iBlade1MotorCurrent,iBlade2MotorCurrent,iBlade3MotorCurrent,iPitchSpeedBlade1,iPitchSpeedBlade2,iPitchSpeedBlade3,iWindSpeed_real,iWindSpeed_real_30s,iWindSpeed_real_10min,collectorCount
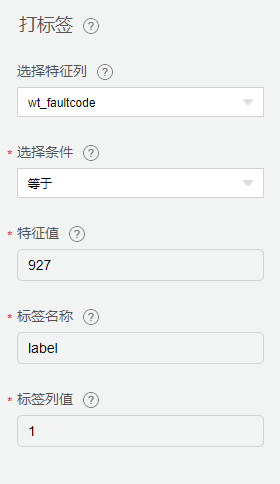
其中 WT_Faultcode 为风机故障码,故障码为0时表示正常,927表示叶片结冰。
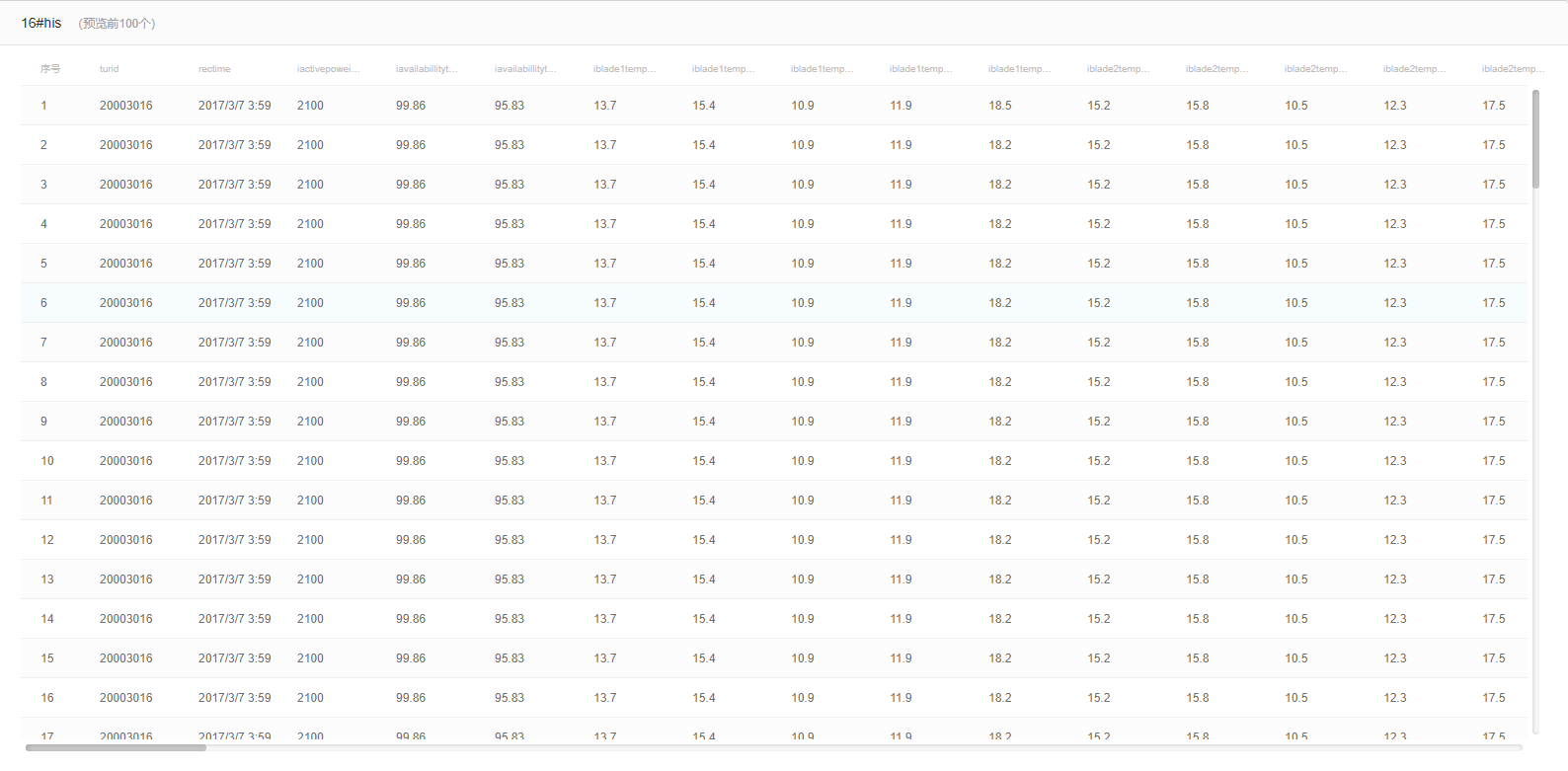
数据集具体内容部分展示如下:
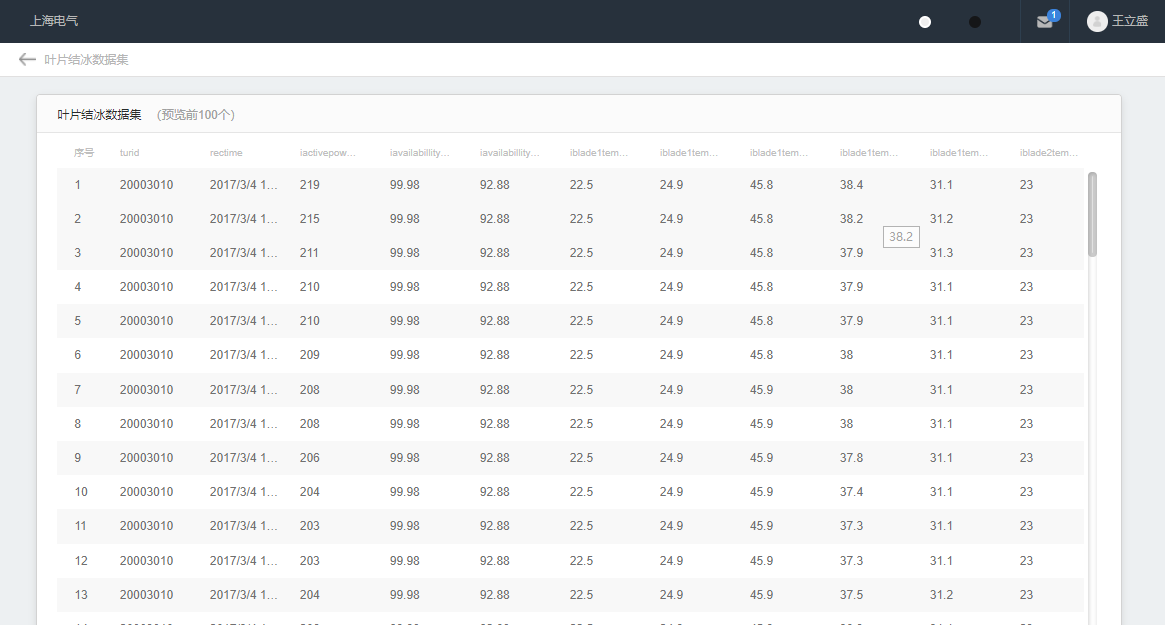
整体流程
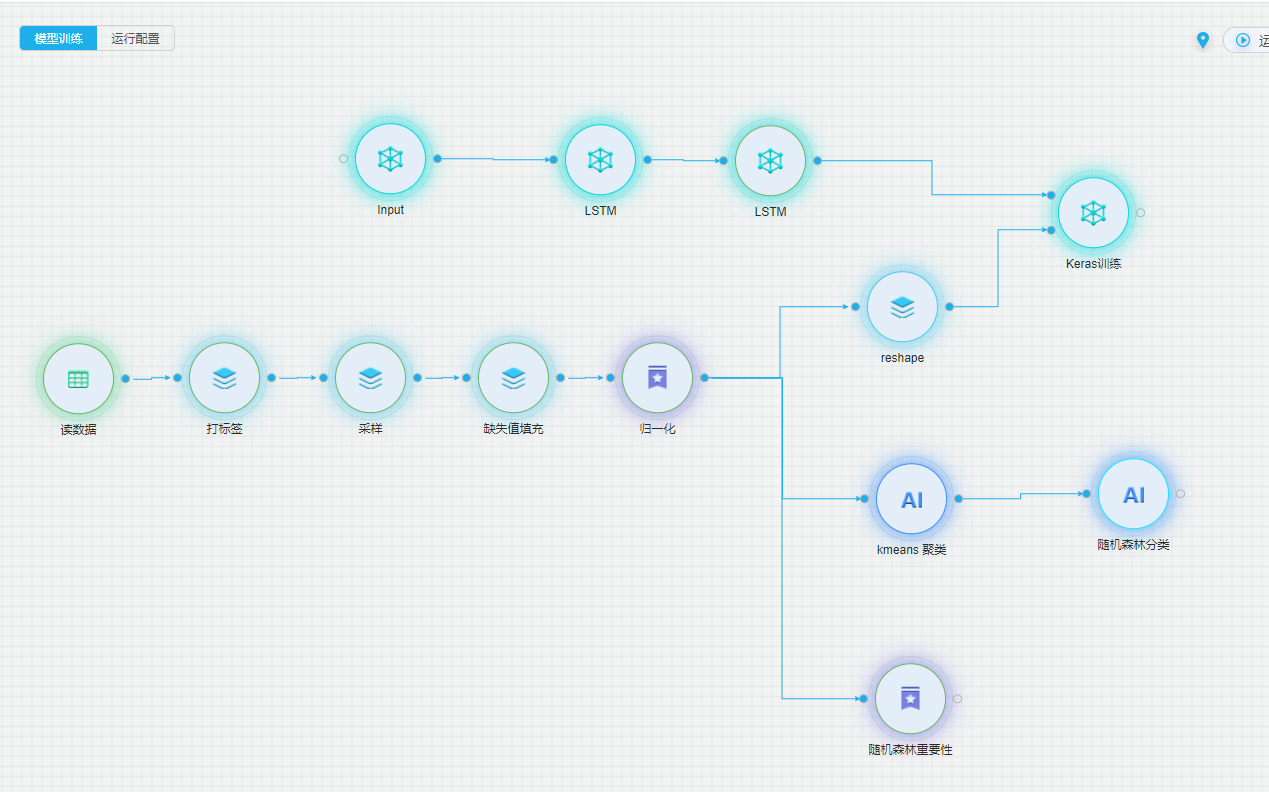
详细流程
通过结合数据挖掘和深度学习的模型,对设备的系统数据进行数据预处理,并建立对历史数据的LSTM深度学习模型,致力于实现设备技术状态的多维关联分析,以及设备故障数据的提前预警。
数据上传
(1) 点击【我的项目】->【XX项目】->【添加数据】
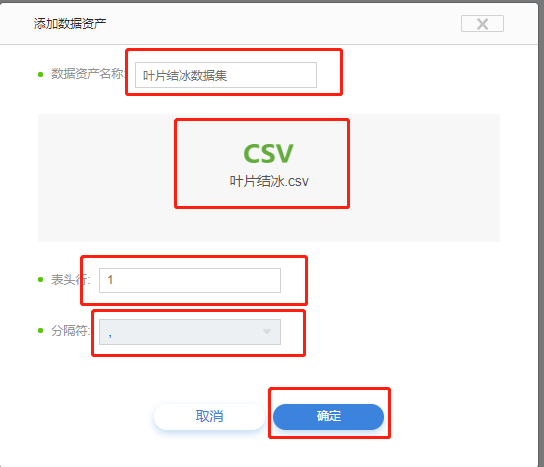
(2) 在【添加数据资产】页面中,填写【数据资产名称】,【选择数据文件】,【表头行】,【分隔符】参数,点击【确定】。
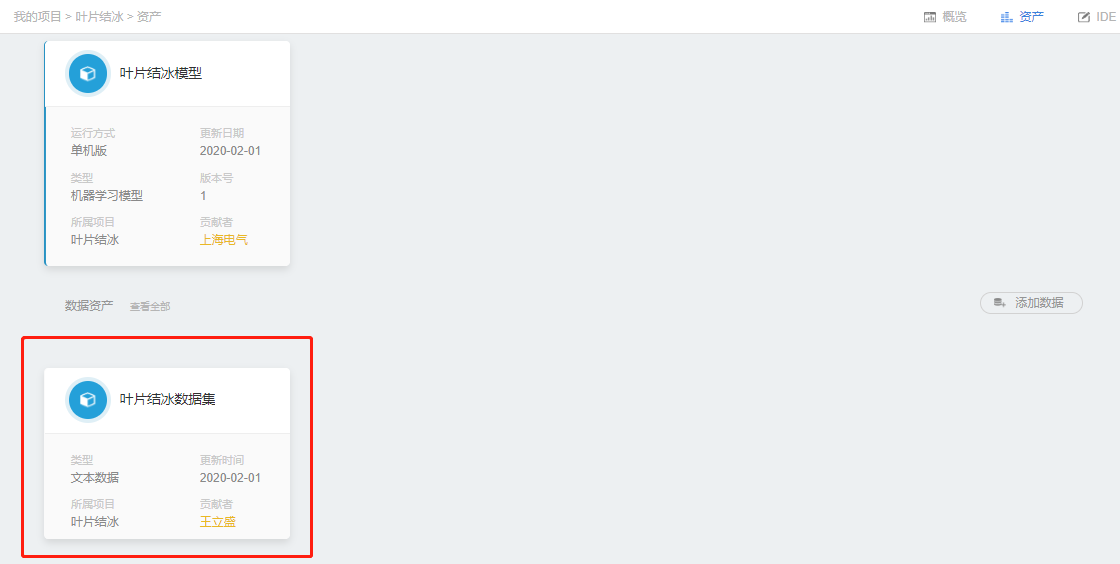
(3) 上传成功后在【项目资产】界面,即可看到上传的数据,点击【数据资产】,可以预览上传数据。
模型配置
建模分为五部分:数据读取、数据预处理、数据的特征工程、LSTM模型的训练、分类器模型的训练。首先对数据进行数据清洗、数据的归一化预处理,接着用K-means聚类对数据进行筛选,去除噪声数据和冗余数据,最后通过随机森林筛选出重要特征。预测模型采用了LSTM深度神经网络模型,通过训练历史数据,实现对未知数据的预测功能。最后将LSTM的预测数据通过预训练的多参数随机森林进行分类,从而预测未来时间段内设备的健康状态。
数据源配置
从【源/目录】目录中拖入【读数据表】组件,并进行配置。
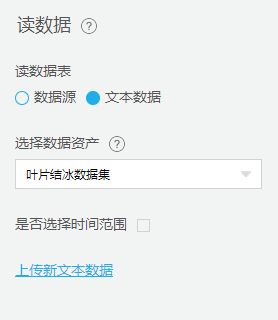
数据处理
从【数据预处理】中拖入【采样】、【缺失值填充】、【归一化】、【标准化】组件,配置相关参数。对数据进行标准化处理。
打标签
从【数据预处理】中拖入【打标签】组件,对故障码为927的数据进行数据标注。
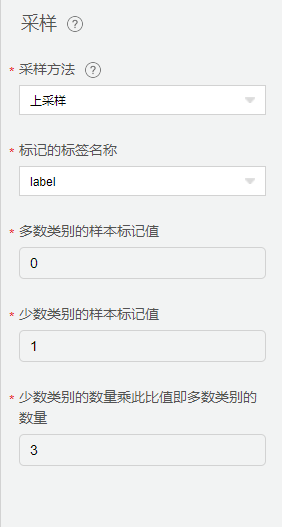
采样
由于采集数据中健康数据占比较多,而故障数据占比较小。会导致模型结果倾向于健康数据,训练效率低下和简单的负面样本引发整个模型表现不佳的问题。因此,我们采用【采样】,使用上采样的方式,控制健康数据与故障数据的数据比例。
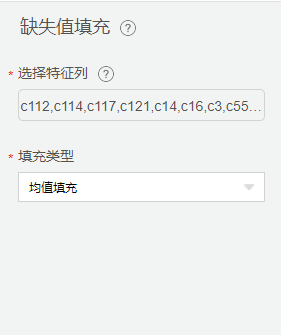
缺失值填充
采集数据中不可避免的会遇到某些特征出现空值的情况,这里我们使用【缺失值填充】用来将空值替换均值。
归一化
【归一化】主要作用���: 把数据变成(0,1)或者(0,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速的计算。
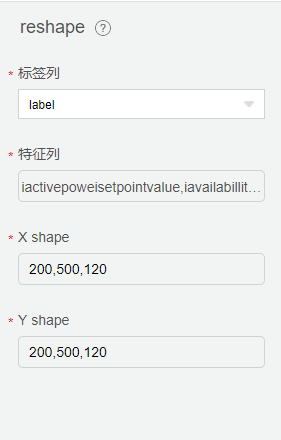
Reshape
数据用于深度学习需要做一个维度转换,在【reshape】中配置如下:
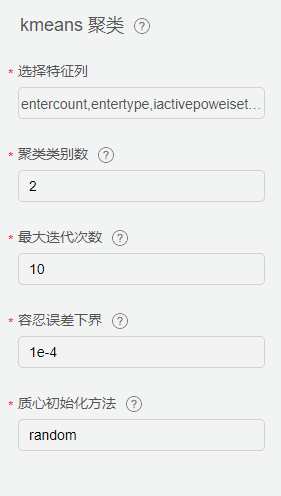
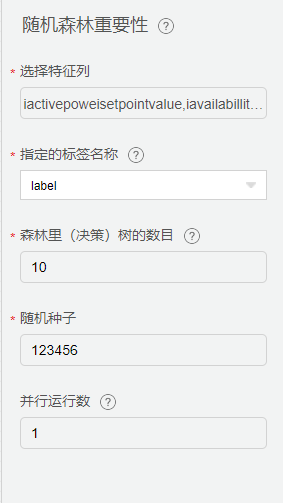
特征工程
从【特征工程】-【特征选择】中拖入【随机森林重要性】组件,从【机器学习】-【聚类】中拖入【kmeans聚类】配置相关参数。
针对不同设备的部件数据,筛选部分健康及故障发生次数较多的月份数据,生成特征工程所需的训练集。利用Kmeans自组织聚类的特征,选取多个聚类值K,将多次聚类时始终聚为一类的数据视为同类型数据,将数据行数记为X;若X较小,则代表此类数据在聚类过程中贡献值过小,即冗余数据,将其从训练集中剔除。将新的数据集通过随机森林,实现特征的重要性排名,筛选出重要特征。
分类器
从【机器学习】中拖入【随机森林分类】组件,配置相关参数。
实现过程:
(1) 从样本集(假设样本集N个数据点)中通过有放回的采样选出n个样本
(2) 对这n个样本训练分类器,重复1)-2)步骤m次,获得m个分类器,m个分类器组合生成一个随机森林模型
(3) 最后根据这m个分类器的投票结果,决定数据的类别。
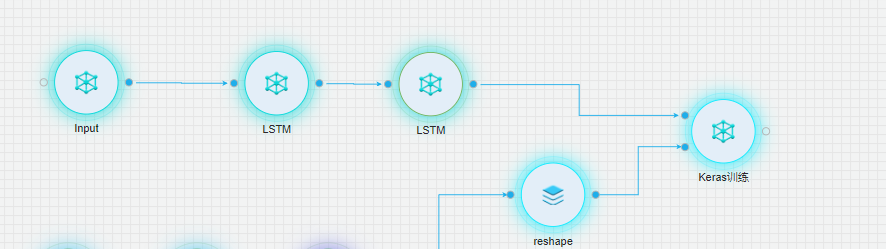
LSTM模型
从【深度学习】中拖入【Input】、【LSTM】、【LSTM】、【Keras训练】组件,配置相关参数。
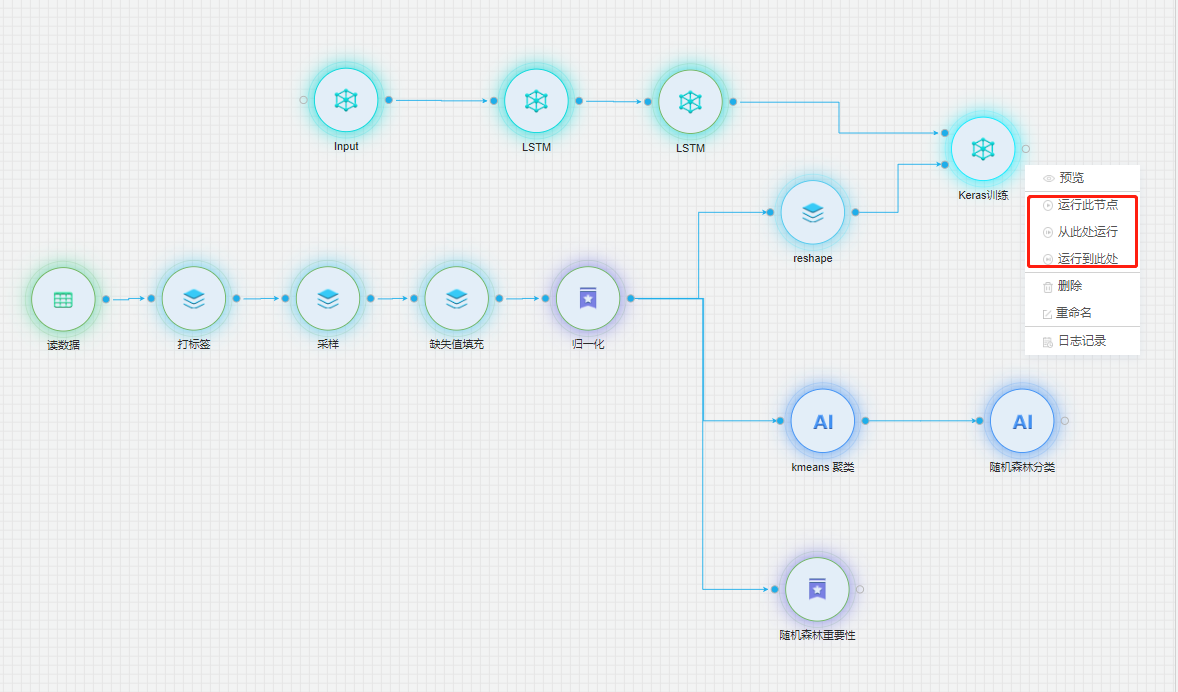
模型训练及评估
在【模型组件】右击,选择运行一种运行方式,组件可单独运行,也可按顺序依次执行。所有组件运行成功后,会自动生成模型文件。
在【模型类型组件】右击,点击【预览】-> 【图表展示】可以展示模型的评估信息。
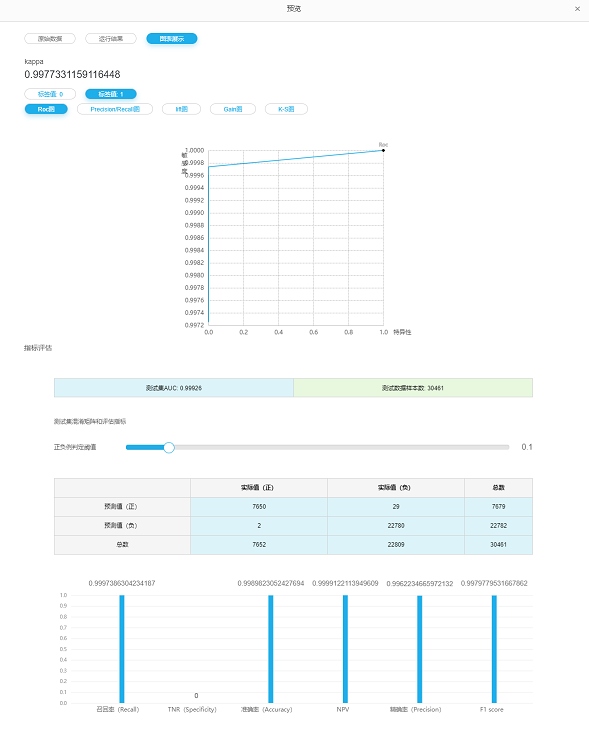
模型评估结果
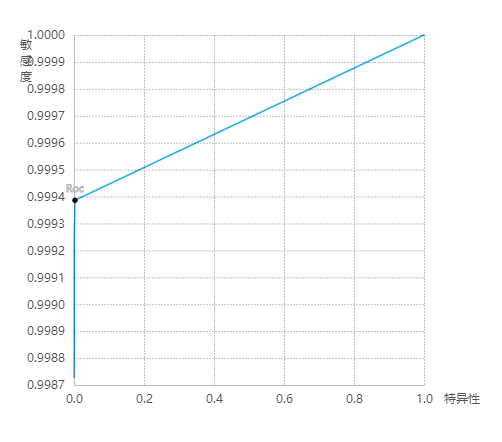
ROC曲线
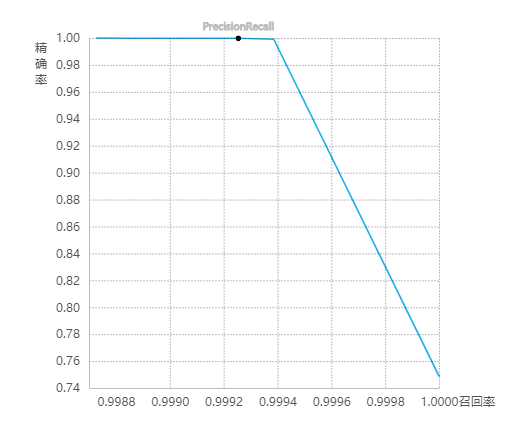
P-R图
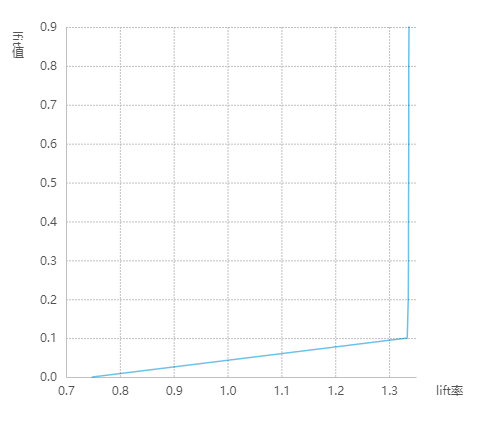
lift图
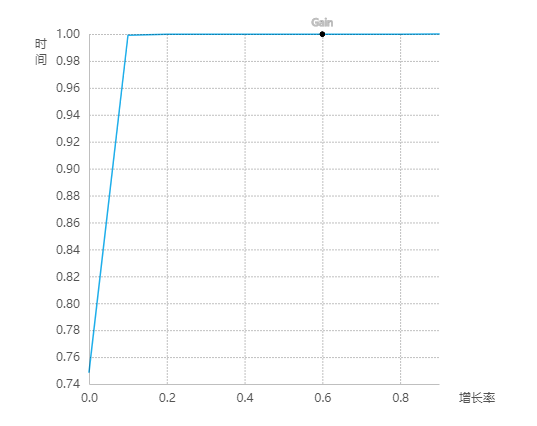
Gain图
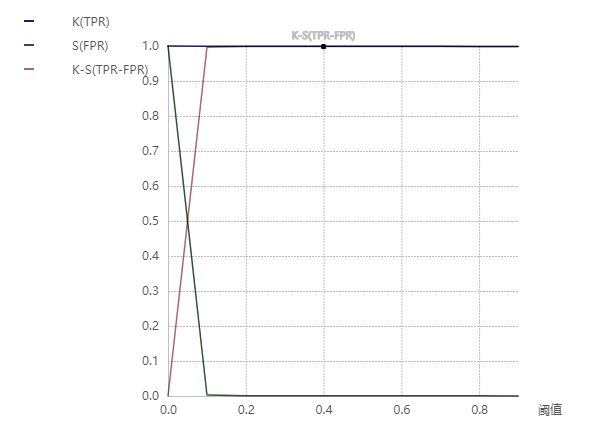
K-S图
模型发布及部署
鼠标单击左侧导航栏【模型管理】,选择【模型发布及部署】
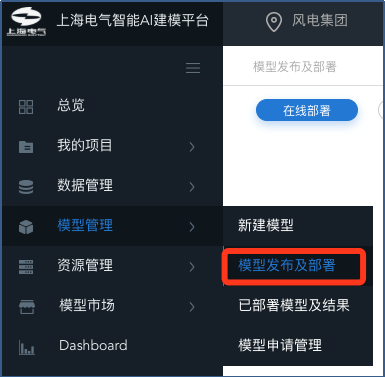
进入【模型发布及部署】页面选择发布类型【在线发布/Docker发布】,以及运行方式【单机/分布式】,单击【下一步】按钮进入【选择模型】页面。
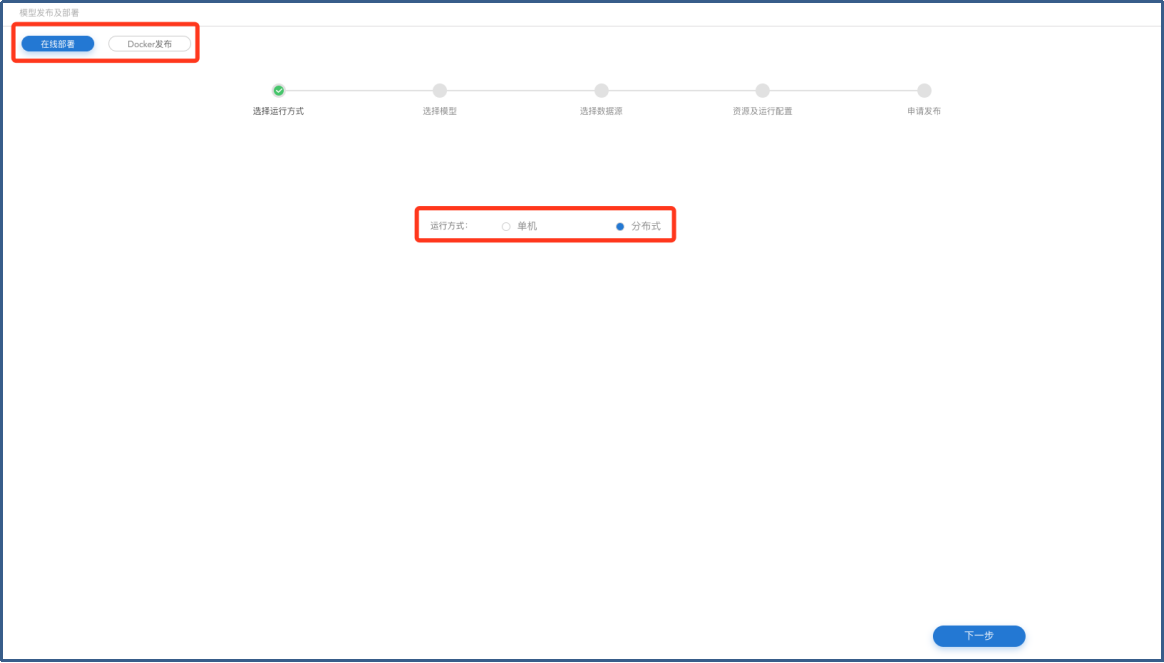
在【选择模型】页面,【项目】菜单中选择要发布的模型,并在【选择模型】页面勾选模型版本,单击【下一步】进入【选择数据源】页面。
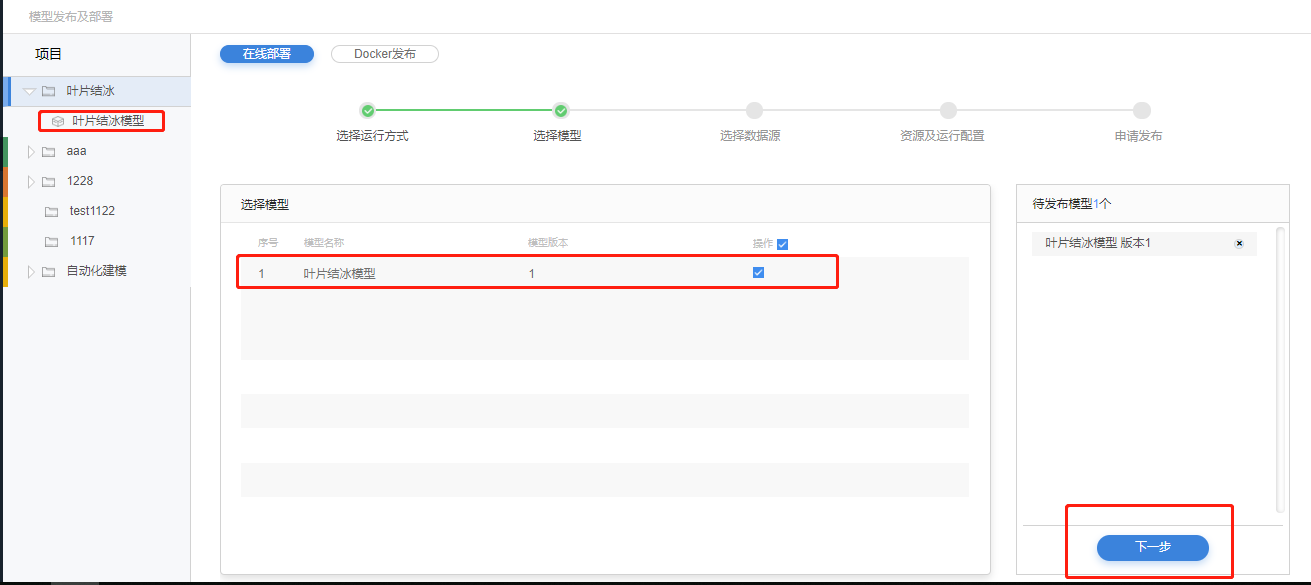
在【项目】菜单栏选择数据源,并在【选择数据源】页面勾选选择部署所需的数据,查看数据源信息,选择数据,点击下一步进入【资源及运行配置】。
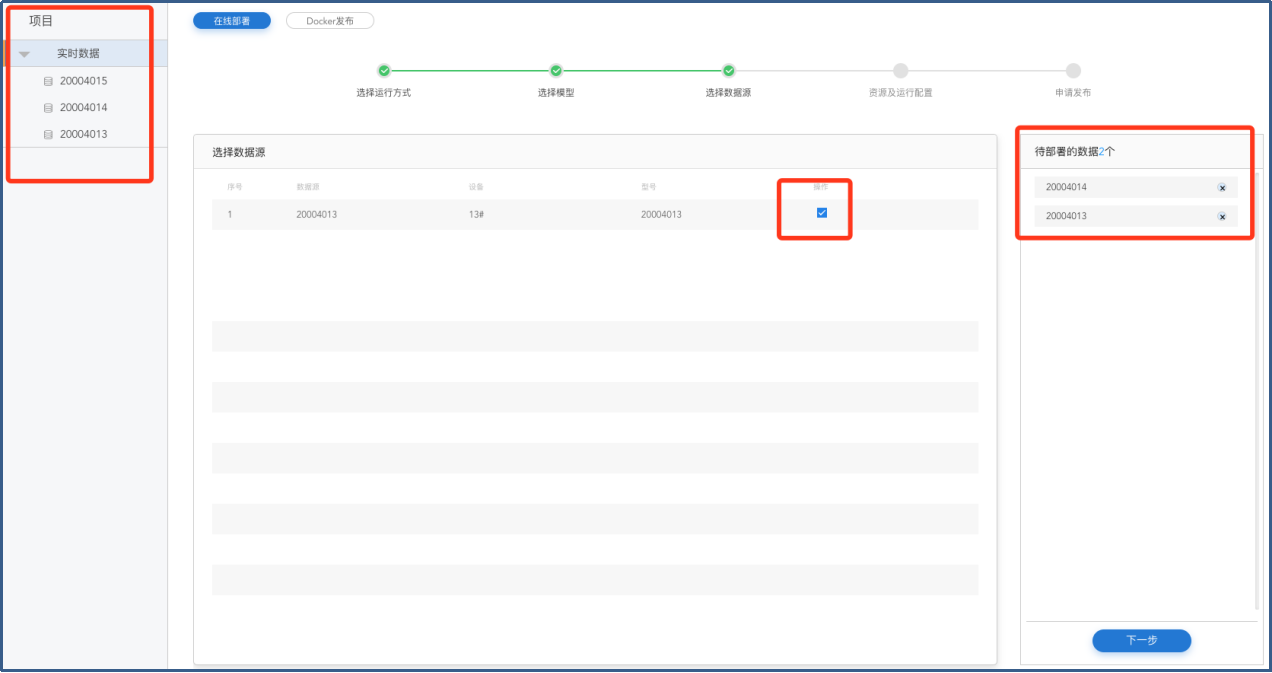
在【资源及运行配置】页面填写【运行配置】和【资源配置】,点击下一步进入【申请发布】页面。
在【申请发布】页面,填写【任务名称】、【描述】,点击【确定】。

点击【模型管理】,选择【模型申请管理】页面,可查看申请部署模型的情况。
模型审批通过后,可以在【已部署模型和预警】详情界面查看模型产生的预警及部署相关信息。

已部署模型及结果
鼠标单击左侧导航栏【模型管理】,点击【模型发布及部署】菜单,进入已部署模型【总览】页面。
在【已部署模型及结果总览】页面查看已部署模型统计及运行结果信息,点击【模型结果】/【已部署模型】进行页面切换。

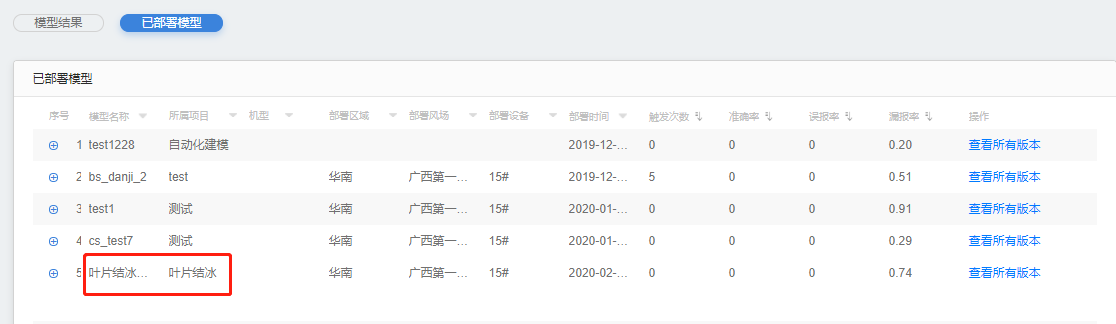
已部署模型
螺栓断裂
背景
螺栓连接是风力发电机组装配中的重要装配方式,几乎涉及到风力发电机组的所有部件。因此,螺栓的选用和强度校核是风力发电机组可靠性的重要保证。螺栓作为风电设备的重要联结件,由于其各特性的不确定性,成为风力发电机组设计过程中降低成本的主要难点之一。
本模型基于AI建模平台,创建风机螺栓断裂模型,希望可以通过模型运行结果,及时地预测螺栓的状态,更早地发出损坏警告。
数据集介绍
原始数据集为某风场某风机的数据。scada标记了故障发生时间和结束时间。
数据集数据字段如下(所有字段映射关系查看字段映射):
date,5min_avg_principal_axis_speed,5min_avg_wind_direction,5min_avg_30swind_speed,5min_avg_600swind_speed,5min_avg_principal_axis_temp,5min_avg_gen_driver_temp,5min_avg_gen_non-driver_temp,5min_avg_gen_winding_U_temp,5min_avg_gen_winding_V_temp,5min_avg_gen_winding_W_temp,5min_avg_space_temp,5min_avg_torque_set,5min_avg_tower_box_temp,5min_avg_wind_speed,5min_avg_space_box_temp,5min_avg_1#xvibrate,5min_avg_1#y_vibrate,5min_avg_2#x_vibrate,5min_avg_2#y_vibrate,System_OK,...,5min_distributor_out_pressure_max
其字段含义为:
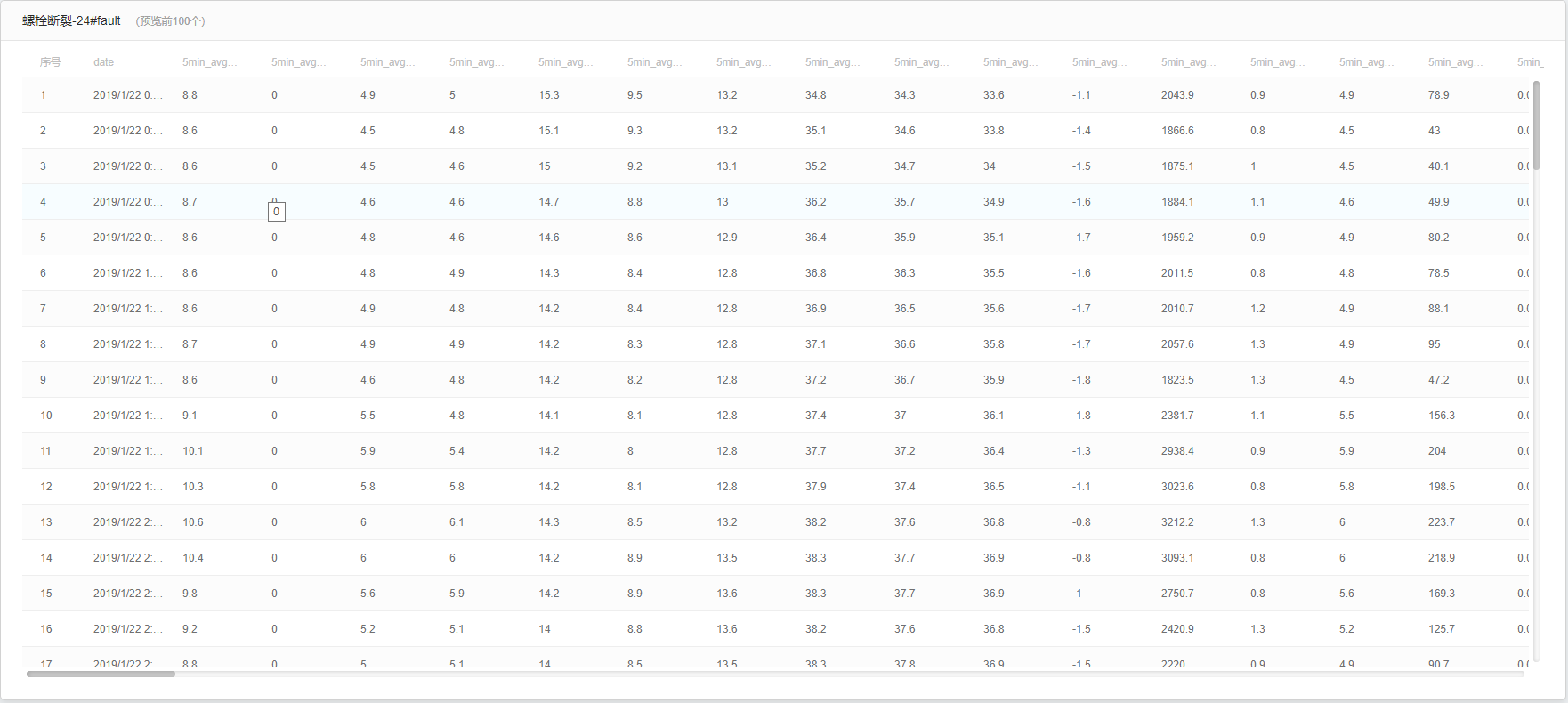
根据故障时间段筛选出所有故障中出现最多的故障做为故障数据,非故障数据作为健康数据。
数据集具体内容部分展示如下:
整体流程
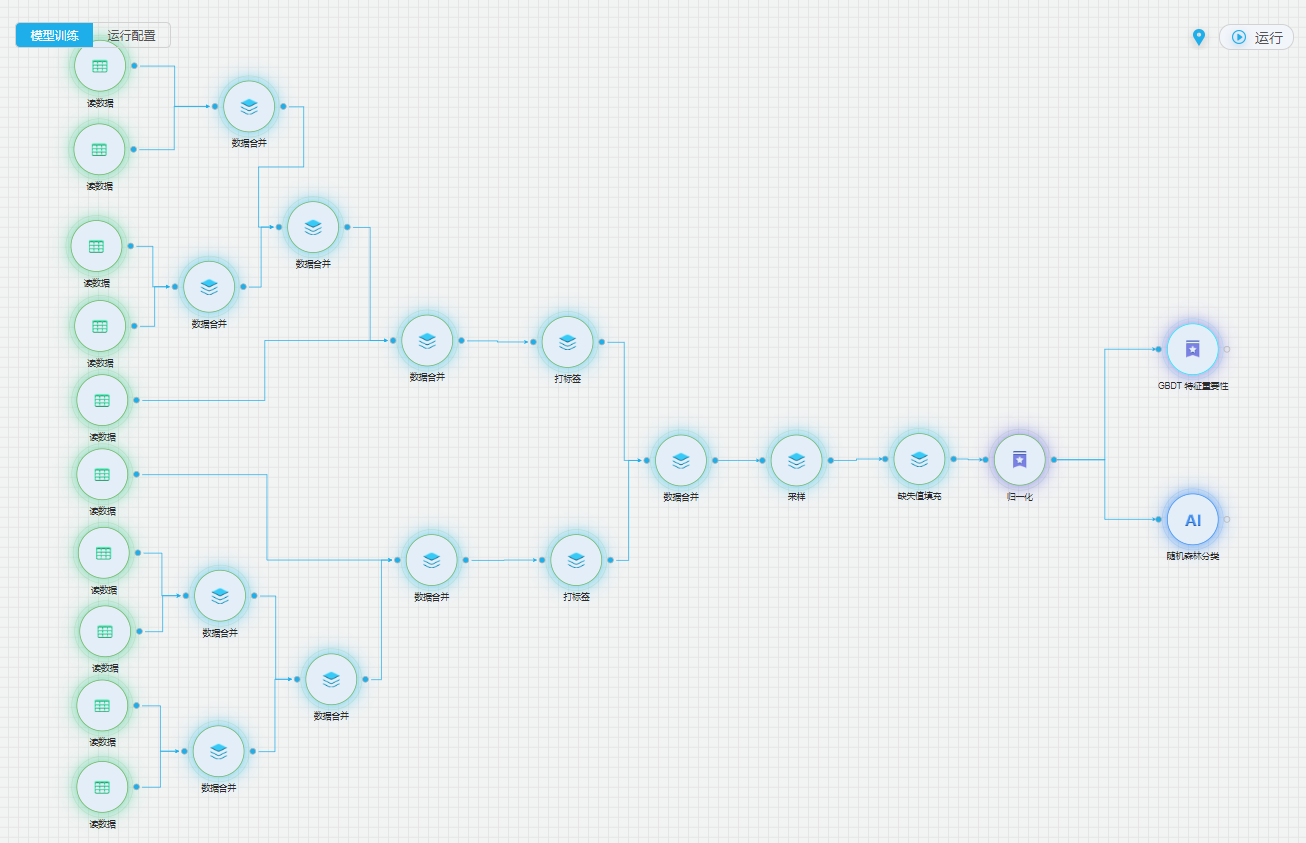
详细流程
通过结合数据挖掘和机器学习的模型,对设备的系统数据进行数据预处理,并建立对历史数据的Xgboost机器学习模型,致力于实现设备技术状态的多维关联分析,以及设备故障数据的提前预警。
模型配置
建模分为五部分:数据读取、数据预处理、数据的特征工程、Xgboost模型的训练。首先对数据进行数据清洗、数据的归一化预处理,接着用GBDT特征重要性选出重要特征。预测模型采用了Xgboost分类模型,通过训练历史数据,实现对未知数据的预测功能。
数据源配置
从【源/目录】目录中拖入【读数据表】、从【数据预处理】目录中拖入【数据合并】组件,并进行配置。依次拖入多个【读数据源】组件,分别配置对应的数据资产。并通过【数据合并】组件,将故障数据与健康数据分别两两合并,合并为一份故障数据和一份健康数据。
数据处理
从【数据预处理】中拖入【打标签】、【缺失值填充】、【归一化】、【采样】组件,配置相关参数。对数据进行标准化处理。
打标签
分别对健康数据和故障数据进行打标签,标签列名为label,健康数据标记为0,故障数据标记为1。
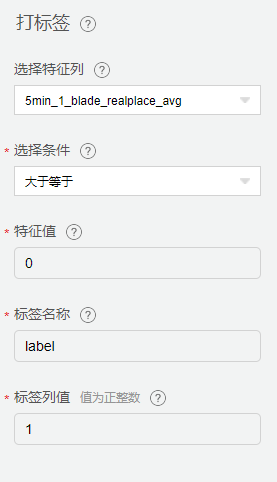
缺失值填充
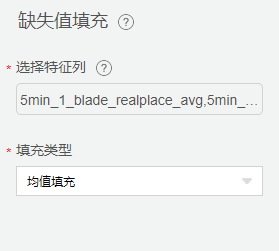
采集数据中不可避免的会遇到某些特征出现空值的情况,这里我们使用【缺失值填充】用来将空值替换均值。
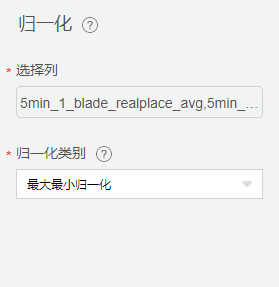
归一化
【归一化】主要作用是: 把数据变成(0,1)或者(0,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速的计算。
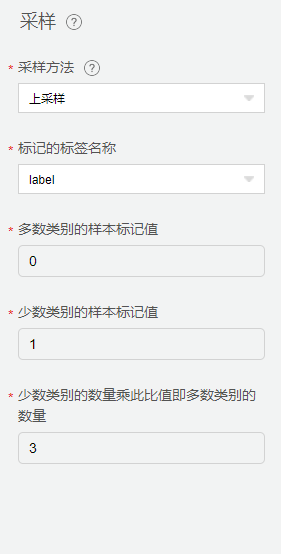
采样
由于采集数据中健康数据占比较多,而故障数据占比较小。会导致模型结果倾向于健康数据,训练效率低下和简单的负面样本引发整个模型表现不佳的问题。因此,我们采用【采样】,使用上采样的方式,控制健康数据与故障数据的数据比例。
特征工程
从【特征工程】-【特征选择】中拖入【GBDT 特征重要性】组件,配置相关参数。
将新的数据集通过GBDT 特征重要性,实现特征的重要性排名,筛选出重要特征。为后续模型组件特征列选择提供指导。
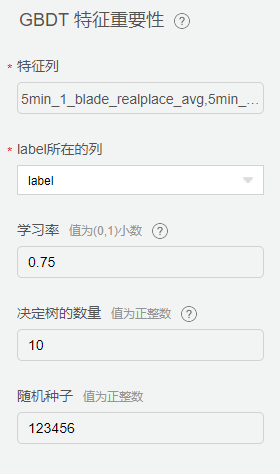
运行后结果如下:
分类器
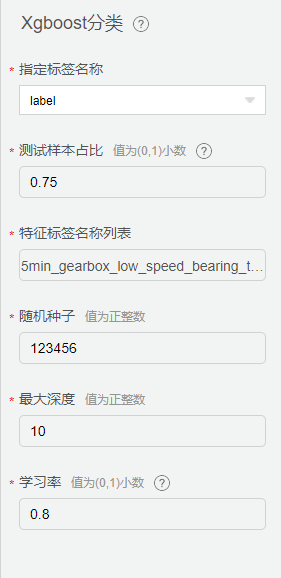
从【机器学习】中拖入【Xgboost】组件,配置相关参数。
Xgboost 分类优势
(1) 正则化项防止过拟合。 xgboost在目标函数中显示的加上了正则化项,基学习为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,正则化项防止过拟合。
(2) GB中使用Loss Function对f(x)的一阶导数计算出伪残差用于学习生成fm(x),xgboost不仅使用到了一阶导数,还使用二阶导数,损失更精确,还可以自定义损失。
(3) XGBoost的并行优化,XGBoost的并行是在特征粒度上的
(4) 考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率
(5) 支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
Xgboost 分类配置
配置【Xgboost 分类】组件,其中特征列选择随机森林重要性排名中权重大于1%的特征列。测试样本占比采用0.25,详细配置如下:
模型评估结果
ROC曲线
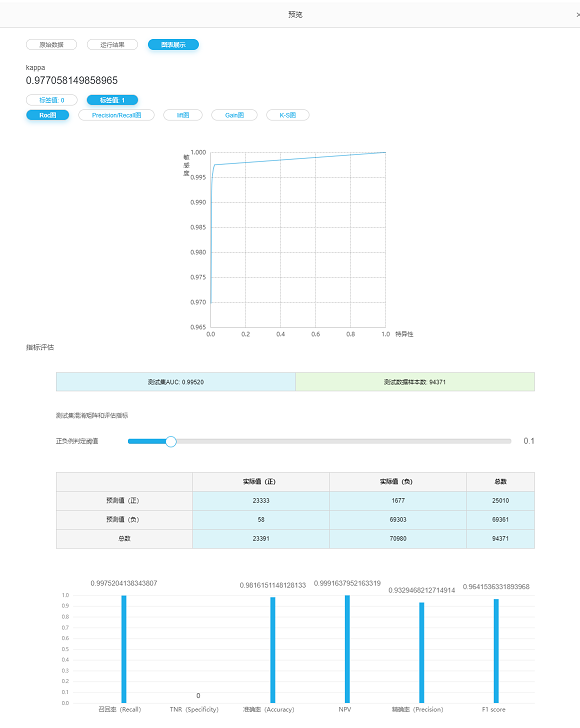
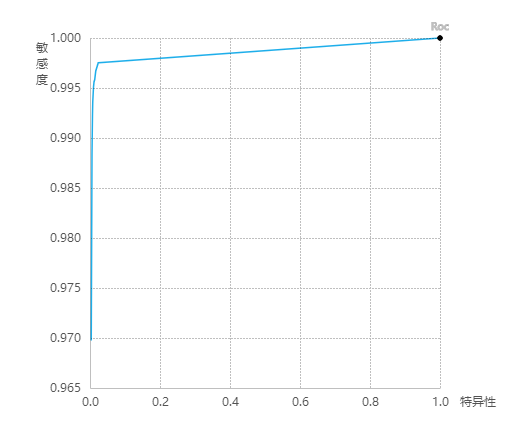
P-R图
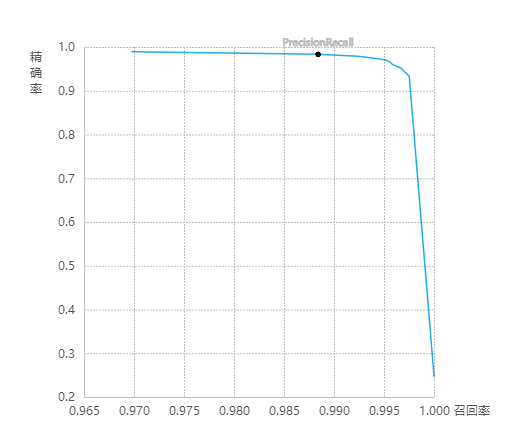
lift图
Gain图
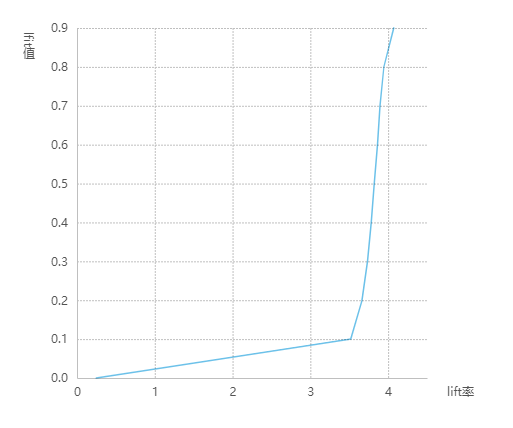
K-S图
模型发布与部署
鼠标单击左侧导航栏【模型管理】,选择【模型发布及部署】
进入【模型发布及部署】页面选择发布类型【在线发布/Docker发布】,以及运行方式【单机/分布式】,单击【下一步】按钮进入【选择模型】页面。
在【选择模型】页面,【项目】菜单中选择要发布的模型,并在【选择模型】页面勾选模型版本,单击【下一步】进入【选择数据源】页面。
在【项目】菜单栏选择数据源,并在【选择数据源】页面勾选选择部署所需的数据,查看数据源信息,选择数据,点击下一步进入【资源及运行配置】。
在【资源及运行配置】页面填写【运行配置】和【资源配置】,点击下一步进入【申请发布】页面。
在【申请发布】页面,填写【任务名称】、【描述】,点击【确定】。
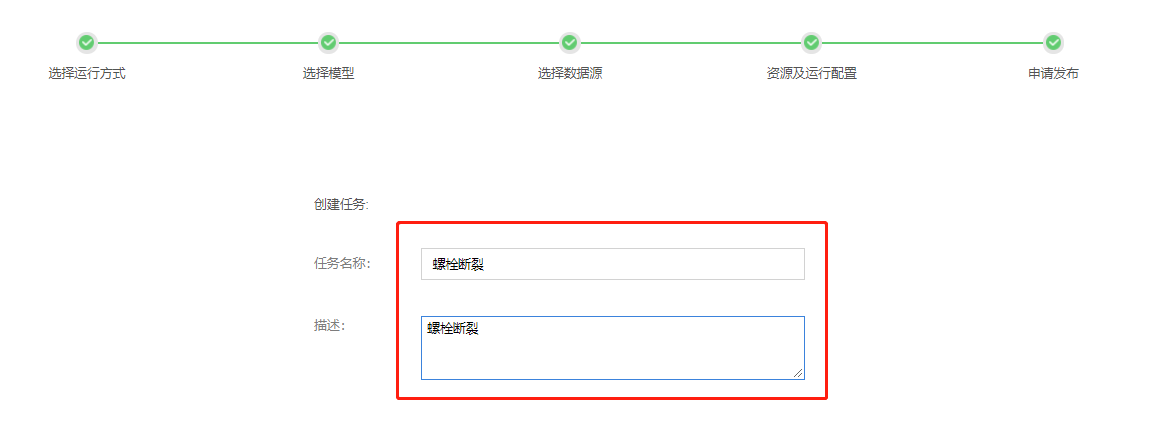
点击【模型管理】,选择【模型申请管理】页面,可查看申请部署模型的情况。
模型审批通过后,可以在【已部署模型和预警】详情界面查看模型产生的预警及部署相关信息。

已部署模型及结果
鼠标单击左侧导航栏【模型管理】,点击【模型发布及部署】菜单,进入已部署模型【总览】页面。
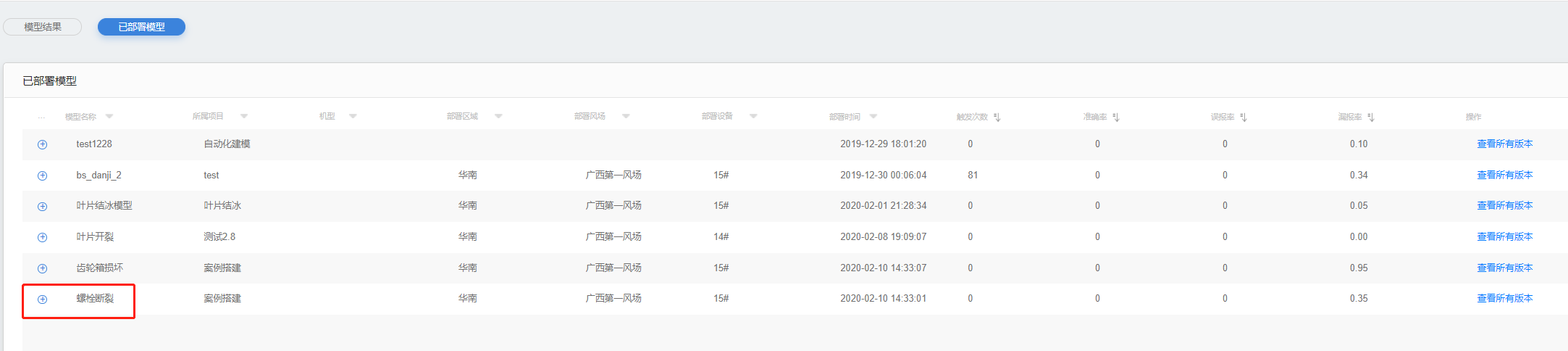
在【已部署模型及结果总览】页面查看已部署模型统计及运行结果信息,点击【模型结果】/【已部署模型】进行页面切换。

字段映射
Notebook&新冠预测
背景
在AI建模平台中,已有组件功能及逻辑相对固定,不能满足一些特定场景下的使用需求,因此我们推出了notebook来自定义组件的解决方案。AI建模平台内嵌了Jupter Notebook,支持在线进行二次开发,并对开发的程序文件进行封装,支持自定义组件与其他组件进行连线及数据传输,方便建模人员进行最小化开发,缩短开发周期,提高开发效率。
使用方法
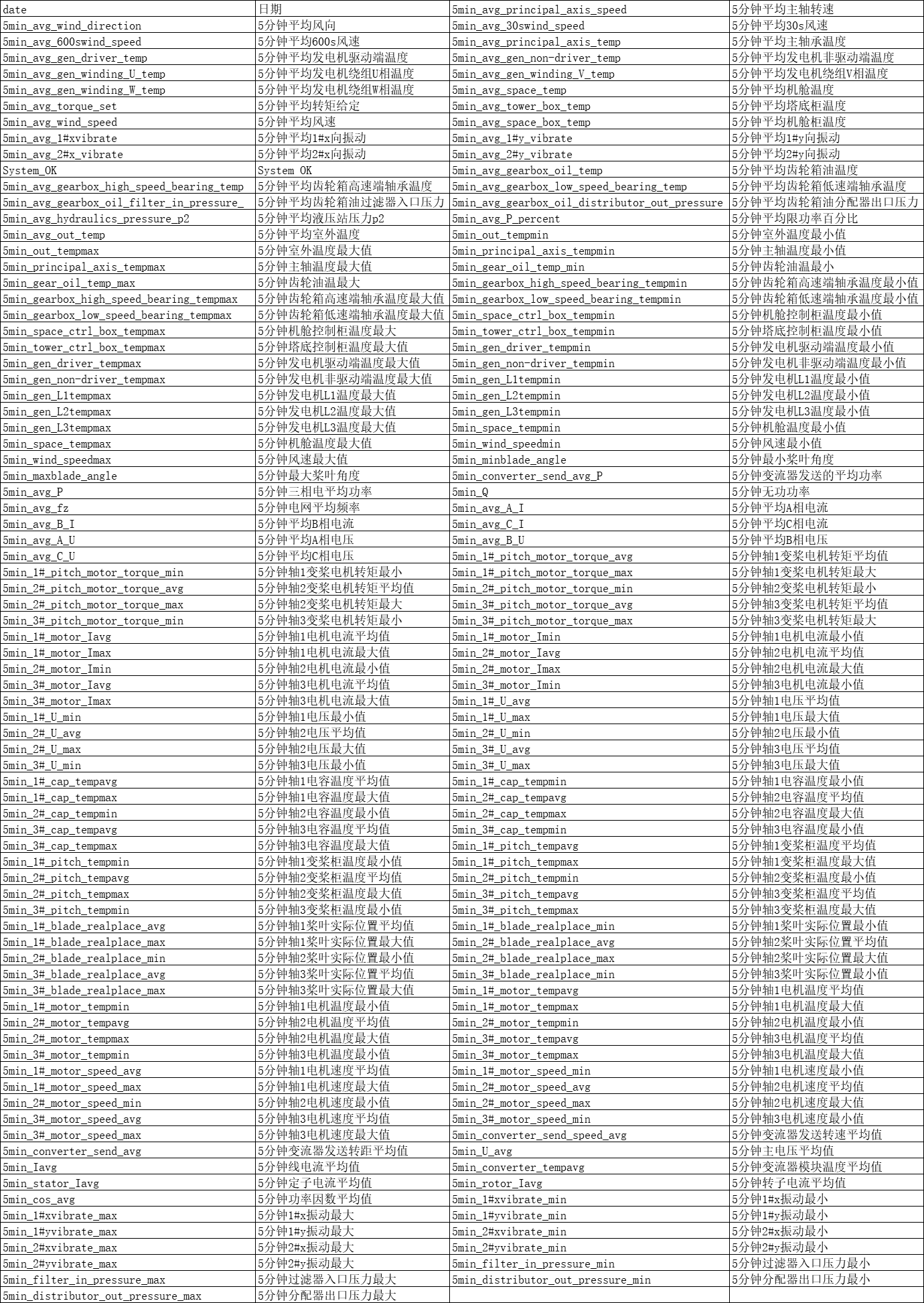
创建 notebook 组件
从【自定义组件】目录中,拖入【Notebook】组件。
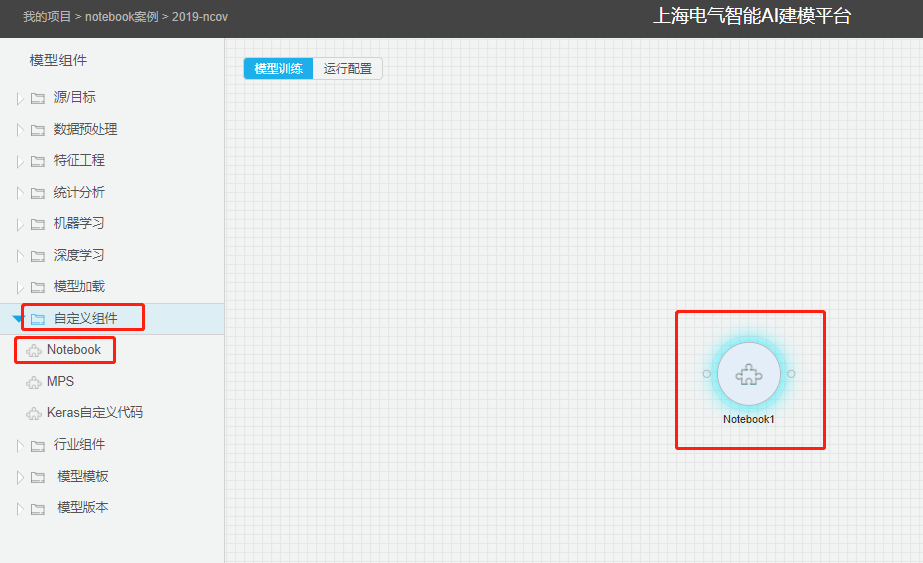
选择程序文件
单击Notebook组件,在**配置项**中选择已有的程序文件,可通过下拉框中的搜索按钮,输入关键字后快速搜索包含关键字的程序文件。
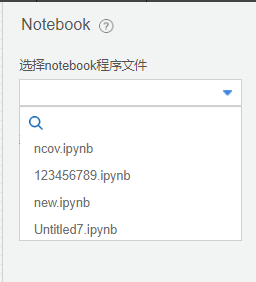
Notebook程序文件的管理
(1) 点击**配置项**中的“新建(New)”
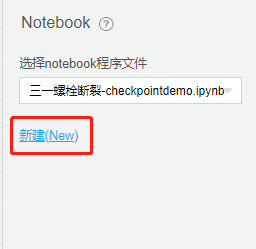
(2) 输入程序文件名称,并点击【确定】
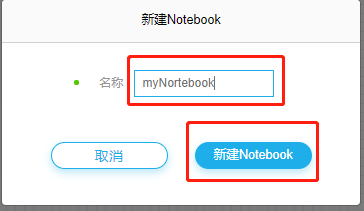
(3) 进入到notebook界面,所创建的notebook程序文件中提供了使用说明及常用的方法,详细说明见开发流程及注意事项。
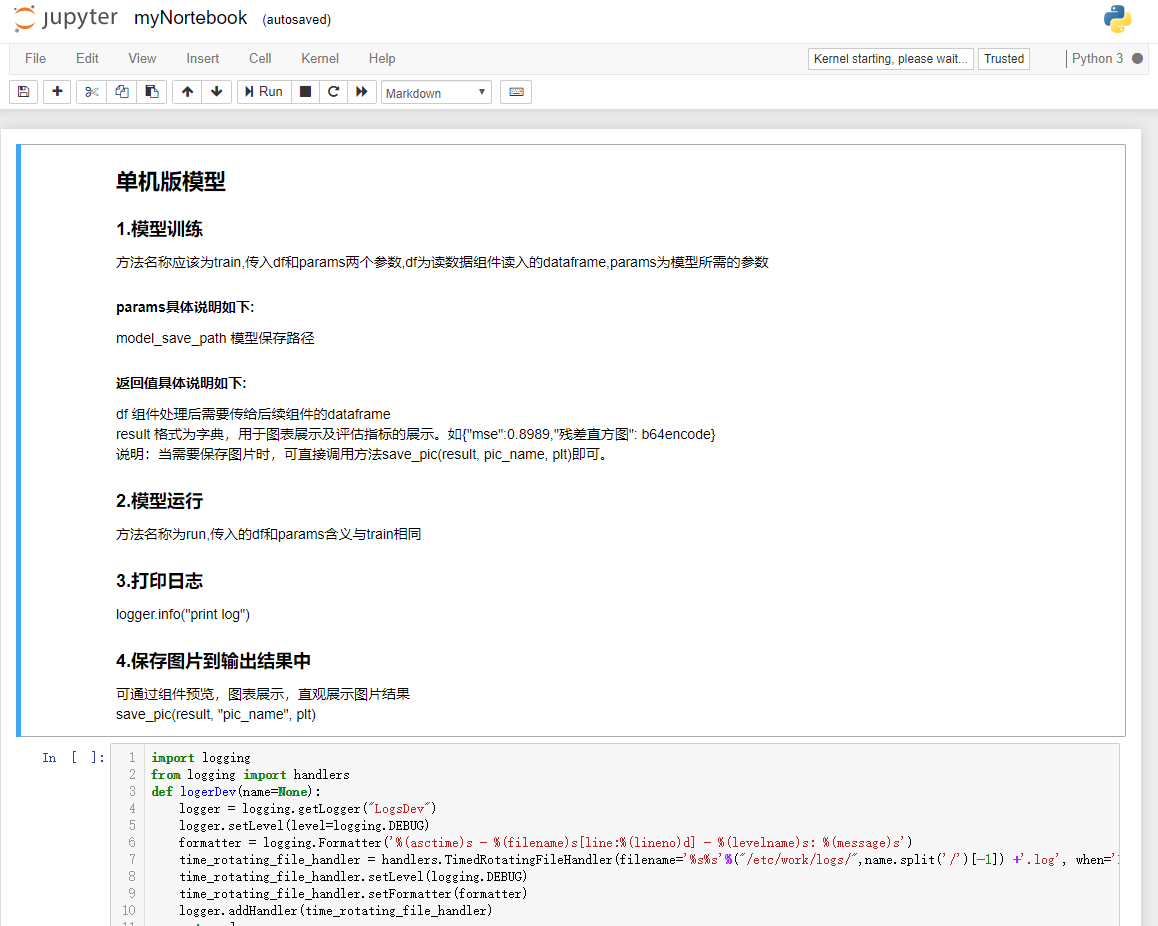
在程序文件下拉选择框中,鼠标悬停在需要修改的程序文件上时,出现修改及删除的图标,点击修改。
在程序文件下拉选择框中,鼠标悬停在需要删除的程序文件上时,出现修改及删除的图标,点击删除。
右击【notebook】,选择一种运行方式。

运行查看日志
右击【notebook】,点击日志记录。

输出输入结果查看
右击【notebook】,点击预览。

开发流程及注意事项
经过二次开发以后的notebook文件,我们期望将它封装为一个独立的组件,已达到最小化的开发目的。为此,我们制定了一些开发中相关的约束条件。
基本开发流程
通过【Notebook】组件**配置项**中【新建(New)】中创建的程序文件,已经包含了一些基本的使用说明及已有的方法。只需在其中填充相应的代码即可。
模型训练相关的代码写在train方法中,模型运行相关的代码卸载run方法中。
输入/输出
Notebook程序文件会经过平台的自动封装,对输入和输出自动处理:
输入
(1) 在建模界面中,【notebook】上游节点数据的输出
(2) 上游节点及本节点的一些参数,如本节点的id,名称,模型文件保存文件,模型文件名称等。
输出
(1) 输出数据文件存入到df中,自动传递给下游节点。
(2) 用于图表化展示的内容已字段的内容存入result中,支持评估指标及图片(需经过base64编码)。
方法及参数
train()
用于模型训练的代码如果,在训练过程中会自动调用该方法。
方法参数:
(1) df:notebook输入的dataframe。
(2) params: 传入的参数,类型: dict,id: 组件ID,name: 组件名称,model_save_path: 模型文件路径,model_name: 模型文件名称
说明:当需要保存图片时,可直接调用方法save_pic(result, pic_name, plt)即可。
run()
与训练方法一致
打印日志
已创建默认的日志实现,可以直接调用方法。如logger.info("print log")。
案列
背景
2020 年的春节假期,肆虐的新型冠状病毒伴随春运大军,从九省通衢的武汉悄然传遍了全中国。这场战“疫”,远比 17 年前的“非典”来得更凶猛,更加让人措手不及。在病毒传播过程中,挖掘疫情发展数据的内在规律,结合合理的理论模型进行预测,能够为疫情防控提供有价值的参考。科学客观地评估新冠肺炎的传染性强弱以及预测患病人数规模和峰值时间,对决策者实施必要的防控措施、评估对经济的影响以及投资者如何应对都具有重要的现实意义。
本案例通过notebook自定义组件,实现了“SEIR”传染病模型。SEIR是经典的流行病传播模型,SEIR模型将整个社群人口分为四类:
(1) 易感人群S类:对该病毒没有抗体,接触传染期人群可能被传染;
(2) 潜伏期人群E类:被感染后处于潜伏期的人群,还没有传染性,平均时长记为TE;
(3) 传染期人群I类:代表潜伏期之后已具有传染性的人群,传染期的平均时长为TI;
(4) 隔离态人群R类:治愈并获得免疫或被有效隔离或死亡,既不能传染他人也不能被传染。
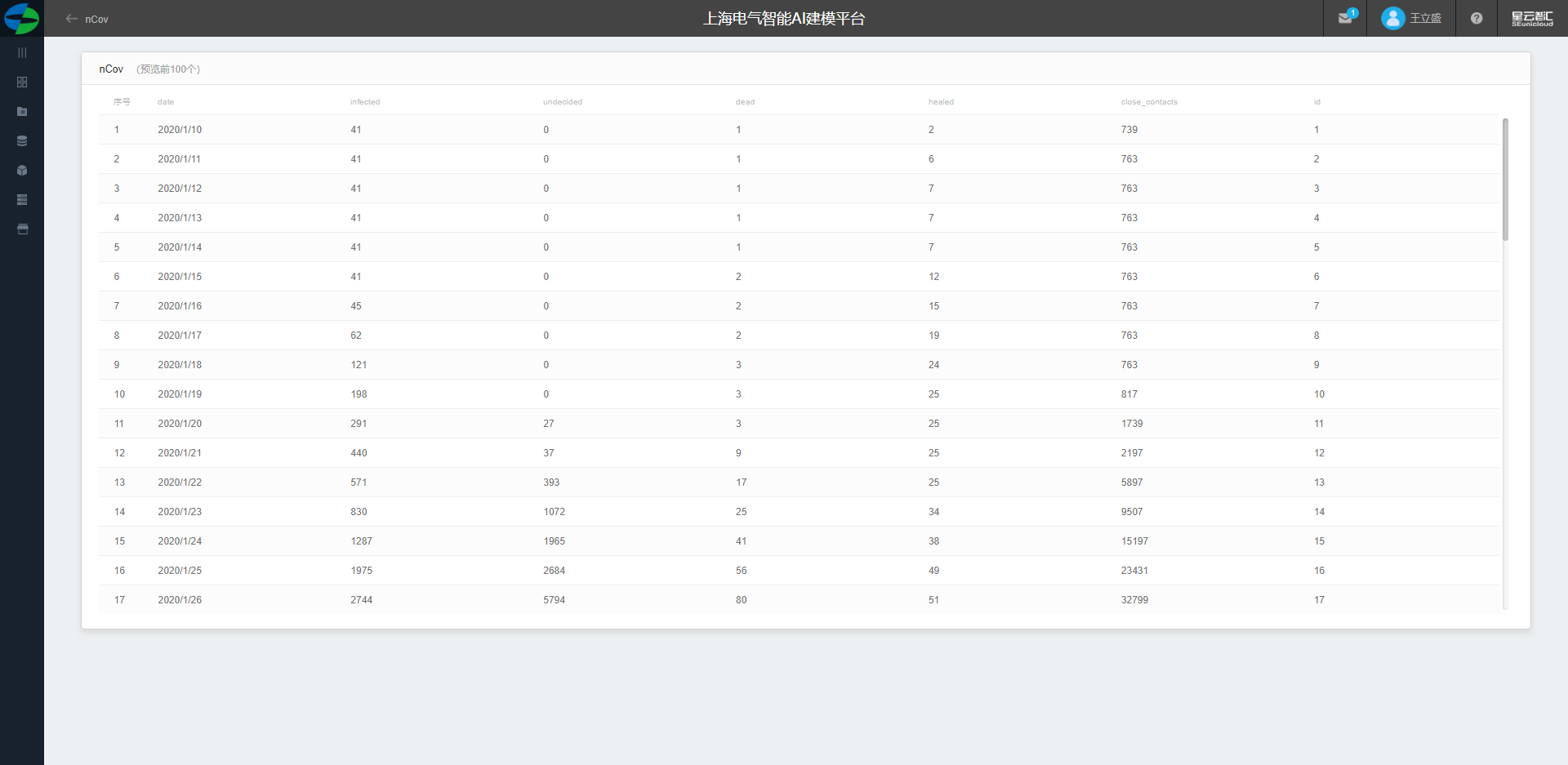
数据集介绍
原始数据集为国内卫检委公布的1.20-3.14日的相关数据,数据集数据字段如下:
数据集具体内容部分展示如下:
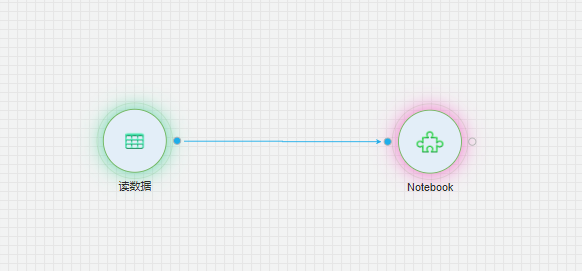
整体流程
首先我们通过读数据组件将数据读入
通过notebook实现SEIR模型
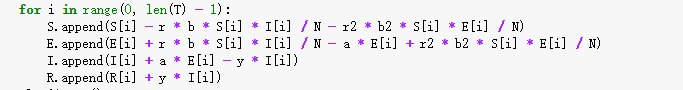

目标识别
背景
目标识别(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的位置和大小。由于各类物体有不同的形状、大小和数量,加上物体间还会相互遮挡, 因此目标检测一直都是机器视觉领域中最具挑战性的难题之一。现阶段,主流算法中表现最好的是SSD和YOLO,前者就是本文要用到的算法。我们AI平台中采用的SSD目标检测算法。
数据集介绍
数据集是VOC数据集,VOC为图像识别和分类提供了一整套标准化的优秀的数据集,其中重要文件夹有Annotations、ImageSets和JPEGImages。
(1) JPEGImages文件夹中包含了所有的图片信息,包括了训练图片和测试图片,这些图像都是以“年份_编号.jpg”格式命名的。图片的像素尺寸大小不一,但是横向图的尺寸大约在500375左右,纵向图的尺寸大约在375500左右,基本不会偏差超过100。(在之后的训练中,第一步就是将这些图片都resize到300300或是500500,所有原始图片不能离这个标准过远。)
(2) Annotations文件夹中存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片。
(3) ImageSets存放的是不同类型的图像数据。在ImageSets下有四个文件夹:
①Action下存放的是人的动作(例如running、jumping等等)
②Layout下存放的是具有人体部位的数据(人的head、hand、feet等等)
③Main下存放的是图像物体识别的数据,总共分为20类。
④Segmentation下存放的是可用于分割的数据。
建模流程
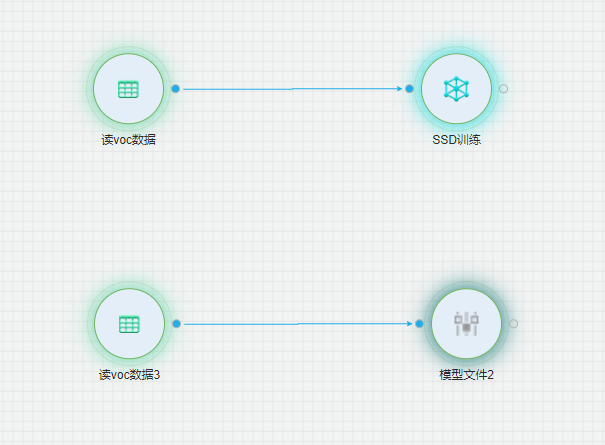
整体流程
(1) 首先我们将VOC数据集上传至数据资产。
(2) 通过读VOC组件将组件读入。
(3) 通过SSD组件进行训练。
(4) 通过模型文件加载验证SSD效果。
算法原理
(1) 将输入图片进行分辨率大小调整(300x300),将其输入到预训练好的分类网络中来获得不同大小的特征映射,修改了传统的VGG16网络;
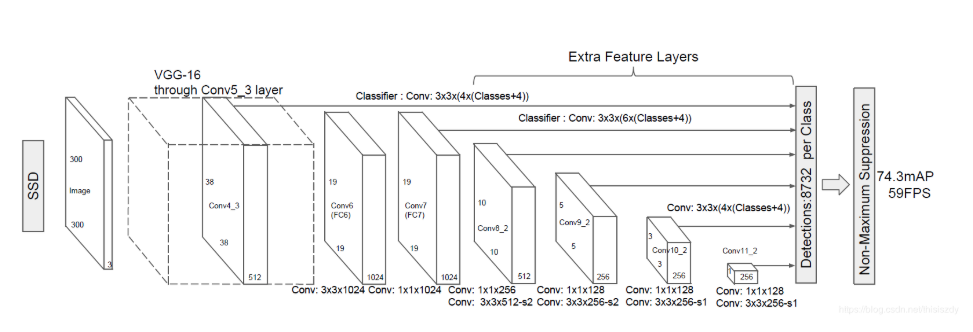
①将VGG16的FC6和FC7层转化为卷积层,如图上的Conv6和Conv7;
②去掉所有的Dropout层和FC8层;
③添加了Atrous算法(hole算法);
④将Pool5从2x2-S2变换到3x3-S1;
(2) 抽取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2层的feature map,然后分别在这些feature map层上面的每一个点构造6个不同尺度大小的bbox,然后分别进行检测和分类,生成多个bbox,如图所示:
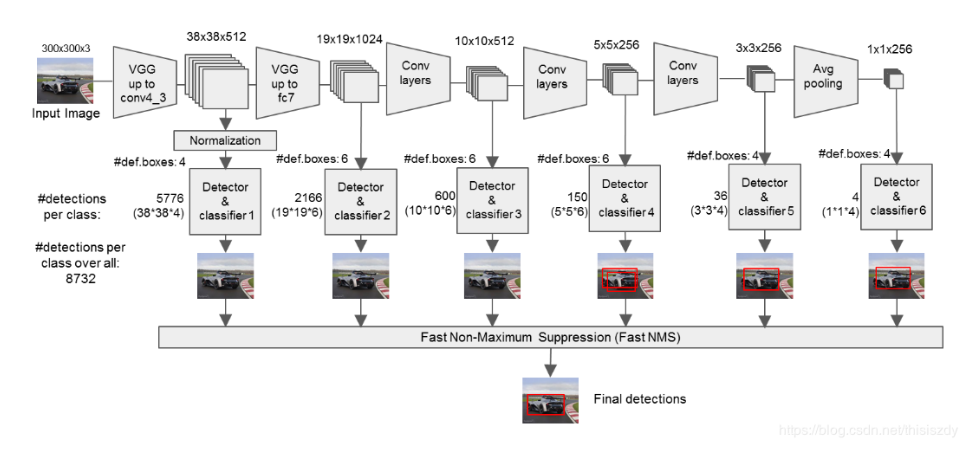
(3) 将不同feature map获得的bbox结合起来,经过NMS(非极大值抑制)方法来抑制掉一部分重叠或者不正确的bbox,生成最终的bbox集合(即检测结果);
组件配置
SSD训练配置
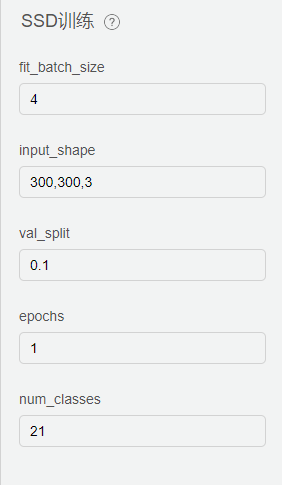
fit_batch_size: 训练批次的数量
input:shape: 输入图片预处理:300,300,3,表示分辨率 300 * 300,3表示为彩色图片。
val_split: 训练的比例
epochs: 为向前和向后传播中所有批次的单次训练迭代。这意味着1个周期是整个输入数据的单次向前和向后传递。简单说,epochs指的就是训练过程中数据将被循环多少次。
num_classes: 输入图片中类别树。
模型文件配置
模型文件选择SSD训练即可
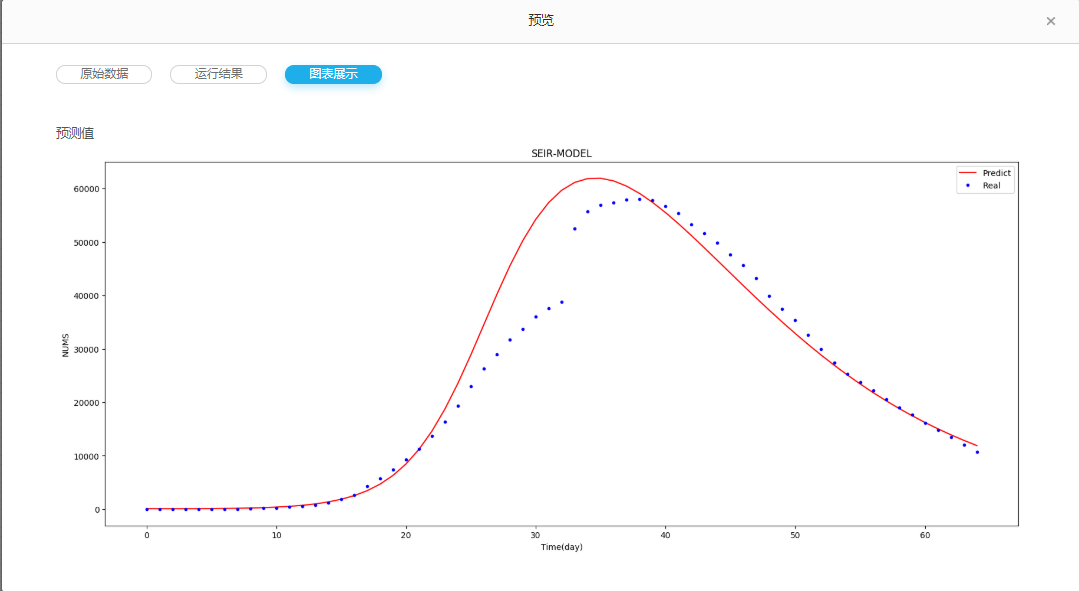
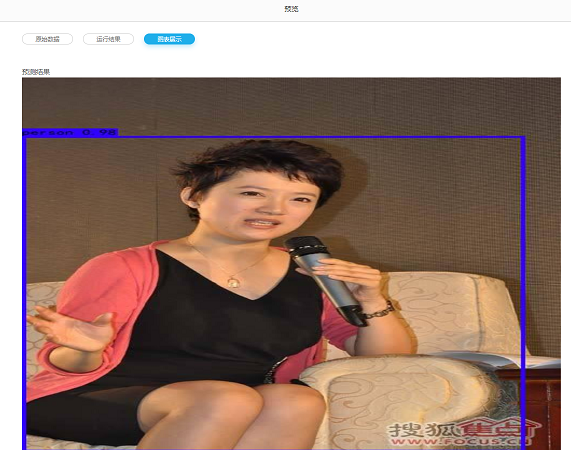
验证结果
输入图片:

识别结果:
光伏电场灰尘监测
摘要
摘要:提出了一种评估积灰对光伏组件发电性能影响的有效方法及其数学模型。该模型通过监测光伏发电汇流箱组串电流,建立了输出功率曲线聚类模型,从理论上说明光伏组件表面积灰对发电效率的影响。
背景
大型光伏电站一般建设在气候环境比较恶劣的地区,这些地区常干旱缺水,风沙严重。这些恶劣的环境因素对光伏组件发电效率产生影响,尤其是长时间的风沙导致尘土等污浊物遮挡光伏组件,影响光线的透射率,进而影响组件表面接受到的辐射量。同时,由于这些污浊物距离光伏电池片的距离很近,会形成阴影,并在光伏组件具备形成热斑效应。如果长时间不及时对光伏组件进行清洁,将会大幅度降低光伏电站发电量,不仅不能满足电网的要求,而且还降低了光伏发电系统的利用率。
数据集介绍
原始数据集江苏盐城某光伏发电厂5月1日至5月31日汇流箱光伏区_HWNBQ-1HLX1,组串1~16,30毫秒电流数据,数据集数据字段如下:
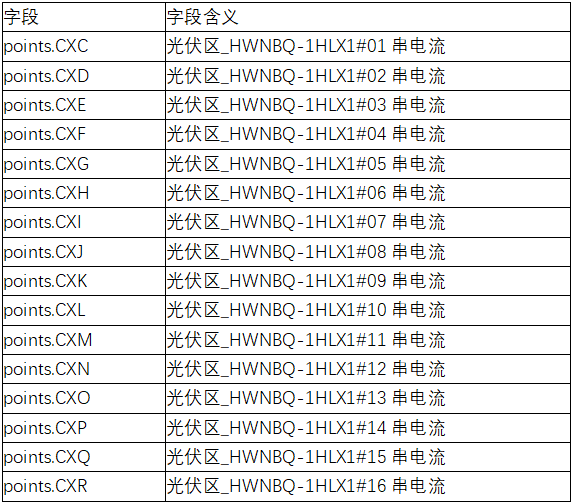
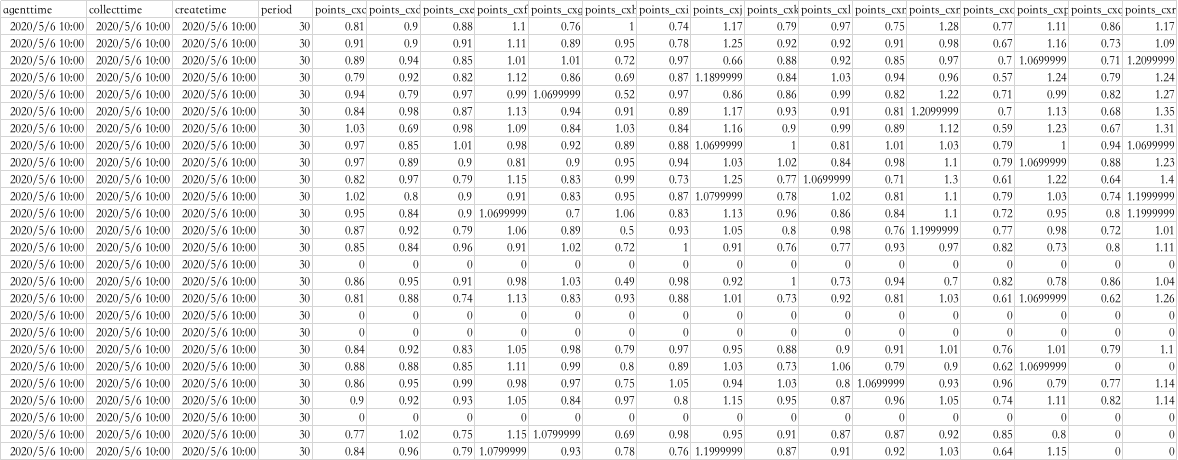
数据集具体内容部分展示如下:
建模思路
(1) 由于数据为无标注数据,考虑使用无监督机器学习模型。按照光伏组件积灰程度分为正常、积灰、严重积灰3个类别,拟使用聚类算法建立模型。
所有光伏组件是完好的;
所有光伏组件所处的环境完全相同,即在不考虑积灰的情况下,所有光伏组串在相同时间内的输出功率的完全相同的;
由于光伏组串是并联接入汇流箱,所有的光伏组串的汇流箱电压相等。所以本模型使用一天的电流和代替发电功率:
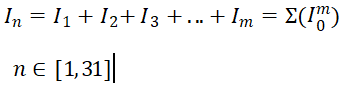
(3) 然后以光伏组串的31天每天的输出功率作为特征参数,对1~16号光伏组串进行聚类,类别数为3。
建模流程
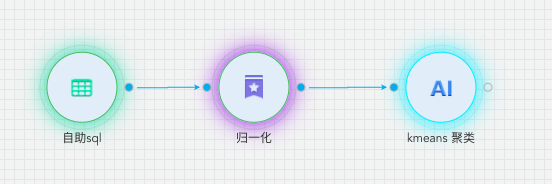
(1) 训练数据放在数据中台,hive数据库中:demo.hlx
(2) 使用【源/目标】下的【自助SQL】组件,读取数据,并对数据进行预处理。对1~16号光伏组串按照5月1日至5月31日每天的电流求和,自助SQL中SQL代码如下:

(3) 经过数据处理后,输出数据格式如下:
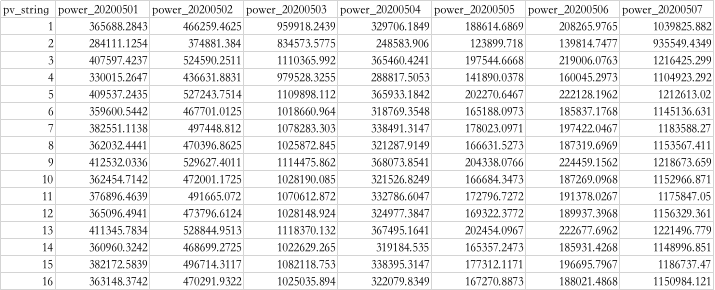
(4) 对数据归一化进行预处理,以保证每个特征被分类器平等对待。
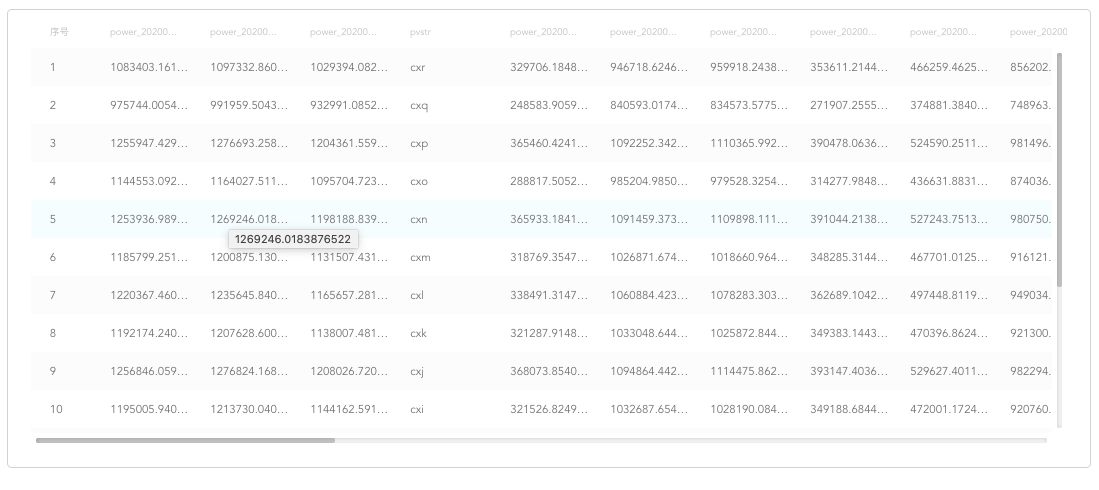
(5) 将处理后的数据输入聚类组件,按照输出功率对16个光伏组串进行聚类。
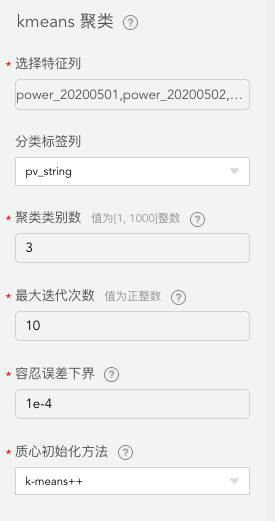
(6) 聚类结果如下:
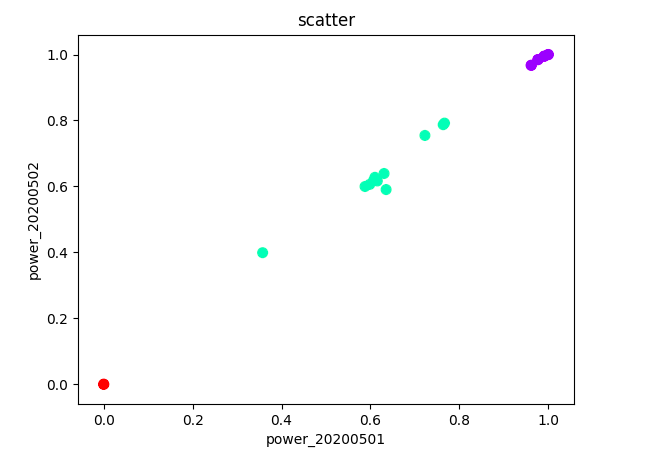
结论
本模型通过对盐城汇流箱光伏组串电流数据的聚类分析,可以看出光伏组件表面积灰是影响光伏组件输出性能的重要因素,并由此得到以下结论。
(1) 光伏组件表面积灰是长期存在的普遍现象,光伏组件表面积灰能够引起组件的转换效率降低。
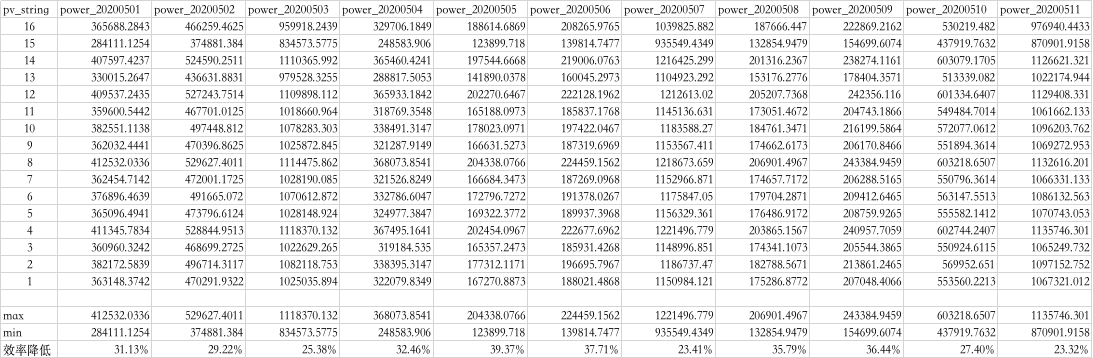
模型聚类结果中类别2的组串15,在天气晴好的时候,发电效率比正常组串降低约25~30%%。在一般天气情况下,发电效率比正常组串降低约35~40%。
说明灰尘引起组件发电性能降低的更深层次原因在于降低了光伏组件的透光性,在相同辐照度条件下,对于大规模光伏电站造成的功率损失会很大。
(2) 自然天气条件下光伏组件在积灰初期发电量受灰尘的影响较大,当灰尘累积到一定程度时,光伏组件发电量受积灰的影响将会趋于平稳,根据组件积灰的这种特性选择清洁时机,指导今后的光伏电站维护。
视频教程
模型部署
螺栓断裂
齿轮箱故障
储能案列
叶片结冰
目标识别
光伏灰尘检测聚类模型
图像分类说明
if classification == 0:
prediction = "cat"
elif classification == 1:
prediction = "dog"
当用户在平台中训练完模型(.h5文件)之后,用户可以使用自己的图片对其进行验证。验证的步骤如下:
(1) 把附录的代码模板复制到python文件中。
(2) 修改所需要加载模型的路径。
------附录对应代码为:model = load_model("/AIproject/catordog5.h5")
(3) 将所需要验证的图像集(jpg格式)保存到固定的文件夹里,用户根据自己的路径修改代码。
(4) 根据图像的种类修改代码。由于模板中对应的是猫狗分类,用户可根据需求修改代码中的标签信息。
------附录对应代码为:
(5) 修改完成之后,用户可以运行python代码并得到图像集的分类结果。
模板云心结果如下:

附录
from keras.models import load_model
import cv2
import numpy as np
import glob
def writeResultOnImage(openCVImage, resultText):
ToDo: this function may take some further fine-tuning to show the text well given any possible image size
SCALAR_BLUE = (255.0, 0.0, 0.0)
imageHeight, imageWidth, sceneNumChannels = openCVImage.shape
choose a font
fontFace = cv2.FONT_HERSHEY_TRIPLEX
chose the font size and thickness as a fraction of the image size
fontScale = 4.0
fontThickness = 3
make sure font thickness is an integer, if not, the OpenCV functions that use this may crash
fontThickness = int(fontThickness)
upperLeftTextOriginX = int(imageWidth * 0.05)
upperLeftTextOriginY = int(imageHeight * 0.05)
textSize, baseline = cv2.getTextSize(resultText, fontFace, fontScale, fontThickness)
textSizeWidth, textSizeHeight = textSize
calculate the lower left origin of the text area based on the text area center, width, and height
lowerLeftTextOriginX = upperLeftTextOriginX
lowerLeftTextOriginY = upperLeftTextOriginY + textSizeHeight
write the text on the image
cv2.putText(openCVImage, resultText, (lowerLeftTextOriginX, lowerLeftTextOriginY), fontFace, fontScale, SCALAR_BLUE, fontThickness)
# end function
# dimensions of our images
model=load_model('/AIproject/catordog5.h5')
#model.load_weights('models/checkpoints/weightsAdam32.h5')
#model.summary()
#images= glob.glob("/BaiduNetdiskDownload/dogandcat/new-test/*.jpg")
images= glob.glob("/AIproject/pet_train/cat/*.jpg")
for i in images:
image = cv2.imread(i)
imgr = cv2.resize(image, (64, 64))
img = np.reshape(imgr, [1, 64, 64, 3])
classes = model.predict(img)
classification=np.argmax(classes)
cv2.namedWindow('Prediction',cv2.WINDOW_NORMAL)
cv2.resizeWindow('Prediction', 500,500)
print(classes)
print(classification)
prediction=''
if classification==0:
prediction='cat'
elif classification==1:
prediction='dog'
writeResultOnImage(image,prediction)
cv2.imshow('Prediction', image)
cv2.waitKey(0)
cv2.destroyAllWindows()